高并发系统一定要考虑的 Bloom Filter 布隆过滤器
2020/4/30 8:02:38

本文主要是介绍高并发系统一定要考虑的 Bloom Filter 布隆过滤器,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
开篇思考
- 你能想到哪些方式判断一个元素是否存在集合中?
- 布隆过滤器并不存储数据本身,那么是怎么做到过滤的?
- 布隆过滤器实现?参数配置?
一般我们用来判断一个元素是否存在,会想到用 List,Map,Set 等,会将元素先保存下来,然后进行筛选。 但是这样的形式都有一个弊端就是一定要保存数据才行,可是我们仅仅想知道是否存在数据,并不要求获取实际数据,
这时候就会觉得这种方式实在是浪费空间。
什么情况下我们只需要判断是否存在这个元素呢? 在系统设计的时候,我们会考虑大量并发的形式,但是很多请求可能是在访问不存在的数据,
那么我们就没有必要继续这个请求,可以在 API 网关层就直接过滤掉。
Bloom Filter 布隆过滤器原理
Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,
被用来检测一个元素是不是集合中的一个成员。
布隆过滤器实现是不保存数据本身,而是通过 K 个 hash 函数来计算在 byte[] 数组中的存放位置,
并把这个位置的值设置为 1, 而这个 K 到底是多少个呢,要根据公式来算出,待会列出。 除了这个 K 值,我们还要计算 byte[] 数组的长度 m ,下面一并列出计算公式:
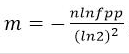
-
fpp : 误判率参数,(must be 0 < fpp < 1)
-
n :预估的需要过滤的总数量
-
ln :求对数,不会的把高中老师的名字写下来

-
m :数组长度
-
n :预估的需要过滤的总数量
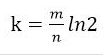
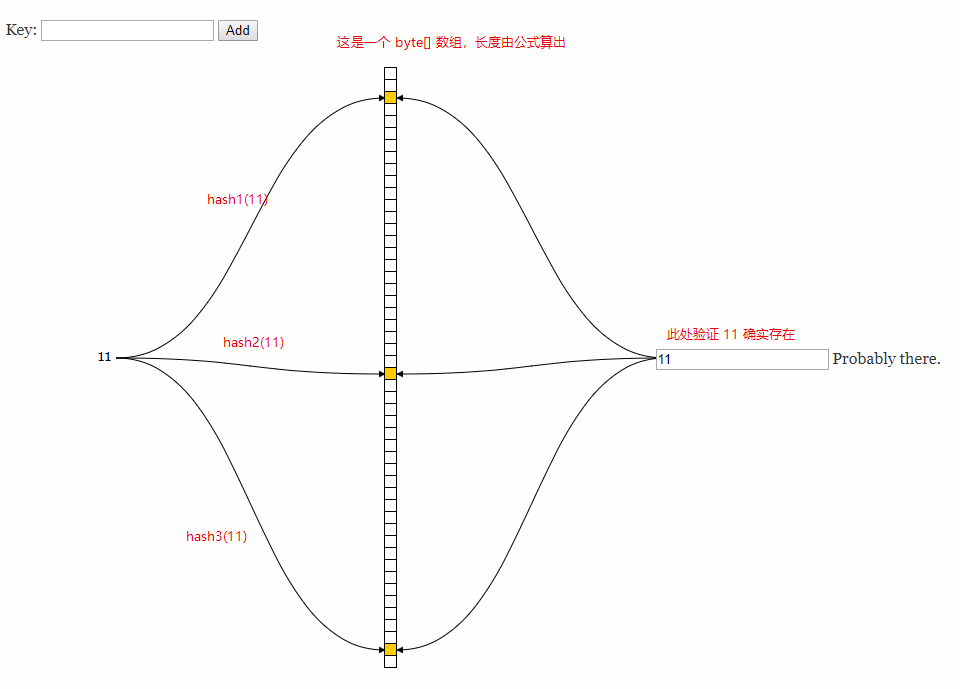
下面我们以数字 11 为例来使用,有个网站可以测试布隆过滤器,
在线测试布隆
布隆过滤器的优点、缺点
优点:
- 节省空间,不用保存所有数据,知识通过 hash 值来计算位置,并通过 byte[] 记录下来。
- 速度快,时间复杂度低 O(1);
缺点:
-
精度低,假设:a 计算的位置 1 ,3 ;b 计算的位置 5,7;c 计算的位置 1,7,那么 c 一定存在吗?
-
不能直接删除,因为想要删除就要把对应的位置置为 0 ,如果这样做,可能会影响其他值的过滤。
布隆过滤器实现
这个其实在 google guava 包中有现成的实现,不用我们自己去实现。我们看看是怎么实现的;
/**
* 计算 bit 数组的长度公式
* n : 预估数据量
* p : 误差率 0-1
*/
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0.0D) {
p = 4.9E-324D;
}
return (long)((double)(-n) * Math.log(p) / (Math.log(2.0D) * Math.log(2.0D)));
}
/**
* 计算 hash 函数个数的方法
* n : 预估数据量
* m : bit 数组长度
*/
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int)Math.round((double)(m / n) * Math.log(2.0D)));
}
动手玩一玩
- expectedInsertions 代表预估数量,越大越准确,在下面的例子中,可以自己随意设置 p 值,过小会发现后面会返回 true
- fpp : 误差率 0-1
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterTest {
public static void main(String[] args) {
int expectedInsertions = 800000000;
double fpp = 0.00001;
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), expectedInsertions, fpp);
int i = 10000;
while (i > 1){
bloomFilter.put("aa" + i);
System.out.println(bloomFilter.mightContain("ab" + i));
i--;
}
}
}
喜欢文章请关注我
程序领域 点击关注+转发,私信发送【面试】或者【资料】可以收获更多资源
这篇关于高并发系统一定要考虑的 Bloom Filter 布隆过滤器的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-11-24Java中定时任务实现方式及源码剖析
- 2024-11-24Java中定时任务实现方式及源码剖析
- 2024-11-24鸿蒙原生开发手记:03-元服务开发全流程(开发元服务,只需要看这一篇文章)
- 2024-11-24细说敏捷:敏捷四会之每日站会
- 2024-11-23Springboot应用的多环境打包入门
- 2024-11-23Springboot应用的生产发布入门教程
- 2024-11-23Python编程入门指南
- 2024-11-23Java创业入门:从零开始的编程之旅
- 2024-11-23Java创业入门:新手必读的Java编程与创业指南
- 2024-11-23Java对接阿里云智能语音服务入门详解



