【纯字三千】一起看看数据库的物理设计 | 数据库教程6:数据库的物理结构——索引、存储结构和聚簇,B+树和Hash索引的存取
2021/8/11 13:06:31

本文主要是介绍【纯字三千】一起看看数据库的物理设计 | 数据库教程6:数据库的物理结构——索引、存储结构和聚簇,B+树和Hash索引的存取,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
数据库的物理设计和物理结构
为一个给定的逻辑数据模型,选取一个最适合应用要求的物理结构的过程,就是数据库的物理设计。
数据库在物理设备上的存储结构与存取方法称为数据库的物理结构,它依赖于选定的DBMS的实现。
关系数据库物理设计的内容:
为关系模式选择存取方法(建立存取路径)。
为关系、 索引、 日志、 备份等数据库文件选择物理存储结构。
(索引)存取方法
索引用于关系模式的数据库中数据的存取方法。换句话说,一种索引就代表了一个存取数据的方法。
存取方法主要可分为:索引方法和聚簇方法。
聚簇或聚集,通常也是需要在此基础上创建索引,即聚簇索引或聚集索引,只不过该索引对应数据库中数据的实际物理存储顺序。
从这可以看出,设计索引,设计数据存取的方式,也同样是在设计对应的物理结构。
索引
为什么要建立索引?
提高存取效率——查询、插入、删除、更新的效率。
这就对应着,如何选择索引,比如,对哪些属性列建立索引、哪些索引需要是唯一索引或组合索引,还有选择合适的索引方法。
通常的RDBMS都会提供常见的几种索引方法:如B-tree(B+树), hash(散列) R-tree 、 Bitmap等。
选择索引存取方法的一般规则
如果一个(或一组)属性经常在查询条件中出现,则考虑在这个(这组)属性上建立索引(或组合索引);
如果一个属性经常作为最大值和最小值等聚集函数的参数,则考虑在这个属性上建立索引;
如果一个(或一组)属性经常在连接操作的连接条件中出现,则考虑在这个(或这组)属性上建立索引。
如何创建索引
CREATE [ UNIQUE ] INDEX 索引名字 ON 表名 [ USING
索引方法 ] ( 列名1,列名2, [, ...] );
比如:
CREATE UNIQUE INDEX studentname ON student
USING Hash (sname);
此处只是一个通用的伪代码示例。具体的索引创建、使用和管理,不同的数据库都有一定的差别,会在后续专门介绍索引的内容时,详细说明索引相关的SQL语句。
B+树索引存取
B+树索引的特点:
多分平衡树,存取效率高
既能随机查找、又能顺序查找
增删改操作,保持平衡
B/B+树中的概念:
秩:节点上的数据块数。
一个B+数的结构如下:
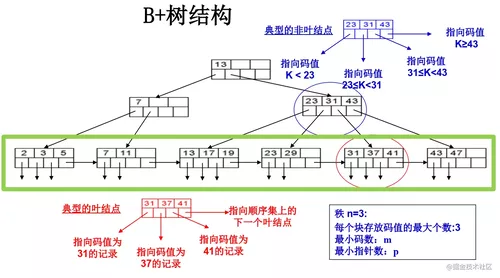
B+数随机查找1:有相关记录
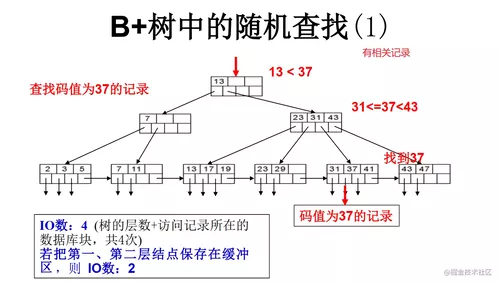
B+数随机查找2:无相关记录
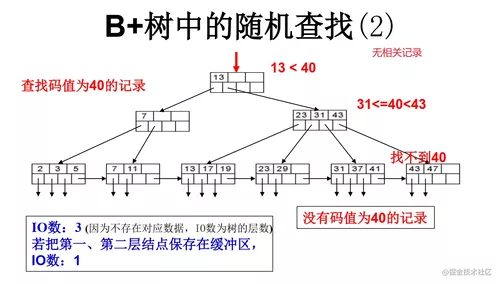
B+树的范围查找
B+树的范围查找:先按照随机查找的方法,查找叶节点,找到范围的入口点;然后沿着顺序链进行范围查找。
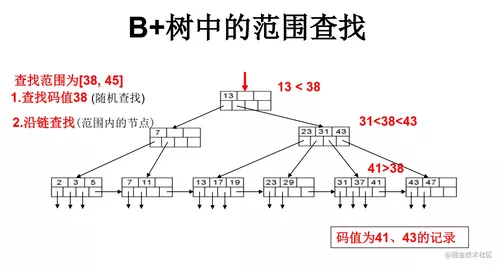
图片来自中国人民大学慕课课程《数据库系统概论(高级篇)》课件,有改动
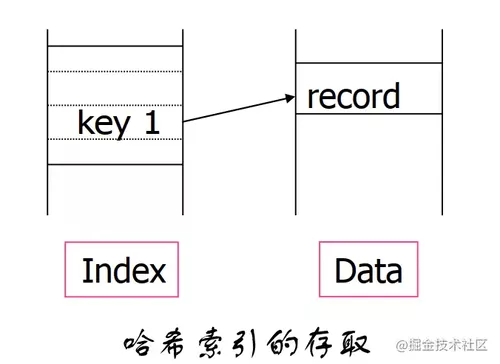
Hash索引存取
Hash称为哈希或散列。是一种键值对形式的结构。
首先,简要讲一下哈希结构,或者也可以称为哈希表、散列表。
如果键和值相同,也会被称为Set( 集合);Key 和 Value 所对应的内容不一样时,称为Map,即键值对集合。
哈希索引
哈希索引(hash index)基于哈希表实现。对于每一行数据,存储引擎都会对其索引列计算一个哈希码(hash code),不同的索引列计算的哈希码也不相同,哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
因为哈希码的大小较小,占用空间小。同时哈希索引采用连续存储的方式,存取速度也会更快。
对于hash相同的,通常采用链表的方式解决冲突。因为索引的结构是十分紧凑的,所以hash索引的查询很快。
存在多种不同的哈希函数生成哈希码,哈希码相同的概率也就不同。比如SHA256散列函数,现阶段不会生成重复的码。具体要看RDBMS的实现。
哈希索引的存取
因此哈希索引的存取也很简单,通过哈希索引键,直接获取行记录(,可能还会有个哈希键中的链表的处理)。

选择Hash存取方法的规则
如果一个关系的属性主要出现在等值连接条件中或主要出现在等值比较选择条件中,而且满足下列两个条件之一:
同时如果表中的列是大数据对象类型的列(text、varchar(max)类型的列),且经常作为查询的条件,也可以考虑使用哈希索引。
该关系的大小可预知,而且不变;
该关系的大小动态改变,但所选用的数据库管理系统提供了动态Hash存取方法。
索引带来的额外开销
是否需要建立索引,以及选择哪种索引,都会给数据库带来各种额外的开销。因此要综合选择,确保使用索引的利大于弊。
● 维护索引的开销 ● 查找索引的开销 ● 存储索引的开销
以及索引维护产生的索引碎片等。
聚簇
为了提高某个属性(或属性组)的查询速度,把该属性(属性组)上具有相同值的元组集中存放在连续的物理块中称为聚簇。
该属性(或属性组)称为聚簇码(cluster key)。聚簇或聚集表示物理数据的实际存储位置或存储顺序。
大多数RDBMS都提供了聚簇功能。
如何建立聚簇(索引)
先创建一个聚簇
CREATE CLUSTER <聚簇名> (<聚簇码>) SIZE (<大小>);
2.在聚簇上建立索引
CREATE INDEX <索引名> ON CLUSTER <聚簇名>;
例如:
CREATE CLUSTER emp_dept_cluster (deptno number(6) ) SIZE 1024;
CREATE INDEX emp_dept_cluster_index ON CLUSTER emp_dept_cluster;
聚簇的优点(好处)
可以大大提高按聚簇属性进行查询的效率。
以专业系名为例。假设要查询计算机系的所有学生。
学生数据表随机存放,计算机系的500名学生可能分散存储在500个不同的物理块上,除去查询的过程,则仅读取数据可能就要执行多达500次I/O操作。
如果按照专业系名聚簇存放,将同一系的学生元组聚簇在一起存放,则可以显著地减少访问磁盘的次数。计算机系的500名学生,假设聚簇存储在50个不同的物理块上,只要执行50次I/O操作。当然最理想的情况是,聚簇在一个连续的物理块上,则只要执行1次I/O操作。
当SQL语句中包含有与聚簇码有关的ORDER BY,GROUP BY,UNION,DISTINCT等子句或短语时,使用聚簇索引可以省去或减少对结果集的排序操作。
在多表连接中,聚簇可以将多个关系提前实现类似"预连接"的效果形式存放,提高连接操作的效率(本质还是提高查询的效率)。
比如,从学生表和课程表中,选出(姓名、课程、成绩)的结果,使用"学号"将课程表聚簇在一起,连接操作时就可以提高效率。
SELECT sname, cname, grade from student, scourse where student.sno=scourse.sno; 复制代码
连接操作通常比较耗时。
既适用于单个关系独立聚簇,也适用于多个关系组合聚簇。
聚簇的局限性
在一个基本表上最多只能建立一个聚簇索引。
聚簇是物理上存放在一起,一个基本表,只能在物理上只能按照一种方式存放。
聚簇只能提高某些特定应用的性能。使用聚簇键的SQL语句,才会提高性能。
建立与维护聚簇的开销相当大
对已有关系建立聚簇,将导致关系中元组的物理存储位置移动,并使此关系上原有的索引无效,必须重建。
当一个元组的聚簇码(值)改变时,该元组的存储位置也要相应改变。(比如以系名为聚簇,如果转系,修改系名,该元组的物理存储位置也要改变,增加开销)
因此,聚簇索引的适用条件也比较严格,或者需要慎重考虑是否适用下面的条件:
很少对基表进行增删操作。
很少对其中的变长列进行修改操作。
存储结构
对于数据的存储安排和存储结构,可以从数据分类来看,比如:
关系(用户数据,下面的为系统数据)
索引
数据库缓冲区
日志
备份
存储结构包括的方面
确认其存储在“内存/磁盘”,还是使用“行存储/列存储”的形式,存放的方式是“集中/分散”还是“顺序/随机/聚簇”,以及存储的页大小、块大小、存放路径等,都属于存储结构的考虑范围。
通常这些方面的设置,都需要参考具体DBMS的系统参数配置及方法
物理安排的基本原则
物理安排的基本原则为:
根据应用情况和物理环境(磁盘或磁盘阵列的容量、内存的大小)
易变部分与稳定部分的数据分开存放
经常存取部分与存取频率较低部分分开存放
将日志文件与数据库对象(表、索引等)分开存放
将比较大的表拆分存放,比如分区等,分别存放在不同的文件或磁盘上,尤其是多用户环境下。
应对海量数据和超多用户的需求,将数据分库分表、以及存放在不同磁盘或磁盘阵列上,都是改进和提高系统性能的有效方法。
关于存储分配的参数
关于存储分配的参数,通常有以下几个方面,一般都有对应的默认值:
同时使用数据库的用户数
同时打开的数据库对象数
内存分配参数
缓冲区分配参数(使用的缓冲区长度、个数)
存储分配参数
物理块的大小
物理块装填因子
数据库的大小
锁的数目等
聚簇的一点个人理解【不知是否完全正确】
从定义上:把属性(属性组)上具有相同值的元组集中存放在连续的物理块中称为聚簇。
其中需要考虑不相同值的元组吗?聚簇应该指的是相同值聚集存储在一起。不同值的元组可能会存储在另一块连续空间。
对于存取来说,不相同值的元组是如何处理的?这就要对应到聚簇索引了,通过聚簇索引维护不同的聚簇码值,实现查找。
作者:代码迷途
这篇关于【纯字三千】一起看看数据库的物理设计 | 数据库教程6:数据库的物理结构——索引、存储结构和聚簇,B+树和Hash索引的存取的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-24怎么修改Kafka的JVM参数?-icode9专业技术文章分享
- 2024-12-23线下车企门店如何实现线上线下融合?
- 2024-12-23鸿蒙Next ArkTS编程规范总结
- 2024-12-23物流团队冬至高效运转,哪款办公软件可助力风险评估?
- 2024-12-23优化库存,提升效率:医药企业如何借助看板软件实现仓库智能化
- 2024-12-23项目管理零负担!轻量化看板工具如何助力团队协作
- 2024-12-23电商活动复盘,为何是团队成长的核心环节?
- 2024-12-23鸿蒙Next ArkTS高性能编程实战
- 2024-12-23数据驱动:电商复盘从基础到进阶!
- 2024-12-23从数据到客户:跨境电商如何通过销售跟踪工具提升营销精准度?



