3.联合索引、覆盖索引及最左匹配原则|MySQL索引学习
2022/4/20 8:12:40

本文主要是介绍3.联合索引、覆盖索引及最左匹配原则|MySQL索引学习,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
导语
在数据检索的过程中,经常会有多个列的匹配需求,今天介绍下联合索引的使用以及最左匹配原则的案例。
最左匹配原则作用在联合索引中,假如表中有一个联合索引(tcol01,tcol02,tcol03),只有当SQL使用到tcol01、tcol02索引的前提下,tcol03的索引才会被使用;同理只有tcol01的索引被使用的前提下,tcol02的索引才会被使用。
下面我们来列举几个例子来说明。
步骤
使用 mysql_random_data_load 创建测试数据
建库和建表
CREATE DATABASE IF NOT EXISTS test;
CREATE TABLE `test`.`t3` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`tcol01` tinyint(4) DEFAULT NULL,
`tcol02` smallint(6) DEFAULT NULL,
`tcol03` mediumint(9) DEFAULT NULL,
`tcol04` int(11) DEFAULT NULL,
`tcol05` bigint(20) DEFAULT NULL,
`tcol06` float DEFAULT NULL,
`tcol07` double DEFAULT NULL,
`tcol08` decimal(10,2) DEFAULT NULL,
`tcol09` date DEFAULT NULL,
`tcol10` datetime DEFAULT NULL,
`tcol11` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`tcol12` time DEFAULT NULL,
`tcol13` year(4) DEFAULT NULL,
`tcol14` varchar(100) DEFAULT NULL,
`tcol15` char(2) DEFAULT NULL,
`tcol16` blob,
`tcol17` text,
`tcol18` mediumtext,
`tcol19` mediumblob,
`tcol20` longblob,
`tcol21` longtext,
`tcol22` mediumtext,
`tcol23` varchar(3) DEFAULT NULL,
`tcol24` varbinary(10) DEFAULT NULL,
`tcol25` enum('a','b','c') DEFAULT NULL,
`tcol26` set('red','green','blue') DEFAULT NULL,
`tcol27` float(5,3) DEFAULT NULL,
`tcol28` double(4,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
建联合索引
CREATE INDEX idx_tcol123 ON t1(`tcol01`,`tcol02`,`tcol03`);
写入100w条测试数据
./mysql_random_data_load test t1 1000000 --user=root --password=GreatSQL --config-file=/data/GreatSQL/my.cnf
联合索引数据存储方式
先对索引中第一列的数据进行排序,而后在满足第一列数据排序的前提下,再对第二列数据进行排序,以此类推。
如下图:
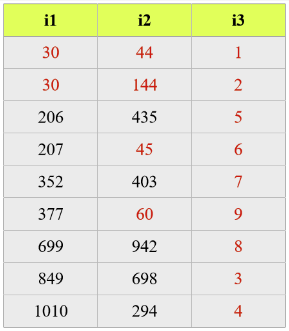
索引最左原则案例
情况1:三个索引都能使用上
实验1:仅有where子句
# 三个条件都使用上,优化器可以自己调整顺序满足索引要求 [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol02=167 AND tcol03=202019 AND tcol01=1; +----+-------------+-------+------------+------+---------------+-------------+---------+-------------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | ref | idx_tcol123 | idx_tcol123 | 9 | const,const,const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------------+------+----------+-------+ 1 row in set, 1 warning (0.11 sec) [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol02=167 AND tcol01=1 AND tcol03=202019 ; +----+-------------+-------+------------+------+---------------+-------------+---------+-------------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | ref | idx_tcol123 | idx_tcol123 | 9 | const,const,const | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------------+------+----------+-------+
实验2:WHERE 加 order by子句
# 解析出来只有用到tcol01,tcol02索引,由于`explain`不会统计`order by`索引的信息,所有看起来`key_len`长度只有5;当tcol03倒序的时候就会用到`Backward index scan`功能 [test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol01=1 AND tcol02=167 order by tcol03; +----+-------------+-------+------------+------+---------------+-------------+---------+-------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------+------+----------+-------+ | 1 | SIMPLE | t1 | NULL | ref | idx_tcol123 | idx_tcol123 | 5 | const,const | 269 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------+------+----------+-------+ 1 row in set, 1 warning (0.01 sec) [test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol01=1 AND tcol02=167 order by tcol03 desc; +----+-------------+-------+------------+------+---------------+-------------+---------+-------------+------+----------+---------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------+------+----------+---------------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_tcol123 | idx_tcol123 | 5 | const,const | 269 | 100.00 | Backward index scan | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------+------+----------+---------------------+ 1 row in set, 1 warning (0.00 sec) # 当order by中的字段不包含在联合索引中的时候,就会用到`Using filesort` [root@GreatSQL][test]>EXPLAIN SELECT /* NO_CACHE */ * FROM t1 WHERE tcol01=1 AND tcol02=167 order by tcol04; +----+-------------+-------+------------+------+---------------+-------------+---------+-------------+------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------+------+----------+----------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_tcol123 | idx_tcol123 | 5 | const,const | 269 | 100.00 | Using filesort | +----+-------------+-------+------------+------+---------------+-------------+---------+-------------+------+----------+----------------+ 1 row in set, 1 warning (0.00 sec)
实验3:仅order by子句
# 优化器默认采取全部扫描了,因为是查询出所有数据,所以全表扫描回比索引更快,节省回表的时间 [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 ORDER BY tcol01,tcol02,tcol03; +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 941900 | 100.00 | Using filesort | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+ 1 row in set, 1 warning (0.00 sec) [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 force index(`idx_tcol123`) ORDER BY tcol01,tcol02,tcol03; +----+-------------+-------+------------+-------+---------------+-------------+---------+------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+--------+----------+-------+ | 1 | SIMPLE | t1 | NULL | index | NULL | idx_tcol123 | 9 | NULL | 941900 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+--------+----------+-------+ 1 row in set, 1 warning (0.00 sec) # 只筛选索引列,也会使用到索引,也就是所谓的覆盖索引 [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ tcol01,tcol02,tcol03 FROM t1 ORDER BY tcol01,tcol02,tcol03; +----+-------------+-------+------------+-------+---------------+-------------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | index | NULL | idx_tcol123 | 9 | NULL | 941900 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) # 如果是筛选部分数据,那么就会使用到索引而不会全表扫描 [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 ORDER BY tcol01,tcol02,tcol03 limit 10000,11110; +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+-------+ | 1 | SIMPLE | t1 | NULL | index | NULL | idx_tcol123 | 9 | NULL | 21110 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+-------+ 1 row in set, 1 warning (0.00 sec) # 调整字段顺序后,就变成`Using filesort`且没有用到索引,所以当使用order by语句,确保与联合索引的顺序要一致 [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 ORDER BY tcol02,tcol01,tcol03 limit 10000,11110; +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 941900 | 100.00 | Using filesort | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+ 1 row in set, 1 warning (0.00 sec)
情况2:下面的SQL最多只能用到索引tcol1,tcol2部分
# tcol02范围查找后,导致数据乱序,于是tcol03索引条件用不上,同时回出现`Using index condition`和 `Using MRR`。 [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol01=1 AND tcol02>100 AND tcol03=202019; +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+----------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+----------------------------------+ | 1 | SIMPLE | t1 | NULL | range | idx_tcol123 | idx_tcol123 | 5 | NULL | 77976 | 10.00 | Using index condition; Using MRR | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+----------------------------------+ 1 row in set, 1 warning (0.00 sec) [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol01=1 AND tcol02>100; +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+----------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+----------------------------------+ | 1 | SIMPLE | t1 | NULL | range | idx_tcol123 | idx_tcol123 | 5 | NULL | 77976 | 100.00 | Using index condition; Using MRR | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+----------------------------------+ 1 row in set, 1 warning (0.00 sec) [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol01=1 AND tcol03=202019 ORDER BY tcol02; +----+-------------+-------+------------+------+---------------+-------------+---------+-------+--------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------------+---------+-------+--------+----------+-----------------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_tcol123 | idx_tcol123 | 2 | const | 126670 | 10.00 | Using index condition | +----+-------------+-------+------------+------+---------------+-------------+---------+-------+--------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) # 关掉`Using index condition`和`Using MRR`后再看一下执行计划,实际测试效率要高很多。 # 这是因为ICP减少了引擎层和server层之间的数据传输和回表请求,不满足条件的请求,直接过滤无需回表 # 实际上开启ICP后上面语句有用到tcol03的索引部分。 [root@GreatSQL][test]>SET optimizer_switch = 'MRR=off'; [root@GreatSQL][test]>SET optimizer_switch = 'index_condition_pushdown=off'; [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol01=1 AND tcol02>100 AND tcol03=202019; +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | range | idx_tcol123 | idx_tcol123 | 5 | NULL | 77976 | 10.00 | Using where | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) 1 row in set (1.81 sec) /* 关闭ICP和MRR后执行时间 */ 1 row in set (0.01 sec) /* 开启ICP和MRR后执行时间 */ [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol01=1 AND tcol02>100; +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | range | idx_tcol123 | idx_tcol123 | 5 | NULL | 77976 | 100.00 | Using where | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+-------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) 40252 rows in set (2.04 sec) /* 关闭ICP和MRR后执行时间 */ 40252 rows in set (1.58 sec) /* 开启ICP和MRR后执行时间 */ [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol01=1 AND tcol03=202019 ORDER BY tcol02; +----+-------------+-------+------------+------+---------------+-------------+---------+-------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-------------+---------+-------+--------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ref | idx_tcol123 | idx_tcol123 | 2 | const | 126670 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+-------------+---------+-------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) 1 row in set (1.99 sec) /* 关闭ICP和后执行时间 */ 1 row in set (0.01 sec) /* 开启ICP和后执行时间 */
Using index condition 请看文章 https://mp.weixin.qq.com/s/pt6mr3Ge1ya2aa6WlrpIvQ
Using MRR 后面再介绍。
情况3:下面的SQL用不到索引
[root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol02=167; +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 941900 | 10.00 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 WHERE tcol02=167 AND tcol03 >=1; +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 941900 | 3.33 | Using where | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.01 sec) [root@GreatSQL][test]>explain SELECT /* NO_CACHE */ * FROM t1 ORDER BY tcol02 limit 10000,11000; +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+ | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 941900 | 100.00 | Using filesort | +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+ 1 row in set, 1 warning (0.00 sec)
联合索引有哪些好处
- 1.减少开销。建一个联合索引
(tcol01, tcol02, tcol03),相当于建立三个索引(tcol01),(tcol01,tcol02),(tcol01,tcol02,tcol03)的功能。每个索引都会占用写入开销和磁盘开销,对于大量数据的表,使用联合索引会大大的减少开销。 - 2.覆盖索引。对联合索引
(tcol01, tcol02, tcol03),如果有如下的SQL:select tcol01,tcol02,tcol03 from t1 where tcol01=? and tcol02=? and tcol03=?那么就可以使用到覆盖索引的功能,查询数据无需回表,减少随机IO。 - 3.效率高。多列条件的查询下,索引列越多,通过索引筛选出的数据就越少。
联合索引使用建议
- 1.查询条件中的
where、order by、group by涉及多个字段,一般需要创建多列索引,比如前面的select * from t1 where tcol01=100 and tcol02=50; - 2.创建联合索引的时候,要将区分度高的字段放在前面,假如有一张学生表包含学号和姓名,那么在建立联合索引的时候,学号放在姓名前面,因为学号是唯一性的,能过滤更多的数据。
- 3.尽量避免
>、<、between、or、like首字母为%的范围查找,范围查询可能导致无法使用索引。 - 4.只筛选需要的数据字段,满足覆盖索引的要求,不要用
select *筛选所有列数据。
Enjoy GreatSQL :)
这篇关于3.联合索引、覆盖索引及最左匹配原则|MySQL索引学习的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2025-01-02MySQL 3主集群搭建
- 2024-12-25如何部署MySQL集群资料:新手入门教程
- 2024-12-24MySQL集群部署资料:新手入门教程
- 2024-12-24MySQL集群资料详解:新手入门教程
- 2024-12-24MySQL集群部署入门教程
- 2024-12-24部署MySQL集群学习:新手入门教程
- 2024-12-24部署MySQL集群入门:一步一步搭建指南
- 2024-12-07MySQL读写分离入门:轻松掌握数据库读写分离技术
- 2024-12-07MySQL读写分离入门教程
- 2024-12-07MySQL分库分表入门详解



