本文主要是介绍【Java技术探索】各种类型对象占用内存情况分析(下),对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
# 前提回顾
> **建议大家从[【Java技术专题-JVM研究系列(39)Java各种类型对象占用内存情况分析(上)】](https://blog.51cto.com/alex4dream/2928921 "【Java技术专题-JVM研究系列(39)Java各种类型对象占用内存情况分析(上)】")开始学习比较好,这样子会有一个承接和过度。根据前面的学习的内存占用计算规则,可以计算出一个对象在内存中的占用空间大小情况,下面举例分析下Java中的Enum, ArrayList及HashMap的内存占用情况,读者可以仿照分析计算过程来计算其他数据结构的内存占用情况**。
> **注: 下面的分析计算基于HotSpot Jvm, JDK1.8, 64位机器,开启指针压缩。**。
# 对象头
这里只关注其内存占用大小。在64位机器上,默认不开启指针压缩(-XX:-UseCompressedOops)的情况下,对象头占用12bytes,开启指针压缩(-XX:+UseCompressedOops)则占用16bytes。
# 实例数据:
> **对象引用(reference)类型在64位机器上,关闭指针压缩时占用8bytes, 开启时占用4bytes,一般指的是局部变量表或者操作数栈中的reference类型或者针对于成员变量情况下的地址引用(shallow size)**。
> **注: 下面的分析计算基于HotSpot Jvm, JDK1.8, 64位机器,开启指针压缩**。
# 枚举类
> 创建enum时,编译器会生成一个相关的类,这个类继承自`java.lang.Enum`。Enum类拥有两个属性变量,分别为**int的ordinal和String的name**, 相关源码如下:
```java
public abstract class Enum
>
implements Comparable, Serializable {
/**
* The name of this enum constant, as declared in the enum declaration.
* Most programmers should use the {@link #toString} method rather than
* accessing this field.
*/
private final String name;
/**
* The ordinal of this enumeration constant (its position
* in the enum declaration, where the initial constant is assigned
* an ordinal of zero).
*
* Most programmers will have no use for this field. It is designed
* for use by sophisticated enum-based data structures, such as
* {@link java.util.EnumSet} and {@link java.util.EnumMap}.
*/
private final int ordinal;
}
```
以下面的TestEnum为例进行枚举类的内存占用分析
```java
public enum TestEnum {
ONE(1, "one"),
TWO(2, "two");
private int code;
private String desc;
TestEnum(int code, String desc) {
this.code = code;
this.desc = desc;
}
public int getCode() {
return code;
}
public String getDesc() {
return desc;
}
}
```
这里TestEnum的每个实例除了父类的两个属性外,还拥有一个int的code及String的desc属性,所以一个TestEnum的实例本身所占用的内存大小为:
````
12(header) + 4(ordinal) + 4(name reference) + 4(code) + 4(desc reference) = 28(padding) -> 32 bytes.
````
总共占用的内存大小为:
按照上面对字符串类型的分析,desc和name都占用:48bytes。
所以TestEnum.ONE占用总内存大小为:
````
12(header) + 4(ordinal) + 4(code) + 48 * 2(desc, name) + 4(desc reference) + 4(name reference) = 128 (bytes)
````
# ArrayList
> ArrayList实现List接口,底层使用数组保存所有元素。其操作基本上是对数组的操作。下面分析下源代码:
## 底层使用数组保存数据:
```java
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
```
## 构造方法
> **ArrayList提供了三种方式的构造器,可以构造一个默认的空列表、构造一个指定初始容量的空列表及构造一个包含指定collection元素的列表,这些元素按照该collection的迭代器返回它们的顺序排列**。
```java
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* Constructs an empty list with the specified initial capacity.
*
* @ initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @ c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
```
## 存储
> ArrayList提供了set(int index, E element)、add(E e)、add(int index, E element)、addAll(Collection<? extends E> c)等,这里着重介绍一下add(E e)方法。
```java
/**
* Appends the specified element to the end of this list.
*
* @ e element to be appended to this list
* @return true (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
```
> add方法将指定的元素添加到此列表的尾部。这里注意下ensureCapacityInternal方法,这个方法会检查添加后元素的个数是否会超过当前数组的长度,如果超出,数组将会进行扩容。
```java
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Increases the capacity of this ArrayList instance, if
* necessary, to ensure that it can hold at least the number of elements
* specified by the minimum capacity argument.
*
* @ minCapacity the desired minimum capacity
*/
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
```
> 如果初始时没有指定ArrayList大小,在第一次调用add方法时,会初始化数组默认最小容量为10。看下grow方法的源码:
```java
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @ minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
```
> 从上述代码可以看出,数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组扩容的增长是原容量的1.5倍。这种操作的代价是很高的,因此在实际使用时,应该尽量避免数组容量的扩张。当可预知要保存的元素的数量时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
## 内存占用
> 下面开始分析ArrayList的内存占用情况。ArrayList继承AbstractList类,AbstractList拥有一个int类型的modCount属性,ArrayList本身拥有一个int类型的size属性和一个数组属性。
所以一个ArrayList实例本身的的大小为:
> **12(header) + 4(modCount) + 4(size) + 4(elementData reference) = 24 (bytes)**
下面分析一个只有一个Integer(1)元素的ArrayList实例占用的内存大小。
```java
ArrayList testList = Lists.newArrayList();
testList.add(1);
```
根据上面对ArrayList原理的介绍,当调用add方法时,ArrayList会初始化一个默认大小为10的数组,而数组中保存的Integer(1)实例大小为16 bytes。则testList占用的内存大小为:
> **24(ArrayList itselft) + 16(elementData array header) + 10 * 4(elemetData reference) + 16(Integer) = 96 (bytes)**
# HashMap
## HashMap的数据结构
HashMap是一个“链表散列”的数据结构,即数组和链表的结合体。
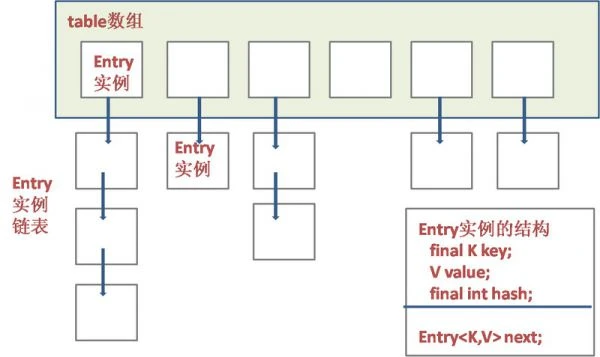
从图上可以看出,HashMap底层是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,初始化一个数组,源码如下:
```java
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
```
Node是链表中一个结点,一个Node对象保存了一对HashMap的Key,Value以及指向下一个节点的指针,源码如下:
```java
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
```
## 构造方法
> **HashMap提供了四种方式的构造器,分别为指定初始容量及负载因子构造器,指定初始容量构造器,不指定初始容量及负载因子构造器,以及根据已有Map生成新Map的构造器**。
```java
/**
* Constructs an empty HashMap with the specified initial
* capacity and load factor.
*
* @ initialCapacity the initial capacity
* @ loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Constructs an empty HashMap with the specified initial
* capacity and the default load factor (0.75).
*
* @ initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* Constructs a new HashMap with the same mappings as the
* specified Map. The HashMap is created with
* default load factor (0.75) and an initial capacity sufficient to
* hold the mappings in the specified Map.
*
* @ m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
```
> **如果不指定初始容量及负载因子,默认的初始容量为16, 负载因子为0.75**。
**负载因子衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小**。对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。
HashMap有一个容量阈值属性threshold,是根据初始容量和负载因子计算得出threshold=capacity*loadfactor, 如果HashMap中数组元素的个数超过这个阈值,则HashMap会进行扩容。HashMap底层的数组长度总是2的n次方,每次扩容容量为原来的2倍。
扩容的目的是为了减少hash冲突,提高查询效率。而在HashMap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
## 数据的存储
```java
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
* @ hash hash for key
* @ key the key
* @ value the value to put
* @ onlyIfAbsent if true, don't change existing value
* @ evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//初始化数组的大小为16,容量阈值为16*0.75=12
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果key的hash值对应的数组位置没有元素,则新建Node放入此位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
```
从上面的源代码中可以看出:当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标)。
如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
## HashMap内存占用
这里分析一个只有一组键值对的HashMap, 结构如下:
```java
Map<Integer, Integer> testMap = Maps.newHashMap();
testMap.put(1, 2);
```
首先分析HashMap本身的大小。HashMap对象拥有的属性包括:
```java
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
```
HashMap继承了AbstractMap<K,V>, AbstractMap有两个属性:
```java
transient Set keySet;
transient Collection values;
```
所以一个HashMap对象本身的大小为:
> **12(header) + 4(table reference) + 4(entrySet reference) + 4(size) + 4(modCount) + 4(threshold) + 8(loadFactor) + 4(keySet reference) + 4(values reference) = 48(bytes)**
接着分析testMap实例在总共占用的内存大小。
根据上面对HashMap原理的介绍,可知每对键值对对应一个Node对象。根据上面的Node的数据结构,一个Node对象的大小为:
```java
12(header) + 4(hash reference) + 4(key reference) + 4(value reference) + 4(next pointer reference) = 28 (padding) -> 32(bytes)
```
加上Key和Value两个Integer对象,一个Node占用内存总大小为:`32 + 2 * 16 = 64(bytes)`
下面分析HashMap的Node数组的大小。
根据上面HashMap的原理可知,在不指定容量大小的情况下,HashMap初始容量为16,所以testMap的Node[]占用的内存大小为:
> **16(header) + 16 * 4(Node reference) + 64(Node) = 144(bytes)**
所以,testMap占用的内存总大小为:
**48(map itself) + 144(Node[]) = 192(bytes)**
> 这里只用一个例子说明如何对HashMap进行占用内存大小的计算,根据HashMap初始化容量的大小,以及扩容的影响,HashMap占用内存大小要进行具体分析,
这篇关于【Java技术探索】各种类型对象占用内存情况分析(下)的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!




