Redis常见数据类型和底层数据结构
2022/4/10 8:12:31

本文主要是介绍Redis常见数据类型和底层数据结构,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
文末配有高清思维导图笔记
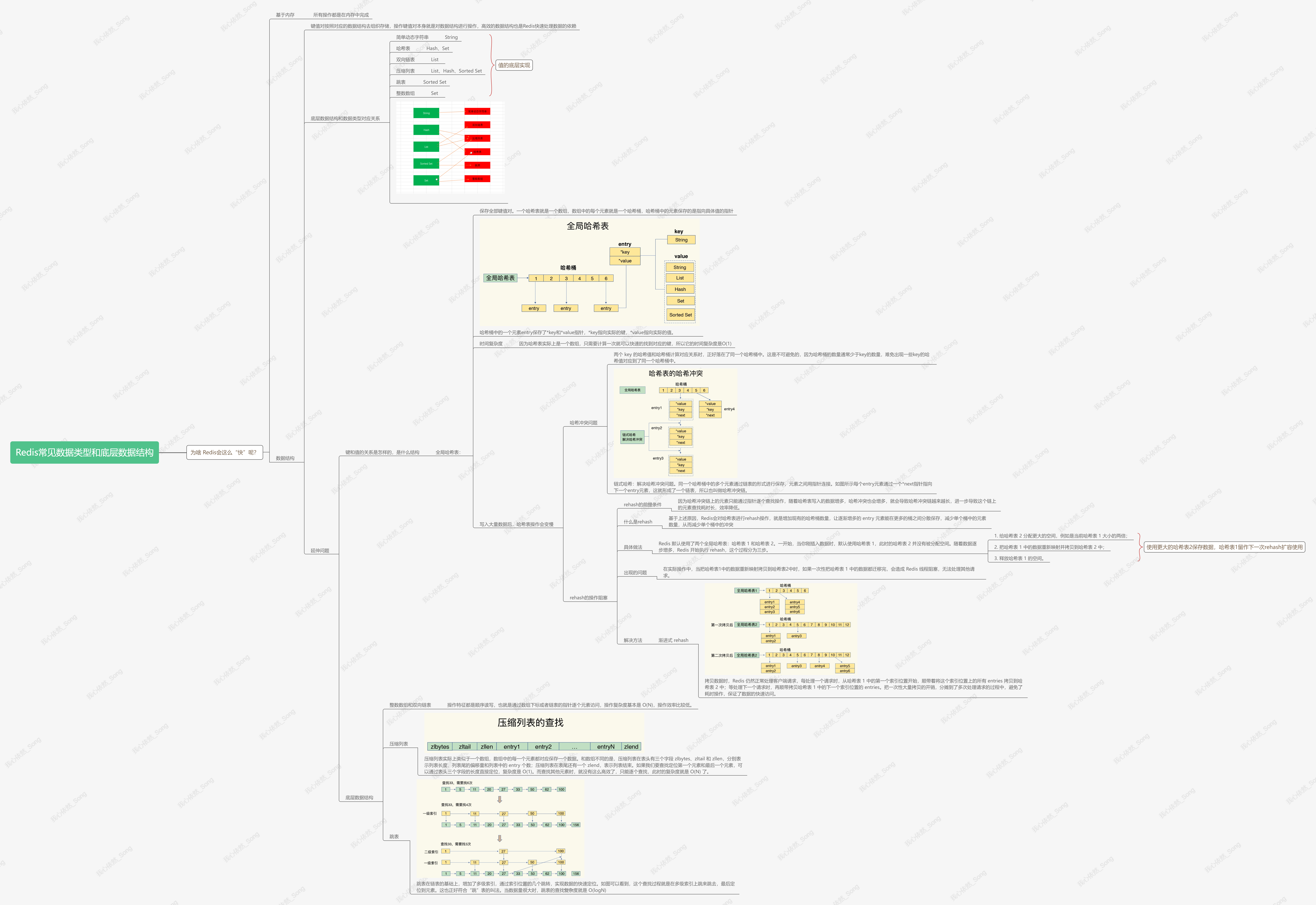
Redis 的快,到底是快在哪里呢?为什么会这么快呢?一方面它是内存数据库,所有操作都在内存上完成,内存的访问速度本身就很快。另一方面,这要归功于它的数据结构。因为键值对是按一定的数据结构来组织的,操作键值对最终就是对数据结构进行增删改查操作,所以高效的数据结构是 Redis 快速处理数据的基础。
常见数据类型和对应的底层数据结构
底层数据结构一共有 6 种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。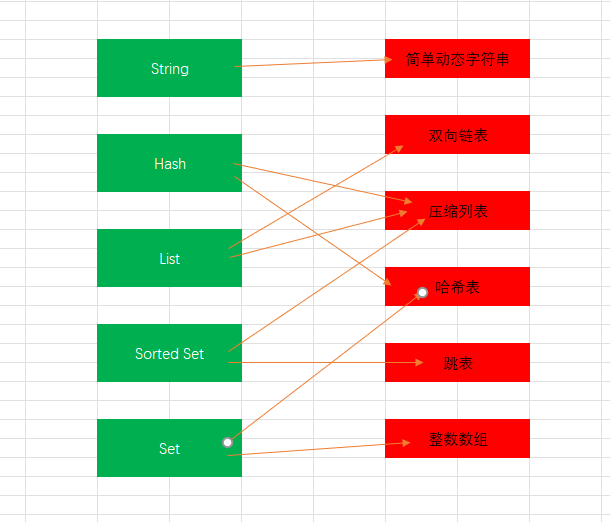
延伸问题
- 数据结构都是值的底层实现,键和值的关系是怎样的,是什么结构?
- 集合类型有多种底层结构,它们都是怎么组织数据的,都很快吗?
键和值的组织结构
Redis 使用了一个哈希表来保存所有键值对。哈希表就是一个数组,数组的每个元素称为一个哈希桶。一个哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据。这些键值对数据并不是值本身,而是指向具体值的指针。
这个哈希表保存了所有的键值对,所以,我也把它称为全局哈希表。
如图所示: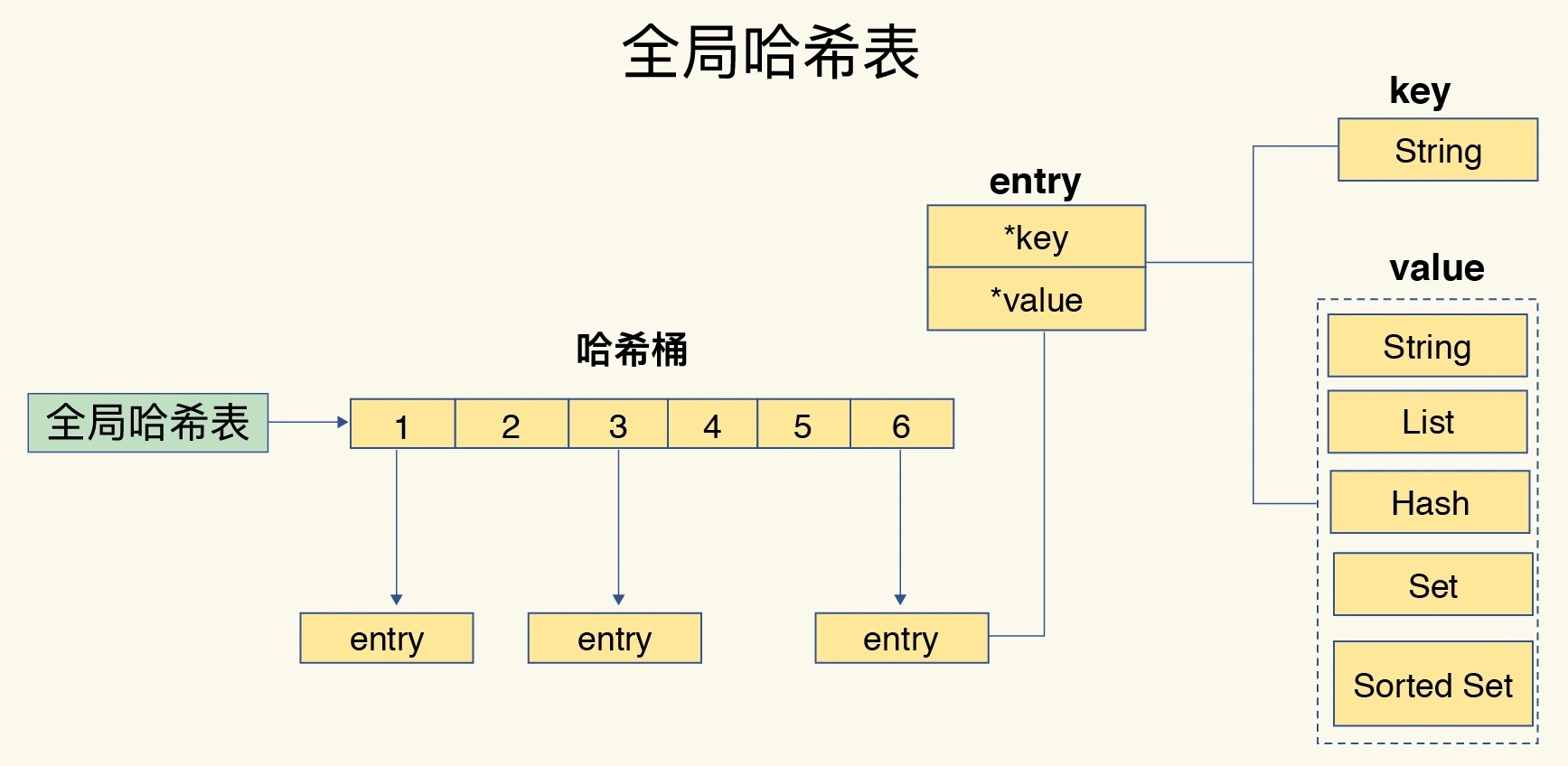
我们可以用 O(1) 的时间复杂度来快速查找到键值对——我们只需要计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
哈希表操作为啥会变慢?
-
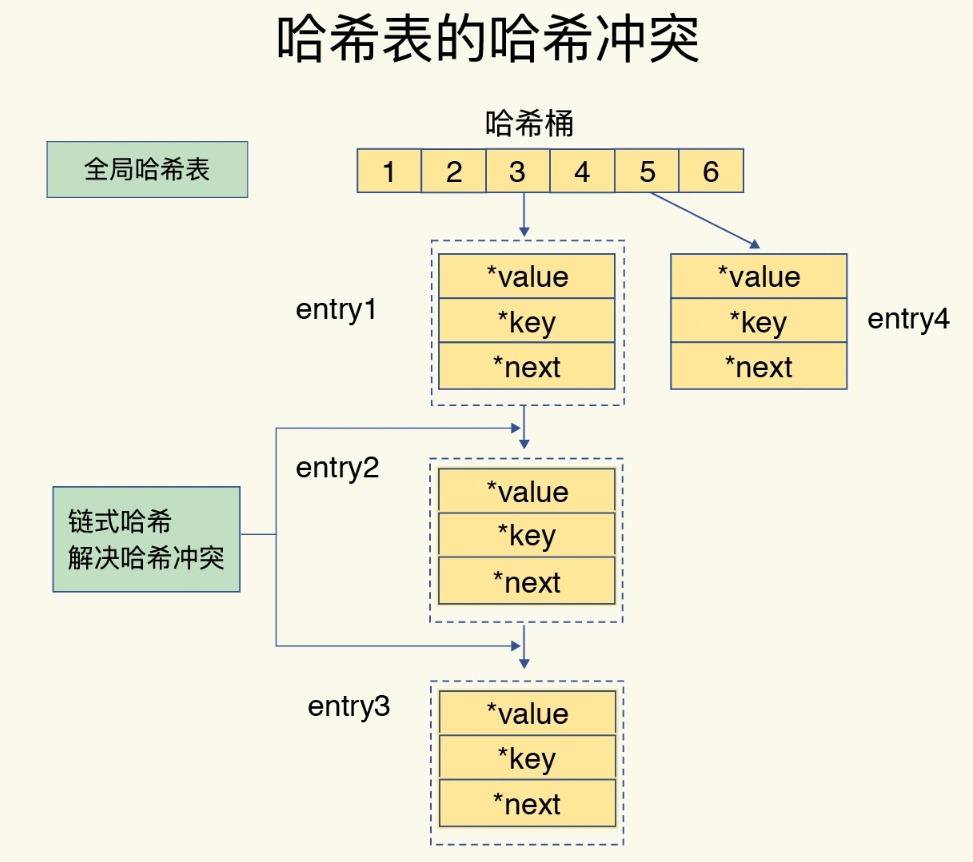
哈希冲突问题
哈希冲突是指,两个 key 的哈希值和哈希桶计算对应关系时,正好落在了同一个哈希桶中。 -
解决方法
链式哈希:就是指同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
如图所示每个entry元素通过一个*next指针指向下一个entry元素,这就形成了一个链表,所以也叫做哈希冲突链。
-
什么是rehash
因为哈希冲突链上的元素只能通过指针逐个查找操作,随着哈希表写入的数据增多,哈希冲突也会增多,就会导致哈希冲突链越来越长,进一步导致这个链上的元素查找耗时长,效率降低。
所以Redis会对哈希表进行rehash操作,就是增加现有的哈希桶数量,让逐渐增多的 entry 元素能在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突。
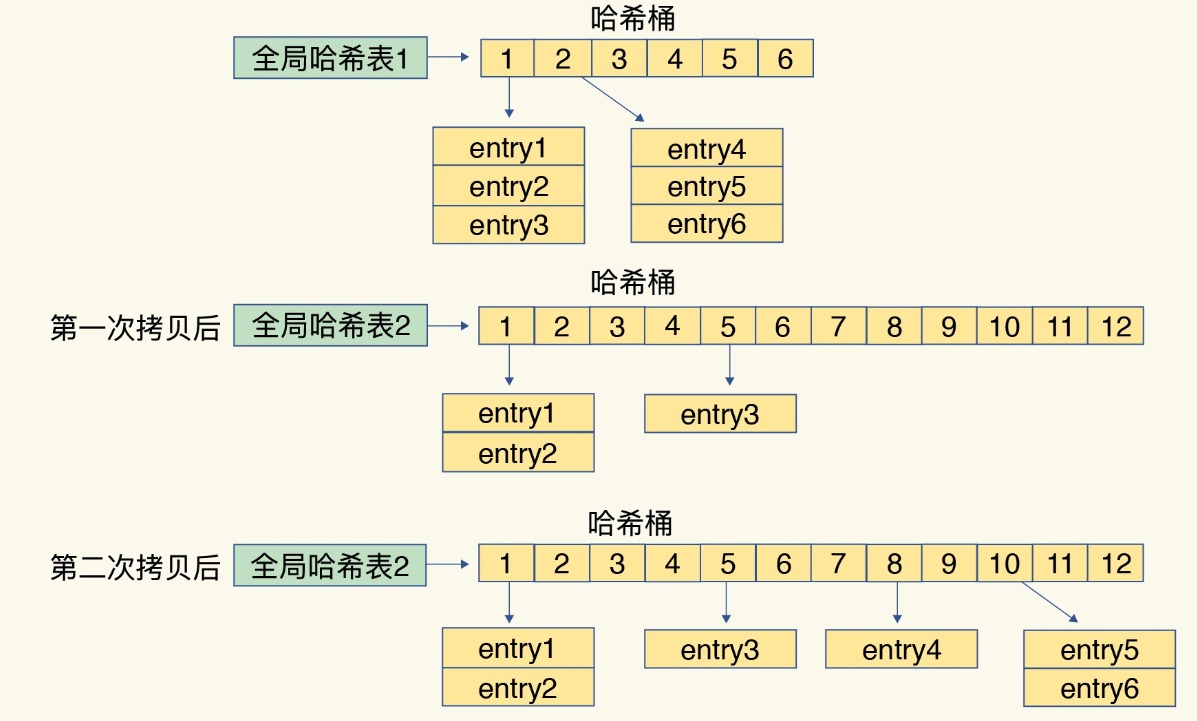
具体做法:Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步。- 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
- 释放哈希表 1 的空间。
在实际操作中,当把哈希表1中的数据重新映射拷贝到哈希表2中时,如果一次性把哈希表 1 中的数据都迁移完,会造成 Redis 线程阻塞,无法处理其他请求。
为了解决这个问题,Redis 采用了渐进式 rehash。
拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操作,保证了数据的快速访问。
底层数据结构
-
整数数组和双向链表
操作特征都是顺序读写,也就是通过数组下标或者链表的指针逐个元素访问,操作复杂度基本是 O(N),操作效率比较低。 -
压缩列表
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。 -
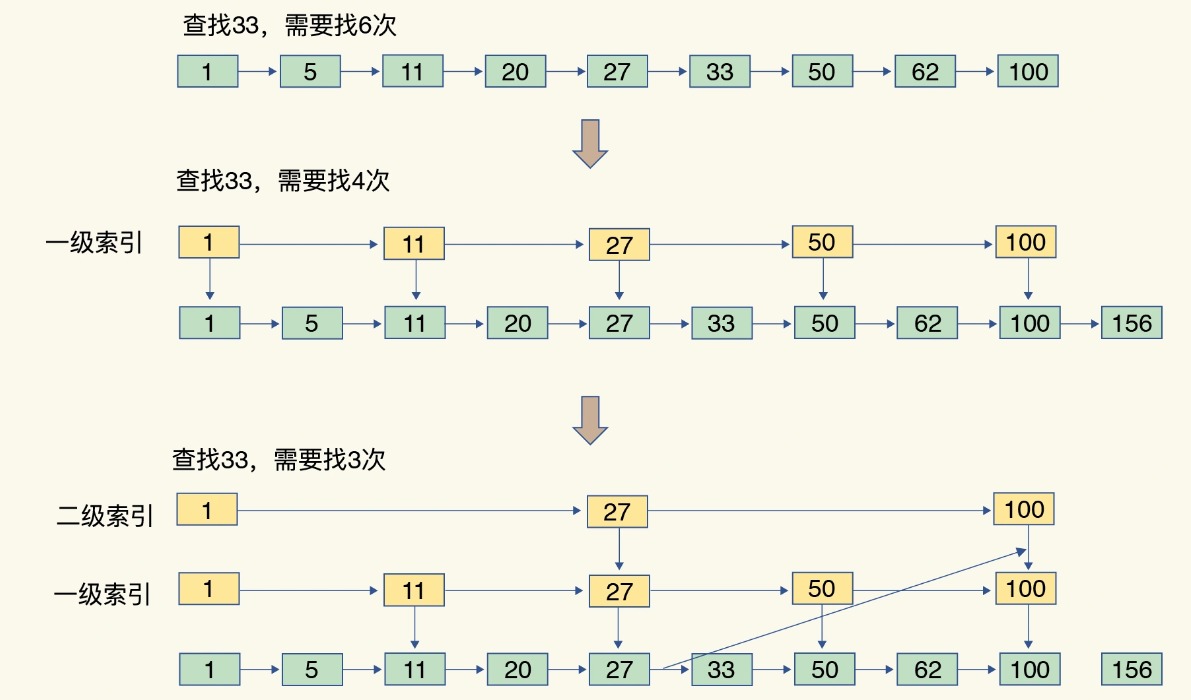
跳表
跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位。如图可以看到,这个查找过程就是在多级索引上跳来跳去,最后定位到元素。这也正好符合“跳”表的叫法。当数据量很大时,跳表的查找复杂度就是 O(logN)

总结
Redis 中使用全局哈希表结构来保存每个键值对。
五大底层结构:合类型实现的双向链表、压缩列表、整数数组、哈希表和跳表。
Redis 之所以能快速操作键值对,一方面是因为 O(1) 复杂度的哈希表被广泛使用,包括 String、Hash 和 Set,它们的操作复杂度基本由哈希表决定,另一方面,Sorted Set 也采用了 O(logN) 复杂度的跳表。不过,集合类型的范围操作,因为要遍历底层数据结构,复杂度通常是 O(N)。
复杂度较高的 List 类型,它的两种底层实现结构:双向链表和压缩列表的操作复杂度都是 O(N)。但是它的 POP/PUSH 效率很高,那么可把它主要用于 FIFO 队列场景,而不是作为一个可以随机读写的集合。
这篇关于Redis常见数据类型和底层数据结构的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-24Redis资料:新手入门快速指南
- 2024-12-24Redis资料:新手入门教程与实践指南
- 2024-12-24Redis资料:新手入门教程与实践指南
- 2024-12-07Redis高并发入门详解
- 2024-12-07Redis缓存入门:新手必读指南
- 2024-12-07Redis缓存入门:新手必读教程
- 2024-12-07Redis入门:新手必备的简单教程
- 2024-12-07Redis入门:新手必读的简单教程
- 2024-12-06Redis入门教程:从安装到基本操作
- 2024-12-06Redis缓存入门教程:轻松掌握缓存技巧



