软件架构-Nosql之redis
2021/7/19 13:04:45

本文主要是介绍软件架构-Nosql之redis,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
主要从0到1熟悉redis,之前也简单的介绍过redis,但是根本不够深入,这次深入的一起解析下这个redis。

(一)关系型数据库&nosql
- 区别
nosql:Not Only SQL 的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
关系型数据:就是咱们可以通过标准的sql,进行查询的一种数据库。
- 复杂的查询
在传统的关系型数据库中查询一个复杂的业务需要写很复杂的 sql 语句。很多传统行业(电信,移动,联通,电力,银行)都是通过存储过程来控制的,一个存储过程比较大型的都是几百页很长。之前接触过一个比较大的存储过程有500多行。
- 伸缩性
在传统的关系型数据库业务增大系统需要扩容只能是纵向的形式扩展.操作性能也与遇到瓶颈。mysql为例,其实mysql是没有集群的,它只是master和salve,只是主从的,并不是传统意义的集群,只是读写分离(服务端,客户端),写永远是master,读是salve。操作性能也与遇到瓶颈。
- 遵循规则
- 传统数据库遵循 ACID 规则。( A (Atomicity) 原子性,C (Consistency) 一致性,I (Isolation) 独立性,D (Durability) 持久性)
- Nosql 一般为分布式而分布式一般遵循 CAP 定理(一致性(Consistency) (所有节点在同一时间具有相同的数据), 可用性(Availability) (保证每个请求不管成功或者失败都有响应) ,分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作))
(二)NSQL分类
- 键值(Key-Value)存储数据库:
主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。[3] 举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB.
- 列存储数据库:
用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak. - 文档型数据库:
来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。如:CouchDB, MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。
- 图形(Graph)数据库:
同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。 如:Neo4J, InfoGrid, Infinite Graph.
-
试用场景
1.数据模型比较简单。
2.需要灵活性更强的IT系统。
3.对数据库性能要求较高。
4.不需要高度的数据一致性。
5.对于给定key,比较容易映射复杂值的环境。 -
NOSQL的集中数据库
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Key 指向 Value 的键值对,通常用hash table来实现 | ||||
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
(三)Redis
- 历史
2008年,意大利一家创业公司Merzia推出一款基于MySQL的网站实时统计系统LLOOGG,然而产品上线没多久,该公司的创始人Salvatore Sanfilippo就对MySQL的性能非常不满意,于是亲自操刀开发一款为LLOOGG量身定制的数据库,也就是Redis的雏形。
LLOOGG.com是一个访客信息追踪网站,网站可以通过 JavaScript 脚本,将访客的 IP 地址,所属国家,阅览器信息,被访问页面的地址等数据传送给LLOOGG.com。然后LLOOGG.com会将这些浏览数据通过web页面实时地展示给用户,并储存起最新的5至10000条浏览记录以便进行查阅。随着LLOOGG.com的用户越来越多,LLOOGG为每个网站维护的浏览记录列表变得越来越多,执行的插入和弹出操作也越来越多,由于当时使用的数据库是MySQL,过度频繁的磁盘I/O操作严重影响着系统的性能,这使得Salvatore Sanfilippo萌生出开发一款列表结构的内存型数据库的想法,亲自定做一个数据库,并于2009年开发完成,这个就是Redis。短短几年,用户数据量猛增。国内如新浪微博、街旁和知乎等,国外如GitHub、暴雪等,都是Redis的用户。Redis的代码托管在GitHub上,开发十分活跃。
- 官网
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
- 总结
完全开源免费的、高性能的 key-value 数据库.支持数据持久化、支持多种数据结构存储。可能老铁都有感觉,系统比较慢,不是cpu和内存的问题,硬盘是机械的,如果换个固态效果很明显。为什么mac本那么快,新的mac本都是固态硬盘的。办公室有个机械硬盘的imac慢的一笔。
redis数据的存储:内存
mysql数据的村塾:硬盘
- 适用场景
适用场景:存储缓存、投票、会话 session、排行榜(如果是mysql,要使用order by,group by 才可以查询的到)、计数器、发布订阅等。
- Redis 单机版
在一台机器部署了redis应用。
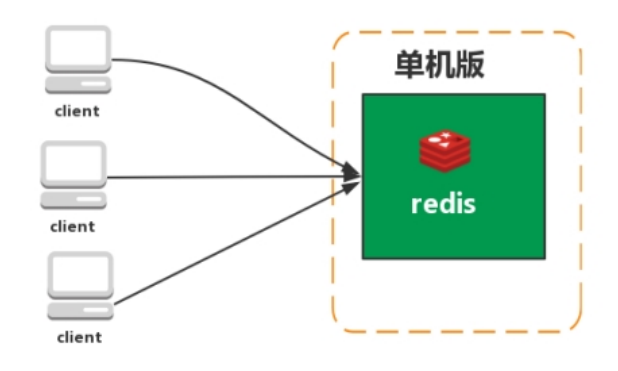
存在的问题
1.内存容量有限(redis本身是存储在内存里面,硬件机器本身的内容容量是有限,往redis存储的量可能很大,就会出现内存容量的问题)
2.处理能力有限(一个人干活跟二个人干活的区别。跟内存的限制相似,类似网络不好,能力就收到限制)
3.无法高可用(一旦请求量上去,可能存在系统挂掉,挂掉其他的调用系统就无法调用了)
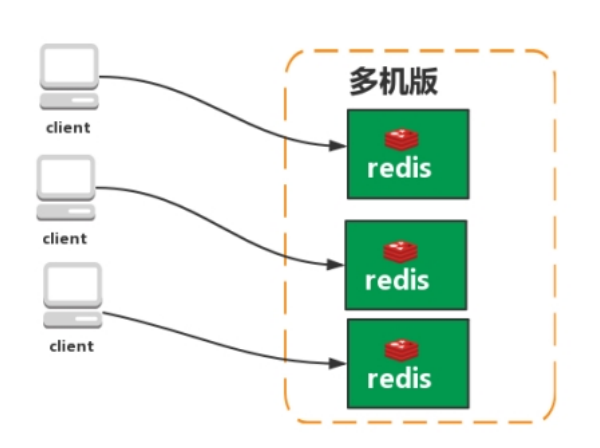
- Redis 多机版
注意:
主从(主库挂了不能写了,影响业务)
从库(从库挂了写读不受到影响,会降低处理能力)
特性
- 复制(Replication)扩展系统对于读的能力
- 哨兵(Sentinel) 为服务器提供高可用特性,减少故障停机出现
- 集群(Cluster) 扩展内存容量,增加机器,提高性能读写能力和存储以及提供高可用特性。 人多力量大,合理化的分工,分工明确,效率增加。
- 复制
Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。 只要主从服务器之间的网络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步 给从服务器,从而一直保证主从服务器的数据相同。
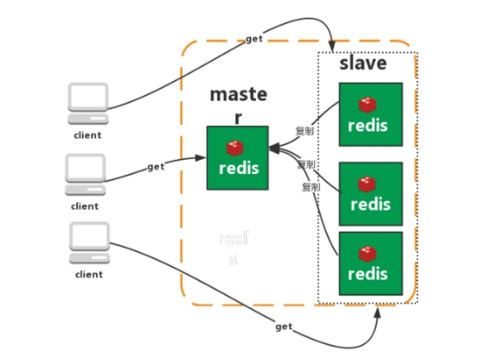
特点
- master/slave 角色
- master/slave 数据相同
- 降低 master 读压力在转交从库
缺点:无法保证高可用,没有解决 master 写的压力
- 哨兵(不是个应用程序,redis的阉割版)
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。理解成:哨兵理解成太监,master皇帝,slave是妃子。
1.监控(Monitoring ):
Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
2.提醒(Notification ):
当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API向管理员或者其他应用程序发送通知。
3.自动故障迁移(Automatic failover ):
当一个主服务器不能正常工作时, Sentinel会开始一次自动故障迁移操作。
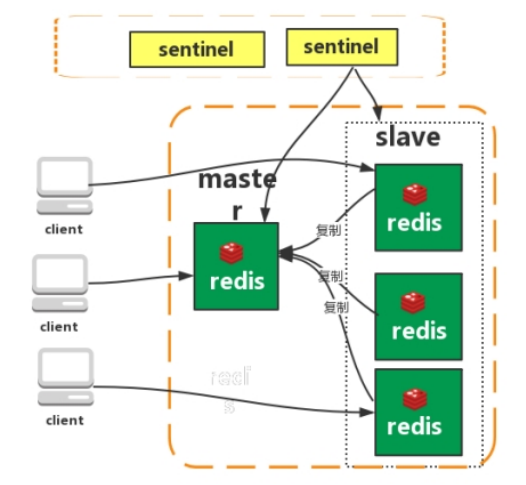
特点
- 保证高可用
- 监控各个节点
- 自动故障迁移
缺点:主从模式,切换需要时间丢数据没有解决 master 写的压力。
- 集群(proxy )
之前的情况都是有个proxy层,类型先过个nginx的代码。通过proxy层进行转向。负载均衡,分片来使用的。需要指定master。
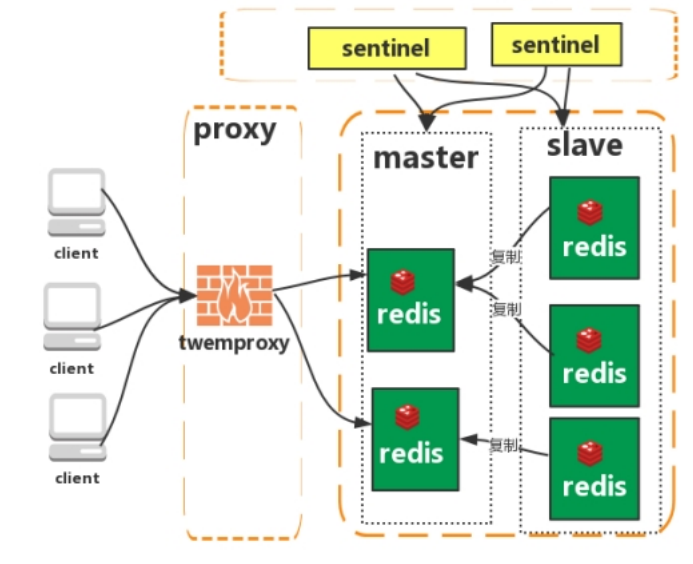
Twemproxy 是一个 Twitter 开源的一个 redis 和 memcache 快速/轻量级代理服务器。
Twemproxy 是一个快速的单线程代理程序,支持 Memcached ASCII 协议和 redis 协议。
特点
- 多种 hash 算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur、Jenkins。
- 支持失败节点自动删除。
- 后端 Sharding 分片逻辑对业务透明,业务方的读写方式和操作单个 Redis 一致。
缺点
- 增加了新的 proxy,需要维护其高可用。
- failover 逻辑需要自己实现,其本身不能支持故障的自动转移可扩展性差,进行扩缩容都需要手动干预。
- 集群(直连)
Redis 3.0的最重要特征是对Redis集群的支持,此外,该版本相对于2.8版本在性能、稳定性等方面都有了重大提高。类似zookeeper是通过选举来的。master自动指定的。

特点
- 无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
- 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
- 可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
- 高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
- 实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave
到 Master 的角色提升。
缺点
- 资源隔离性较差,容易出现相互影响的情况,通过上边的图也是可以看到的,redis之前的关系很复杂。
- 数据通过异步复制,不保证数据的强一致性。
- 最低要求三主三从,不适合小公司。
- 自研型
国美:Gcache
京东:JimDB
PS:这次主要说说redis集群的理论,下次一起实践下。
这篇关于软件架构-Nosql之redis的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-07Redis高并发入门详解
- 2024-12-07Redis缓存入门:新手必读指南
- 2024-12-07Redis缓存入门:新手必读教程
- 2024-12-07Redis入门:新手必备的简单教程
- 2024-12-07Redis入门:新手必读的简单教程
- 2024-12-06Redis入门教程:从安装到基本操作
- 2024-12-06Redis缓存入门教程:轻松掌握缓存技巧
- 2024-12-04Redis入门:简单教程详解
- 2024-11-29Redis开发入门教程:从零开始学习Redis
- 2024-11-27Redis入门指南:快速掌握Redis基础操作



