Java NIO 简介
2021/10/10 22:47:27

本文主要是介绍Java NIO 简介,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
NIO 简介
自 JDK 1.4 以来,引入了一个被称为 NIO(New IO) 的 IO 操作,是标准 IO 一个替代品。Java 的 NIO 提供了一种与传统意义上的 IO 不同的编程模型。有时,NIO 也被称为 No-Blocking IO,这是因为一般情况下 NIO 的 API 都是非阻塞的。然而,使用 No-Blocking IO 并不能很好地表示 NIO 地意思,因为 NIO 有一部分 API 依旧是阻塞的。
传统 IO 与 NIO
主要区别
- 传统 IO 是面向字节流的,而 NIO 是面向 Buffer 的
- 面向字节流:面向字节流意味着一次从一个流中读取一个或者多个字节,要对这些字节流做什么操作取决于自己的实现。由于这些读取的字节流并不能缓存起来,因此在读取字节流的时候只能是对读取到的字节进行相应的操作,不能再次读取之前的字节也不能读取后面的字节。
- 面向 Buffer:与面向字节流的方式不同,数据被读取到 Buffer 中以便之后再进行处理。由于 Buffer 的存在,对于这个 Buffer 内任意字节的读取都是可行的。同时,由于 Buffer 是位于内存中的,因此数据的处理速度要比一般面向字节流的方式的处理速度更快。
- 传统 IO 是阻塞的,而 NIO 一般是非阻塞的
- 传统 IO 的各种流都是阻塞的,这意味着,当一个线程调用类似
read()或write()这样的方法时,整个线程都会是阻塞的。在这个线程被阻塞期间,这个线程不能做其它的任何工作 - NIO 的各个操作一般都是非阻塞的,这种非阻塞的模式使得一个线程能够当一个 IO 操作完成时再去进行相应的处理,而不是一直等待。
- 传统 IO 的各种流都是阻塞的,这意味着,当一个线程调用类似
一般模型:

- Disk Buffer:一个用于读取存储在磁盘上的数据块的 RAM,这个操作是一个十分慢的操作,因为它要调用物理磁盘指针的移动来获取数据
- OS Buffer :OS 有自己的缓存可以缓存更多的数据,并且可以更加优雅地对数据进行管理。这个缓存也可以在应用程序之间进行共享。
- Application Buffer:应用程序自己的缓存
传统的 IO 只能使用到 Disk Drive Buffer 的缓存,而 NIO 则能够使用 Application Buffer 甚至是 OS Buffer,因此 NIO 对于数据的处理回更加高效。
Buffer
NIO 的数据传输是通过继承了 java.nio.Buffer 类的被称为 buffers 来实现的。一个 Buffer 与数组有一些相似,但是通过与底层操作系统紧密耦合因此更加有效率一些。一个 Buffer 是一个连续的、线性的存储。和数组一样,一个 Buffer 有固定的大小。
Java 中 NIO 的继承类类对除了 boolean 类型外,其它的基本数据类型都有相对应的 buffer 实现。这些实现类的抽象父类 java.nio.Buffer 提供了对于所有 buffer 的一般属性,并且定义了一些一般的操作集合。
一个 Buffer 一般会有以下几个属性字段:
-
mark用于标记上次访问的
position的位置索引,可以通过调用mark()方法来获取。如果重新设置position或者limit的值小于mark,那么就会丢弃之前的mark -
position表示要读取或者写入的下一个元素的位置索引,这个属性字段的值不能大于 `limit`。可以通过 `position()` 方法来获取到当前的 `position`,或者通过 `position(int newPosition)` 来重新设置 `position`。
-
limit 表示在 Buffer 中第一个不能被读取或者修改的元素位置索引,
limit的大小不能超过capacity。实际上,这就表示当前处理的数据所占用的空间,也就是说,在当前处理的 Buffer 中,有效数据的范围是 [0, limit -1]。 可以通过调用
limit()方法来得到当前的limit位置,也可以通过limit(int newLimit)方法来重新设置limit,但是设置的limit不能大于capacity -
capacity 表示能够存储元素的最大容量大小,这个属性字段不能为空,在创建 Buffer 的时候就必须指定并且在之后不能被修改。可以通过 Buffer 的
capacity()方法来获取该 Buffer 的容量 -
address只有在直接 Buffer 中才会使用到
这几个字段之间的大小关系为:0 ≤ mark ≤ position ≤ limit ≤ capacity
基本使用:
-
创建一个 buffer
- 调用
Buffer子类的allocate(int capacity)方法,可以得到一个容量为capacity的子类 buffer - 调用
Buffer子类的wrap(type[] array, int offset, int length)或wrap(type[] array)方法将一个byte数组转换为 buffer - 通过已有的 buffer 创建一个视图,这个会共享已有的 buffer。具体可以查看
Buffer具体子类的duplicate()方法
- 调用
-
操作 buffer
-
mark()标记之前的
position,使得当前 buffer 对象的mark字段值更新为当前的position, -
reset()将当前 buffer 对象的
position置为mark,如果没有之前没有调用mark()更新mark,那么就会抛出InvalidMarkException。 -
clear()将
position置为 0,limit置为capacity,同时丢弃mark,为读取数据做准备这个方法实际上并不会直接擦除 buffer 内的数据,但是在一般情况下清除之后都会直接读取数据来覆盖原有的数据,因此实际效果与擦除了数据的效果是一致的。
-
flip()设置
limit的值为position,同时将position置为 0,同时丢弃mark,为输出数据做准备。一般在调用
flip()方法后会调用compact()方法来移动缓冲区后面的一部分数据到 buffer 的开始位置 -
compact()将
position到limit之间的数据复制到 buffer 的开始位置,如果已经定义了mark,那么就丢弃 它 -
rewind()设置
position为 0,同时丢弃mark,为数据读取做准备
-
-
直接 buffer和非直接 buffer
-
直接 buffer
-
JVM 将会尽最大努力直接在 buffer 上执行 IO 操作,因此,它将试图去避免在每次调用系统 IO 操作之前将缓冲区内容复制到中间缓冲区。所以,直接 buffer 将会更加有效率些。
-
对于
ByteBuffer,可以通过调用allocateDirect(int capacity)分配一个直接ByteBuffer。对于其他的 buffer(char、short、int 、float、long、double),需要首先创建一个ByteBuffer,然后通过类似于asIntBuffer()的方法创建一个对应的视图。由于这些基本数据类型是由多个 byte 组成的单元,所以需要通过order(ByteOrder order)指定 byte 的端顺序(大端—大byte在前、小端—小 byte 在前)。order 参数可以是ByteOrder.BIG_ENDIAN,ByteOrder.LITTLE_ENDIAN,或者ByteOrder.nativeOrder()自动得到当前平台的端顺序。// 使用直接 buffer 的方式分配 200 字节的 buffer ByteBuffer buffer = ByteBuffer.allocateDirect(200); // 将这个 ByteBuffer 转换为对应的 IntBuffer。 // 一般来讲,除了那些老式的操作系统,如 Solaris、AIX 为大端顺序之外,其它的操作系统都为小端顺序 IntBuffer intBuffer = buffer.order(ByteOrder.LITTLE_ENDIAN).asIntBuffer();
-
-
非直接 buffer
将 buffer 分配到 JVM 中的堆区中
-
Channel
一个 Channel 代表一个物理 IO 连接。跟标准 IO 流有点像,但是 Channel 是一个更加依赖平台的流版本。由于channel 跟平台之间的有着紧密联系,因此它能够实现更好的 IO 吞吐量。 channel 分为以下几种:
FileChannelSocketChannel:支持非阻塞 TCP Socket 连接DatagramChannel:UDP 面向数据报 Socket 的连接
Channel 与 Stream 的区别:
- 可以同时在多个 Channel 上分别进行 读/写 操作;在 Stream 上只能执行一种操作(读或写)
- Channel 的读写操作可以是异步的,但是 Stream 的操作是同步的
- Channel 都是围绕 buffer 来展开操作的
获取 Channel:
通过 java.io.FileInputStream, java.io.FileOutputStream, java.io.RandomAccessFile, java.net.Socket, java.net.ServerSocket, java.net.DatagramSocket, 和java.net.MulticastSocket 等对象的 getChannel() 方法可以获取一个 Channel 对象。
Channel 中的操作都需要围绕 buffer 来展开,当读取数据时从数据输入的 Channel 中读取到 buffer,写数据时则直接将 buffer 中的内容写入到 Channel
实例:将一个文件复制到另一个文件
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class JustTest {
public static void main(String[] args) throws IOException {
File fileIn = new File("/home/lxh/awk/1.txt"); // 文件输入 channel
File fileOut = new File("/home/lxh/awk/2.txt"); // 文件输出 channel
ByteBuffer buffer = ByteBuffer.allocate(4*1024); // 分配缓冲区大小为 4*1024 字节,即 4 kb
// 使用 try(...) 的方式打开文件,可以有效避免由于忘记关闭流出现的一系列问题
try (
FileChannel in = new FileInputStream(fileIn).getChannel();
FileChannel out = new FileOutputStream(fileOut).getChannel();
) {
// 从输入 channel 中读取字节到 buffer 中,读取的字节数可能是 0(数据已经读完)、-1(已到达输入流的末尾)或本次读取的字节数
int byteSize = in.read(buffer);
while (byteSize != -1) {
buffer.flip(); // 准备将 buffer 中的数据输出
out.write(buffer); // 将 buffer 中的数据写入到输出 channel 中
buffer.compact(); // 将 buffer 中已经输出的数据的后面部分移动到 buffer 的开始位置
byteSize = in.read(buffer);
}
}
}
}
几种常见的文件复制方式之间的性能比较(单位:ms):
测试源代码(基于 JDK 1.8 压缩文件的复制操作):https://raw.githubusercontent.com/LiuXianghai-coder/Test-Repo/master/Code/JustTest.java
| BufferSize | directBuf | heapBuf | transferTo | BuffRead | stdIo |
|---|---|---|---|---|---|
| 4KB | 2308 | 214 | 75 | 2575 | 165 |
| 16KB | 90 | 109 | 76 | 834 | 115 |
| 64KB | 76 | 89 | 76 | 811 | 92 |
| 256KB | 76 | 88 | 72 | 816 | 87 |
| 1024KB | 82 | 95 | 66 | 812 | 86 |
分散/聚合
Java 的 NIO 支持分散 / 聚合的操作,也就是说,NIO 支持从一个 Channel 中读取数据到多个 buffer,这个过程就被称作 “分散”(从一个 Channel 中读取数据到多个 buffer);将多个 buffer 中的数据写入到一个 Channel,这个过程就被称为 “聚合”(从多个 buffer 写入到一个 Channel)
分散/聚合在需要使用多个部分的数据时非常有用,比如,如果想要将一个由 “消息头” 和 “消息体” 组成的消息发送到 SocketChannel,将“消息头”和“消息体”分开放在不同的 buffer 中,会使得处理起来更加容易。
-
分散读
如下图所示:

读取示例:
ByteBuffer headBuffer = ByteBuffer.allocate(128); // 消息头 buffer ByteBuffer bodyBuffer = ByteBuffer.allocate(4 * 1024); // 消息体 buffer ByteBuffer[] bufferArray = {headBuffer, bodyBuffer}; // 组合成一个 buffer 数组 FileChannel channel = new FileInputStream("/home/lxh/1.txt").getChannel();// 获取 Channel channel.read(bufferArray); // 从 Channel 中读取数据到 buffer 数组中,按照顺序读入,当一个 buffer 读满之后,再读入到下一个 buffer 中值得注意的是,只有在前一个 buffer 被读满之后才会读入到下一个 buffer 中,因此如果消息头的长度不是固定的话很可能会造成读取序列混乱
-
聚合写
如下图所示:
写入示例:
ByteBuffer headBuffer = ByteBuffer.allocate(128); ByteBuffer bodyBuffer = ByteBuffer.allocate(4 * 1024); ByteBuffer[] bufferArray = {headBuffer, bodyBuffer}; FileChannel channel = new FileOutputStream("/home/lxh/1.txt").getChannel(); channel.write(bufferArray);// 写入的 buffer 内容从 position 到 limit 之间的数据注意:每个 buffer 数据的写入只会写入从 position 到 limit 之间的数据,然后再写入之后的数据。在写入时需要特别注意这一点,否则可能会引起数据的混乱
Selector(选择器)
上文提到,NIO 的操作一般都是非阻塞的,但是上文给出的每个示例都还是基于阻塞的方式来实现的,与一般使用传统 IO 的方式并没有什么不同。NIO 提供的 Selector 是实现非阻塞的关键组件,通过 Selector 来轮询 Channel,可以实现非阻塞的读写操作。
NIO 的 Selector 是一个可以检测一个或多个 Channel 的组件,Selector 可以检测到哪些 Channel 是已经处理完任务并且是可用的。Selector 使用单线程的方式来管理多个 Channel,进一步讲,可以使用单个线程来管理多个网络连接,这是使用传统 IO 是无法做到的。
使用 Selector 的优点:
- 使用单线程的方式处理多个 Channel 可以使得需要的线程的数量减少。一般传统的 Servlet 对于每个请求的处理方式都是直接创建一个线程去处理对应的请求,当请求很多时将会创建大量的线程,将会极大地浪费系统资源。
- 由于需要的线程数量的减少,因此创建线程也不会那么频繁,同时也会减少线程的上下文切换,因此这也会提高系统的性能。
Selector 的线程模型如下所示:
使用:
-
创建一个 Selector:
Selector selector = Selector.open();
-
将 Channel 注册到 Selector
/* 由于 FileChannel 并没有实现 SelectableChannel,因此它不能是异步非阻塞的。这是由于 Unix 文件系统并不支持异步 IO 为了实现异步 IO 的功能,JDK 1.7 引入了 AsynchronousFileChannel 来实现异步 IO 由于注册到 Selector 中的 Channel 必须是非阻塞的,为了简化这个问题,以下的示例使用的是 ServerSocketChannel,这个类型的 Channel 可以是异步非阻塞的 */ ServerSocketChannel socketChannel = ServerSocketChannel.open(); // 打开一个 ServerSocketChannel socketChannel.configureBlocking(false); // 配置 ServerSocketChannel 为非阻塞的 Selector selector = Selector.open(); // 创建一个 Selector // 将 socketChannel 注册到 selector 中, SelectionKey.OP_READ 表示当 OP_READ(即可读)时表示该 Channel 可用 SelectionKey key = socketChannel.register(selector, SelectionKey.OP_READ);
SelectionKey
代表注册到
Selector中的一个SelectableChannel访问令牌,当一个 Channel 注册到 Selector 时将会创建一个对应的 SelectionKey。SelectionKey 将会一直保留,除非发生以下事件将会会移除 SelectionKey:调用cancle()方法、注册到 Selector 中的 Channel 被关闭了、注册的 Selector 被关闭了。SelectionKey的一些属性:
-
一个 SelectionKey 使用整数来表示的两个操作集合,每个操作集比特位表示这个 SelectionKey 对应的 Channel 可以进行的操作
-
interest set
在下一次调用
selction方法时已经准备就绪的可进行操作的集合。也就是说,可以通过获取interest set来测试可以进行操作的集合。int interestSet = key.interestOps(); boolean isInterestedInAccept = SelectionKey.OP_ACCEPT == (interests & SelectionKey.OP_ACCEPT); boolean isInterestedInConnect = SelectionKey.OP_CONNECT == (interests & SelectionKey.OP_CONNECT); boolean isInterestedInRead = SelectionKey.OP_READ == (interests & SelectionKey.OP_READ); boolean isInterestedInWrite = SelectionKey.OP_WRITE == (interests & SelectionKey.OP_WRITE);
-
ready set
表示已经被 SelectionKey 检测到的可操作集合
int readySet = key.readyOps();
可以使用上文的按位与的操作进行事件的判断,但是使用一般的方法来判断可操作状态可能更加简单
key.isAcceptable(); key.isConnectable(); key.isReadable(); key.isWritable();
-
Channel 和 Selector
通过以下方法可以获得对应的 Channel 和Selector
Channel ch1 = key.channel(); // 返回创建此 key 的 Channel Selector s1 = key.selector(); // 返回创建此 key 的 Selector
-
附加对象
/* 将一个对象附着在当前的 SelectionKey 上 同一时间只能有一个对象附着在 SelectionKey 上,之后附着的对象都将会导致前一个附着的对象被丢弃 */ key.attach(new Object()); // 获取最近附着在此 SelectionKey 上的对象 key.attachment();
-
-
准备 Channel
通过 Selector 来准备 Channel:使用 Selector 的 select() 对可以进行 IO 操作的 Channel 进行获取。
主要存在以下几种 select:
-
select()选择一组键,其对应的通道已准备好进行 I/O 操作,这个方法的返回结果表示有多少 Channel 是已经可用的。就是说,自上次调用
select()方法开始到现 在调用select()之间已经可用的 Channel 的数量。如果调用select()它返回了 1,这是因为有一个 Channel 已经准备好可以使用了;再次调用select(),如果又有一个 Channel 已经准备好了,那么它依旧返回 1。如果在第一次调用select()时对这个 Channel 没有做任何操作,那么将会返回 2,这是因为现在已经有两个 Channel 已经准备好可以使用了。但是在每次调用select()时都只会有一个 Channel 是立即可用的(因为以单线程的方式每次只能处理一个 Channel)。这个方法将会阻塞,直到以下几个条件之一发生:至少存在一个 Channel 已经可用、调用 Selector 的
wakeUp()方法、当前线程被中断 -
select(long timeout)与
select()方法的功能类似,同样也会阻塞,但是可以确保不会超过预订超时时间(不提供真实的时间保证) -
selectNow()与
select()类似,但是这个方法不会阻塞,如果没有可用的 Channel,将会返回 0
处理 Channel
通过 select 方法可以得到可以进行 IO 操作的 Channel 的数量,同时将这些 Channel 准备好以便进行对应的 IO 操作。
通过 Selector 的 selectedKeys() 可以得到当前可用的 Channel 的 SelectionKey 集合(回想一下 SelectionKey)。
// 获取可用的 Channel 的 SelectionKey Set<SelectionKey> keys = selector.selectedKeys();
通过迭代的方式来依次对这些 Channel 进行对应的处理
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
// 迭代便利每个 SelectionKey,进行相应的处理,使用 Channel 是需要对 Channel 进行类型转换
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
/* TODO*/
} else if (key.isReadable()) {
/* TODO*/
} else if (key.isWritable()) {
/* TODO*/
} else if (key.isConnectable()) {
/* TODO*/
}
keyIterator.remove();
}
中断 Selector
中断 Selector 主要有以下两种方法:
-
wakeup()使尚未返回的第一个
select操作立即返回。如果其它的线程由于调用select()或select(long)方法而阻塞,那么将会立即返回。这是通过让另外一个线程调用
wakeUp()方法作用在第一个调用select()方法的 Selector 上来实现的。如果另一个线程调用
wakeUp()方法但是当前没有任何线程处于调用select方法而阻塞的情况下,那么下一个调用select方法的线程将会立刻受到这个wakeUp()方法的影响 -
close()关闭 Selector,这个方法不仅会关闭 Selector,而且也会使得注册到 Selector 中的 SelectionKey 变得无效;但是这个方法不会关闭 Channel
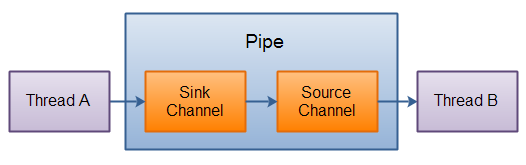
NIO Pipe
NIO Pipe 是在两个线程之间进行数据交流的一种方式,一个 Pipe 有一个 Source Channel 和一个 Sink Channel。将数据写入到 Sink Channel,这些数据就可以从 Source Channel 中读取。
如下图所示:
创建一个 Pipe:
// 创建一个 Pipe Pipe pipe = Pipe.open();
写数据到 Sink Channel 中
Pipe pipe = Pipe.open(); // 创建一个 Pipe
// 从 Pipe 中获取 Sink Channel
Pipe.SinkChannel skChannel = pipe.sink();
String testData = "Test Data to Check java NIO Channels Pipe.";
ByteBuffer buffer = ByteBuffer.allocate(512);
buffer.clear();
buffer.put(testData.getBytes());
buffer.flip(); // 注意,在写入之前一定要将 buffer 执行一次 flip(),否则会导致数据混乱
// 将数据写入到 Sink Channel
while(buffer.hasRemaining()) {
skChannel.write(buffer);
}
从 Source Channel 中读取数据
Pipe.SourceChannel sourceChannel = pipe.source();
buffer = ByteBuffer.allocate(512);
/*
这个地方经过我的试验,使用循环读取的方式(即下面的方式)进行读取会导致整个线程阻塞,具体发生在 read() 方法上
这可能是 JDK 的一个问题(试验环境:JDK 1.8,Ubuntu 20.04)
因此,如果想要避免这个问题,需要直接设置一个容量较大的 buffer 来一次性读取消息
*/
while(sourceChannel.read(buffer) > 0){
buffer.flip();
while(buffer.hasRemaining()){
char ch = (char) buffer.get();
System.out.print(ch);
}
//position is set to zero and limit is set to capacity to clear the buffer.
buffer.clear();
}
异步 IO
上文提及过,Unix 文件系统是不支持异步 IO 的,因此,一般的 NIO 对于文件的操作依旧是同步阻塞的。为了支持异步 IO,自 JDK 1.7 以来引入了 AsynchronousFileChannel 来实现异步 IO。
-
创建一个
AsynchronousFileChannel// NIO 引入的 Path Path path = Paths.get("/home/lxh/1.txt"); /* 创建一个 AsynchronousFileChannel 第一个参数表示文件路径,第二个参数表示要对这个文件进行的操作选项 */ AsynchronousFileChannel asFileChannel = AsynchronousFileChannel.open(path, StandardOpenOption.READ); -
读取数据
使用异步 IO 读取文件时,对于结果的获取有两种方式:一是使用
java.util.concurrent.Future作为返回结果;二是使用java.nio.channels.CompletionHandler-
使用
java.util.concurrent.Future作为返回结果final int bufferSize = 512; ByteBuffer buffer = ByteBuffer.allocate(bufferSize); // 分配 buffer // 使用异步 IO 的方式读取文件,第一个参数表示将读取的数据读到 buffer 中,第二个参数表示文件读取的位置距离文件开始位置的偏移量 Future<Integer> operation = asFileChannel.read(buffer, 0); // 由于现在没有其它任务,因此在这里一直等待直到读取操作完成 while (!operation.isDone()) { Thread.sleep(100); } buffer.flip(); // 切记!!输出 buffer 中的数据时一定要 flip() 调整 postion 和 limit 的位置 System.out.println(new String(buffer.array(), buffer.position(), buffer.limit(), StandardCharsets.UTF_8)); -
使用
java.nio.channels.CompletionHandlerfinal int bufferSize = 512; ByteBuffer buffer = ByteBuffer.allocate(bufferSize); asFileChannel.read( buffer, // 要传输的字节的缓冲区 0, // 距离文件开始位置的偏移量 buffer, // 附着在 IO 操作上的对象,由于要读取结果,因此将传输自己的 buffer 作为附着对象,以便读取数据 new CompletionHandler<Integer, ByteBuffer>() { @Override public void completed(Integer result, ByteBuffer attachment) { System.out.println("readBytes=" + result); attachment.flip(); System.out.println( new String( attachment.array(), attachment.position(), attachment.limit(), StandardCharsets.UTF_8 ) ); } // 读取失败时将会进入这个方法 @Override public void failed(Throwable exc, ByteBuffer attachment) { System.out.println("Read file failed...."); } } ); // 使得当前线程暂停一会儿,以便能够看到异步 IO 的执行结果 Thread.sleep(1500);
-
-
写入数据
同样的,写入数据也可以使用
java.util.concurrent.Future或java.nio.channels.CompletionHandler来完成异步写入的任务-
使用
java.util.concurrent.Future来完成数据的异步写入// 由于是写入操作,因此需要重新打开 Channel,同时将打开操作设置为 write AsynchronousFileChannel asFileChannel = AsynchronousFileChannel.open(path, StandardOpenOption.WRITE); // 待写入文件的内容 final String content = "This is a asynchronous content"; final int bufferSize = 512; ByteBuffer buffer = ByteBuffer.allocate(bufferSize); // 将内容写入 buffer 中 buffer.put(content.getBytes(StandardCharsets.UTF_8)); // 再次提醒,记得 flip() buffer buffer.flip(); // 执行异步写入任务 Future<Integer> future = asFileChannel.write(buffer, 0); // 同样地,这里是等待任务完成,当然也可以做一些其他的工作 while (!future.isDone()) { Thread.sleep(100); } // 输出写入的字节数 System.out.println("write bytes=" + future.get()); -
使用
java.nio.channels.CompletionHandler来完成数据的异步写入// 该 asFileChannel 引用自上文的 asFileChannel asFileChannel.write( buffer, 0, buffer, new CompletionHandler<Integer, ByteBuffer>() { @Override public void completed(Integer result, ByteBuffer attachment) { System.out.println("write bytes=" + result); } @Override public void failed(Throwable exc, ByteBuffer attachment) { System.out.println("write content to file failed"); } } ); // 等待异步 IO 操作执行完成 Thread.sleep(500);
-
文件锁
Java 中的 NIO 是由单线程的方式控制 Channel 来实现的,在 Channel 上不会出现并发的问题。但是由于一个 Channel 可以关联到对应的文件,因此此时文件可能由于多个 Channel 的共享而变得线程不安全。为此引入了文件锁的概念来实现并发访问文件的线程安全。
一般情况下,存在两种文件锁:互斥锁、共享锁
- 独占锁:在同一时刻,只能有一个线程获取这个文件锁。
- 共享锁:可以防止其它并发运行的程序请求独占锁,但是允许它们获取共享锁
获取文件锁的方法:
-
lock()请求一个与给定的
FileChannel或AsynchronousFileChannel相关联的文件的独占锁。返回的类型为FileLock,用于进一步监视这个锁 -
lock(long position, long size, boolean shared)用于获取一个文件内指定范围内容的独占锁 [position, position + size],
shared参数表示是否是共享锁 -
tryLock()如果无法获取到指定 Channel 关联的文件的独占锁,则直接返回
null;否则,返回获取到的独占锁FileLock -
tryLock(long position, long size, boolean shared)尝试获取与 Channel 相关联的文件的指定范围内的独占锁 [position, position + size];通过指定
shared参数表明是否是共享锁;如果尝试获取锁失败则返回null
FileLock 常用的几个方法:
acquiredBy():返回获取到了文件锁相关联的 Channelposition():返回文件范围锁中已经获取到了锁的第一个字节距离文件开始位置的偏移量size():返回获取到的文件范围锁的区间大小isShared():表示当前的锁是否是共享锁overlaps(long position, long size):表示当前传入的区间范围是否存在锁isValid():这个FileLock是否是有效的release():释放当前的锁,如果这个锁对象是有效的,那么在调用这个方法之后将会释放掉这个锁并且将这个锁对象置为无效的;如果这个锁是无效的,那么对这个锁对象没有任何影响close():这个方法将会直接调用release()。这个方法存在的原因是为了实现AutoClose接口。
示例:
String input = "Demo text to be written in locked mode.";
System.out.println("Input string to the test file is: " + input);
ByteBuffer buf = ByteBuffer.wrap(input.getBytes());
String fp = "/home/lxh/1.txt";
Path pt = Paths.get("/home/lxh/1.txt");
// 打开文件获取对应的 Channel
FileChannel channel = FileChannel.open(pt, StandardOpenOption.WRITE, StandardOpenOption.APPEND);
channel.position(channel.size() - 1); // position of a cursor at the end of file
// 获取这个文件的独占锁
FileLock lock = channel.lock();
System.out.println("The Lock is shared: " + lock.isShared());
channel.write(buf);
channel.close(); // Releases the Lock
System.out.println("Content Writing is complete. Therefore close the channel and release the lock.");
参考:
[1] https://www3.ntu.edu.sg/home/ehchua/programming/java/J5b_IO_advanced.html
[2] https://www.tutorialspoint.com/java_nio/index.htm
[3] http://tutorials.jenkov.com/java-nio/index.html
这篇关于Java NIO 简介的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-11-23Springboot应用的多环境打包入门
- 2024-11-23Springboot应用的生产发布入门教程
- 2024-11-23Python编程入门指南
- 2024-11-23Java创业入门:从零开始的编程之旅
- 2024-11-23Java创业入门:新手必读的Java编程与创业指南
- 2024-11-23Java对接阿里云智能语音服务入门详解
- 2024-11-23Java对接阿里云智能语音服务入门教程
- 2024-11-23JAVA对接阿里云智能语音服务入门教程
- 2024-11-23Java副业入门:初学者的简单教程
- 2024-11-23JAVA副业入门:初学者的实战指南



