探索Snowflake auto clustering 设计
2022/5/1 8:12:39

本文主要是介绍探索Snowflake auto clustering 设计,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
Context
Snowflake IPO 大火之后大家开始慢慢了解到这个完全基于云架构而设计的新式数据仓库。
Snowflake 利用云端近似无限的计算和存储资源,基于存算分离的新式架构,真正实现了按需、按量的付费模式,极大的降低了用户的使用成本,让用户更加专注于数据价值的挖掘。对于传统的数据仓库来说,Snowflake 就像一块降维打击的二向箔。
在业务增长过程中,用户的数据持续增长,从而导致单表变大,查询的 SQL 模式也可能会发生变化,这时问题就出现了:之前比较快的查询现在变慢了。Snowflake 为了解决这个问题,提供了一个硬核功能:Auto Clustering,让你在建表时无需指定任何分区字段,而查询则越跑越快。这里我们就来探索下 Snowflake 的 Auto Clustering 机制是如何实现的。
什么是 Auto Clustering
Snowflake 的 Clustering 功能和传统数据的 Partition 功能类似。但在传统的数据库系统中,大多依赖一些静态的分区规则来实现数据的物理隔离,如按时间,按用户特征 hash 等等,在 Hive 等数据仓库中,最常见到的还是按照时间分区。当一个带有分区字段相关查询过来的时候,分区的裁剪可以直接忽略掉不匹配的数据,这样就可以大大减少了数据的读取和计算,从而提高查询性能。注意:这里的 Clustering 是指分组、聚类的意思,注意不要理解为分布式、集群等概念。
静态分区用法非常简单,比如在 Hive 中:
-- Create Partition ALTER TABLE table_name ADD PARTITION (dt='2020-03-26', hour='08') location '/path/table/20200326/08'; -- Then load data into the partition
开发人员在建表的时候必须知道数据的分布情况和将来面对的查询模式,增加了用户的心智负担。它有以下缺点:
- 静态分区的规则是固定的,但数据却是随时间在变化的,比如业务持续增长过程中,按天分区的表新的分区会变大,从而导致分区分布不均匀。
Snowflake 在设计中完全抛弃了传统的静态 Partition 概念,而是提出了 Auto Clustering 的新设计。简而言之,用户再也不用关心我的表是如何分区了,用户只管写入和查询就是,数据分组,性能优化我会自动做!
Micro Partition(微分区)
虽然抛弃了静态分区,但 Snowflake 里面还是有 Micro-Partition 和 Cluster Key 的概念。
-
Cluster Key 是排序键,可以由多个字段组成,类似 ClickHouse 的 Order Key。
-
Micro-Partition 是数据的基本组成单元,一个表的数据由多个 Micro-Partition 组成。我们可以将它理解为一个物理文件,这个物理文件限制在 50 MB-500 MB 的大小(未压缩),物理文件采用了列式存储,不同的列存储在不同的连续空间内。Snowflake 会存储 Micro-Partition 的信息到元数据服务中,方便查询时通过元数据索引进行剪枝,如:
• 每个列的区间索引,最大值、最小值等 (ZoneMap index)
• 列分布的直方图信息
• 其他…
Clustered Tables
数据表建立后,默认数据是自然序,自然序意味着我们没有做任何处理,数据就按照流入的顺序排列,此时表处于 Unclustered 状态。当表经历了 Clustering 后,每个 Micro-Partition 会按照指定的 Key 进行排序,可以理解为给表加了一个排序键,此时表处于 Clustered 状态。
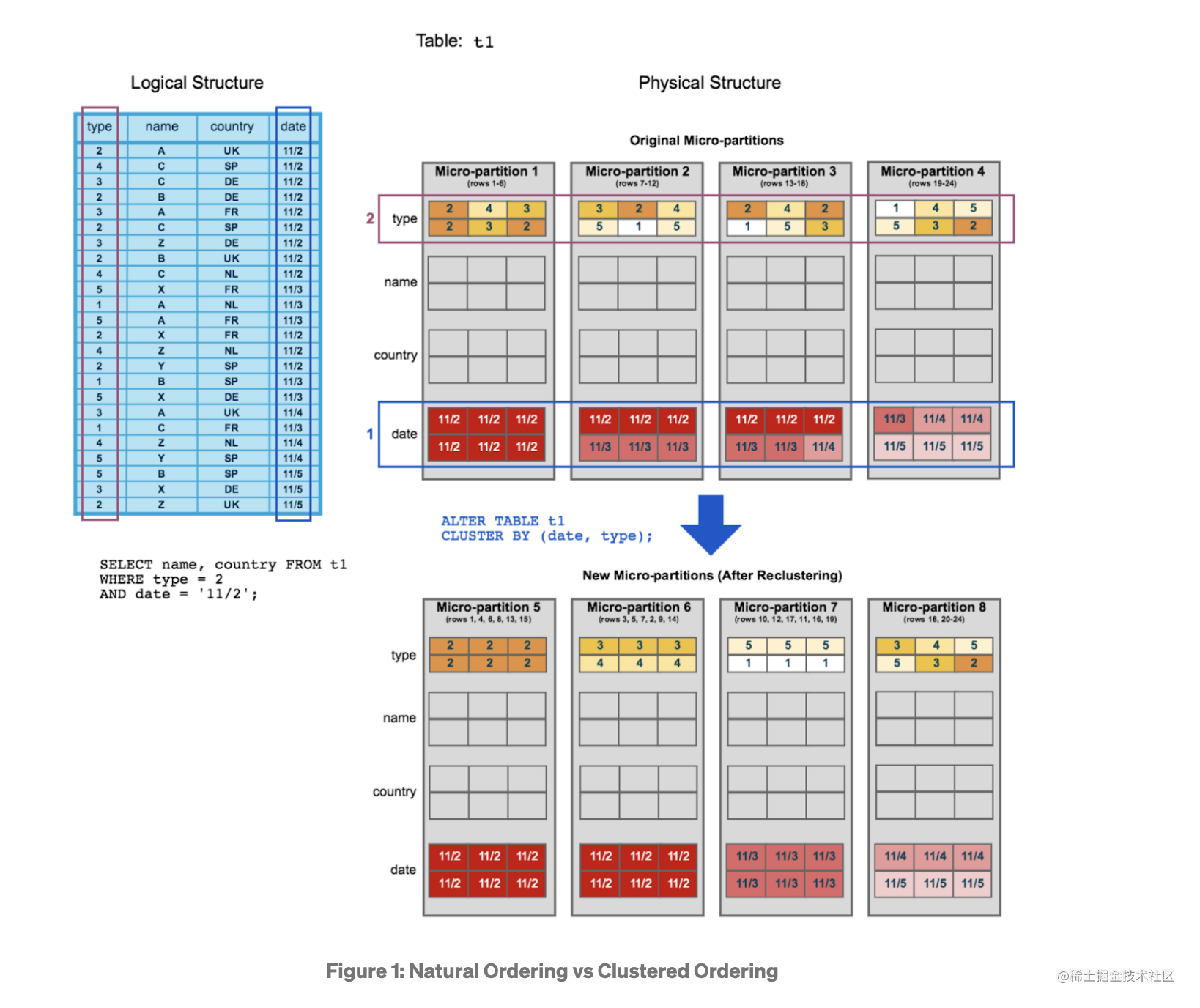
上图来自 Snowflake 文档。
Clustered 的主要目的是让大部分的查询能高效的裁剪数据,避免不需要的 IO 读取和计算。举个例子:
select name, country from t1 where type = 2 and date = '11/2';
怎样让表达到 Well-Clustered?在原始的数据排列中(自然序),上面的 SQL 会扫描到 4 个 Micro-Partition。而在 Clustered 状态下,数据已经按照 Cluster Key->(date, type) 进行排序,所以只会扫描到 1 个 Micro-Partition,其他的 Micro-Partition 都被引擎结合了存储在元数据的索引进行了裁剪过滤。
一般来说,大表不会是静态的数据,大多会是时序数据,也就是说数据不断地实时流入。因此,对整个表级别的数据全排序是非常不现实的,不仅代价较高,实时流入的数据也会影响全排序结果。另外一种方法是只对流入的数据进行排序,这样虽然新数据有比较好的顺序,但随着数据在不断地流入,数据整体的顺序会逐渐趋于混乱。
结合上面的分析,一个表如果能达到 Well-Clustered(表数据的整体有序度高),这样查询才能高效。在这个前提下,还需要保证“新数据能实时高效流入”(确保 DML 高效),两者之间存在一个平衡点,Snowflake 的做法是优先保证新数据能实时高效流入,新数据是不需要对数据整体的有序度“负责”,因为新数据相比历史数据来说量级较小,影响的有序度也较小,它只需保证局部有序就行了(确保新数据查询也能高效)。新数据在后台会异步进行合并,保证“表数据的整体有序度高”,也就是说,数据的整体有序是一个渐进的过程,而不是整体绝对有序的。
如何衡量 Well-Clustered ?
Snowflake 引入了几个主要的指标来衡量表的 Well-Clustered 程度:
- Overlaps: 在一个 Range 范围内,有多少个 Micro-Partition 有重叠
- Depth: 在一个数据点中,有多少个 Micro-Partition 有重叠
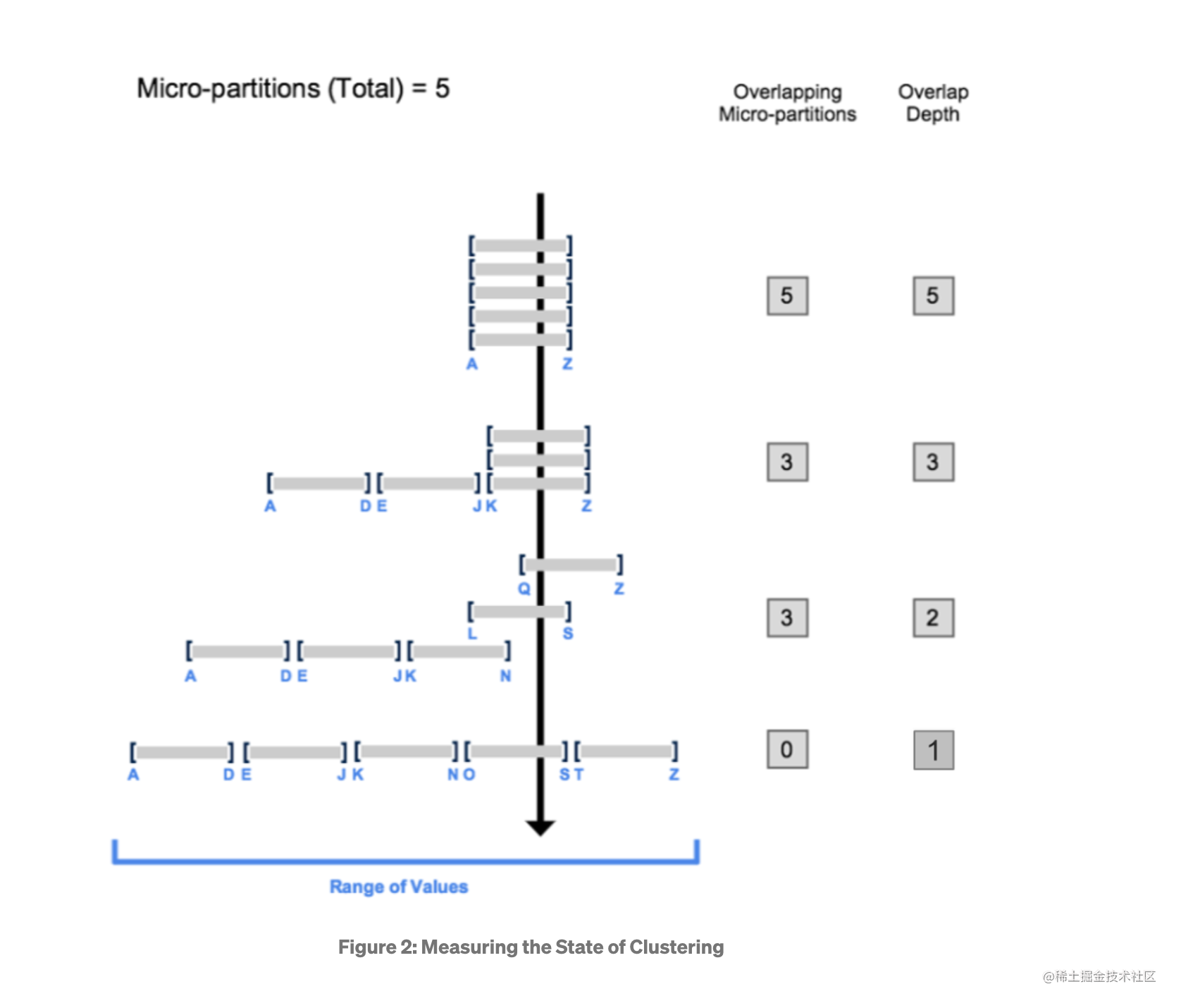
上面的图从上到下展示了四种表 Cluster 的状态,第一种情况是 4 个Micro-Partition 完全重叠,这种情况是最糟糕的,因为它没有任何区分度,命中了 A-Z 这个 Range 的查询会不可避免地扫描四个分区。随着 Depth 指标的下降,表中 Micro-Partition 变得逐渐离散,Overlaps 指标也在下降,表也逐渐变得更加 Well-Clustered。
当然,在实际的表分布中,Micro-Partition 的分布要达到最下面那样规整(全局有序)是不现实的,因为所需要的开销太大了。
- levels:Micro-Partition 所属的级别
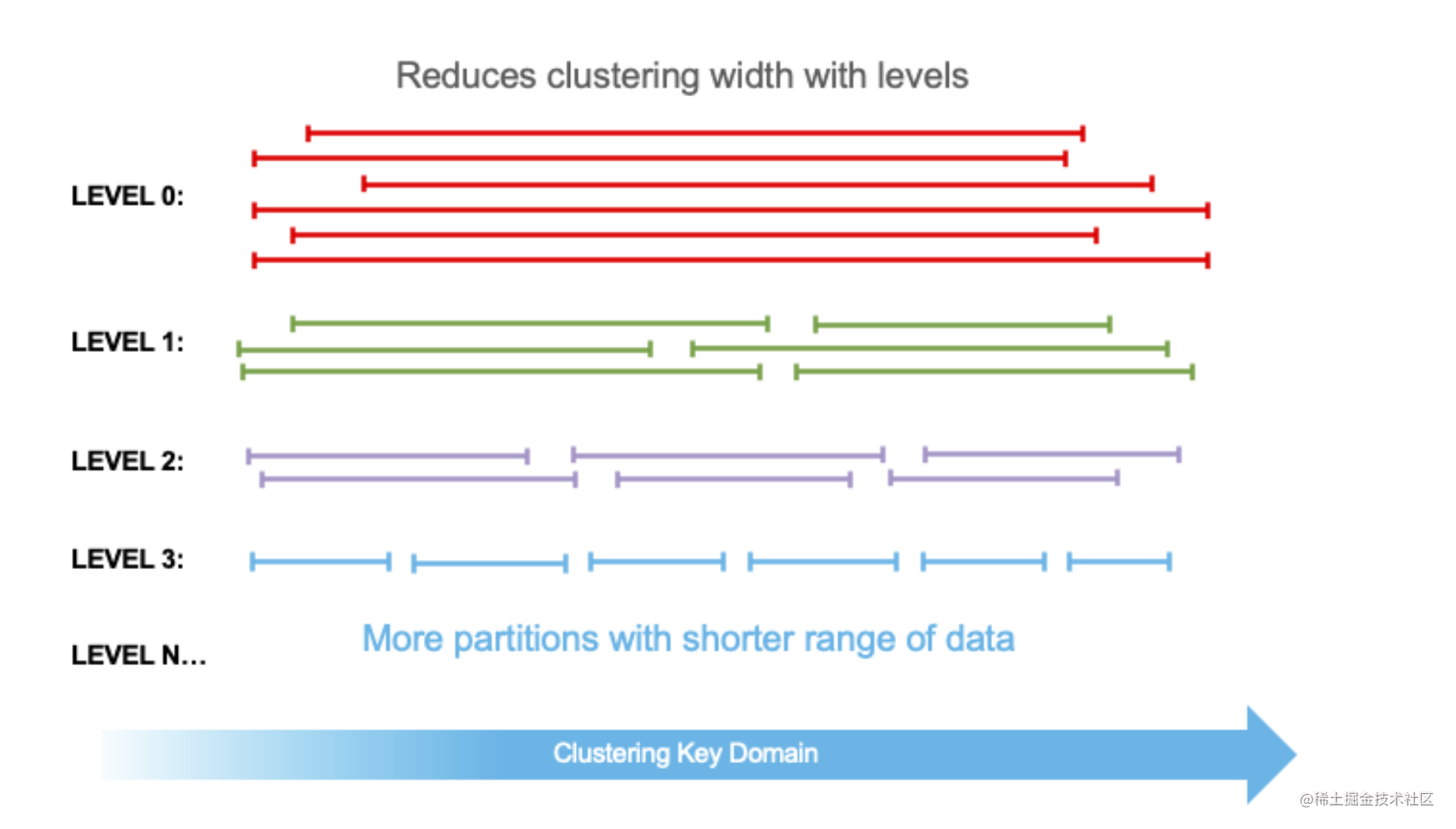
为了减少写放大,Micro-Partition 的合并策略和 LSM-tree 类似,Micro-Partition 在后台不断地合并后形成新的 Micro-Partition,每次合并完成后,Micro-Partition 的 Level 值就会自增(clickhouse 也有类似的 Part 合并逻辑),所以 Level 表示的就是 Micro-Partition 经历过的合并次数(用来衡量经历过的合并成本)。新数据流入的 Micro-Partition Level 默认是 0,Level 越低的 Micro-Partition 中,Overlaps 和 Depth 指标相对来说会越高,在不断合并的过程中,Micro-Partition 变得越来越离散,表也变得更加 Well-Clustered。
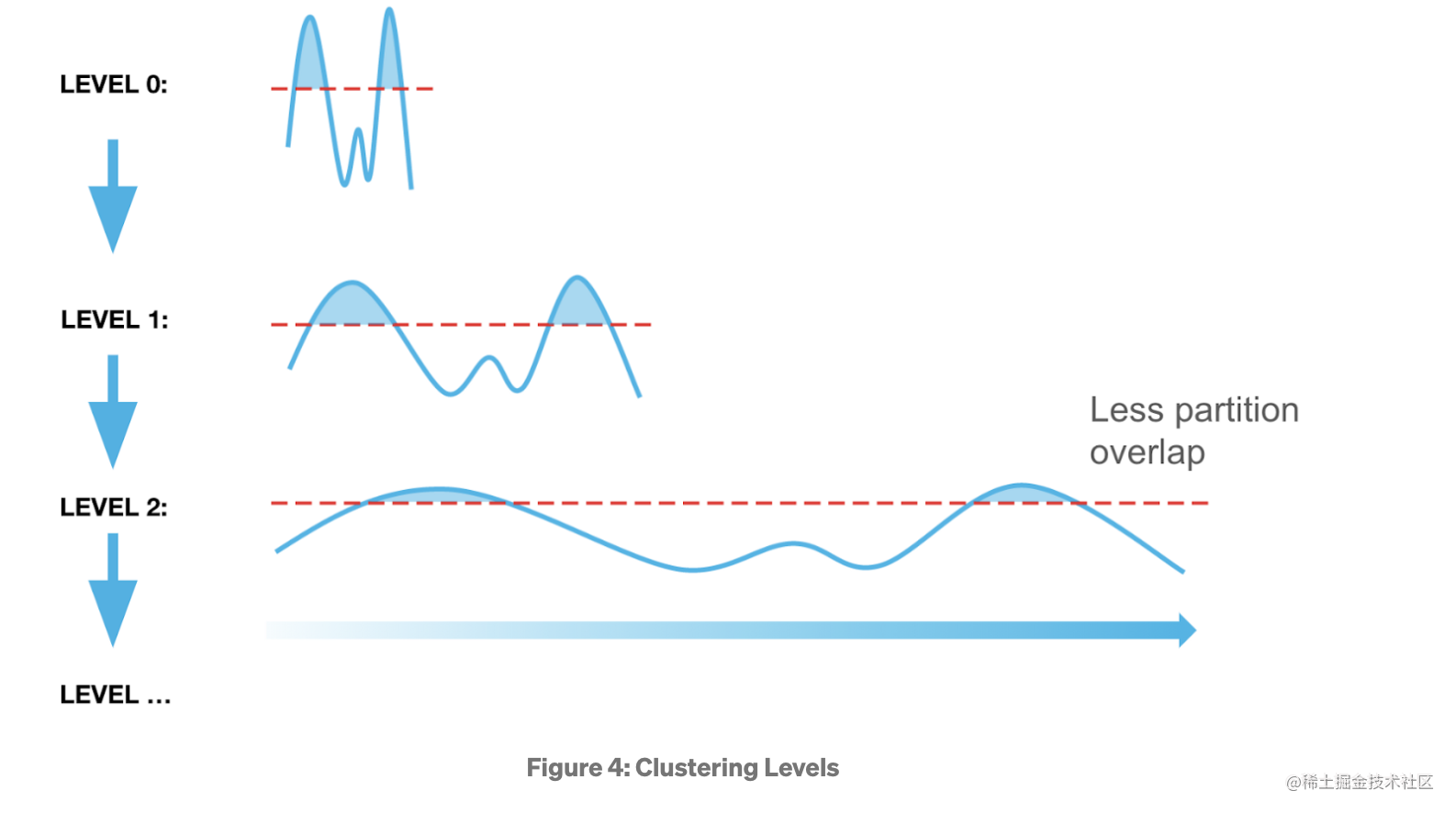
注意:Micro-Partition 只会和同 Level 的 Micro-Partition 合并, Level 存在最大值,避免写放大太严重。Auto Clustering 是如何进行的
Auto Clustering 是如何进行的
Auto Clustering 主要分为两大任务:
- Part-Selection 任务
- Part-Merge 任务
这块和 ClickHouse 的逻辑很类似,但明显的区别是 Snowflake 对云实在太偏爱了,上面所有的任务都可以在云端拉起独立的进程进行,而不需要占用用户的计算资源,并且这两个进程也是微服务化的,可以按需弹性伸缩。
Part-Selection 任务
Selection 任务会从某个 Level 中选择出 Micro-Partition 列表集合,选择的策略是启发式的。
上面提到的 2 个指标可以构建一个启发式的算法:
- Level 低的 Micro-Partition 被选择的优先级高,因此新流入的数据能有较高优先级合并到下个 Level,Level 越高的 Micro-Partition 除非在有充足的资源情况下,否则不会被合并。
- Depth 高的 Micro-Partition 被选择的优先级高。
因此 Selection 的目标就是降低 Level 中 Micro-Partition 的平均深度,AvgDepth。AvgDepth 又是如何计算的呢?
下面四个 Micro-Partition 的情况下:

我们对每个端点进行分析,如果没有 overlap,depth 忽略,因为 depth 的目的就是衡量 overlap 的程度,引入 depth=0 会导致数据有偏差,此时 depth 表示一个端点覆盖了几个分区。
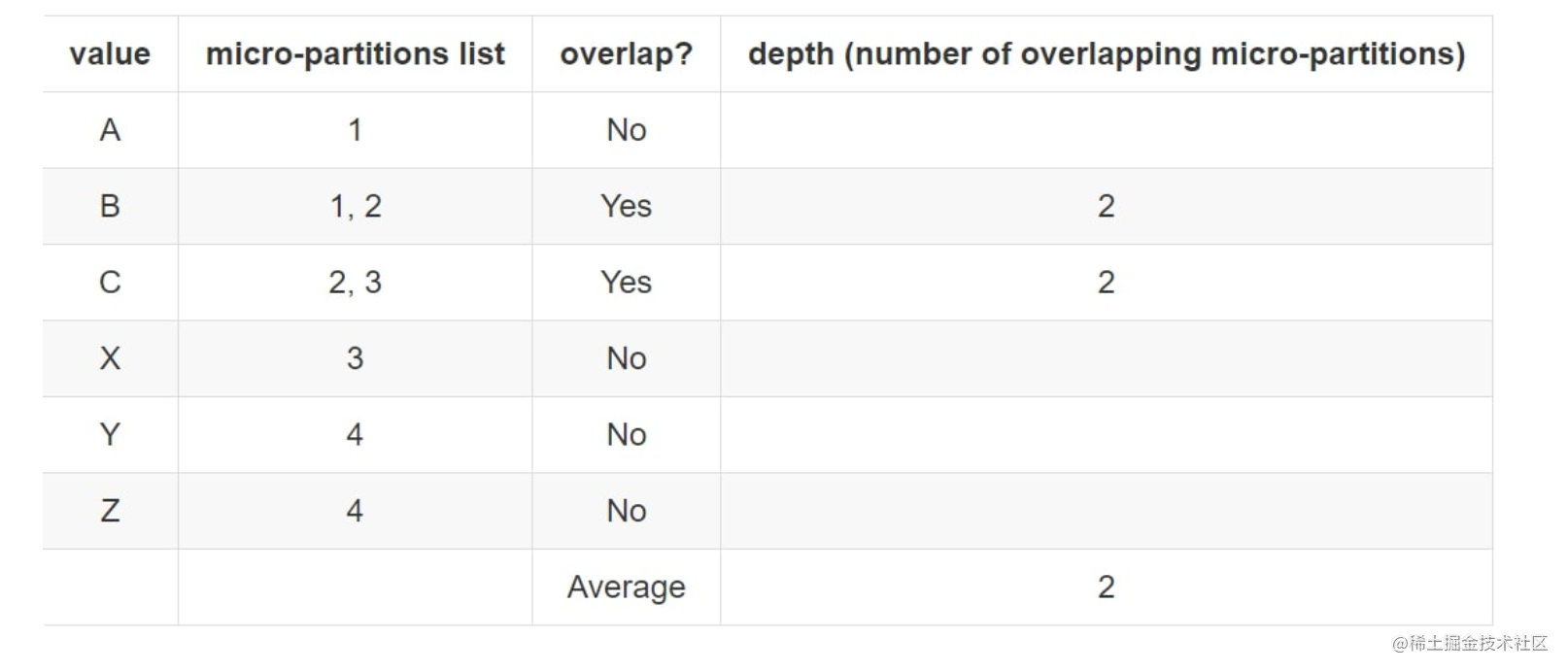
最终的计算方式是:
AvgDepth = Sum(DepthOfOverflapPoint) / OverflapPointsCnt
Snowflake 没有公开具体的 Selection 算法,不过大概是 Level+AvgDepth 结合的一个公式进行排序,我们假设它是以每个 Level 的 AvgDepth 排序选择某个 Level,然后去顺序遍历此 Level 下的所有端点,超过了 AvgDepth 的连续端点会被选择作为 Range。
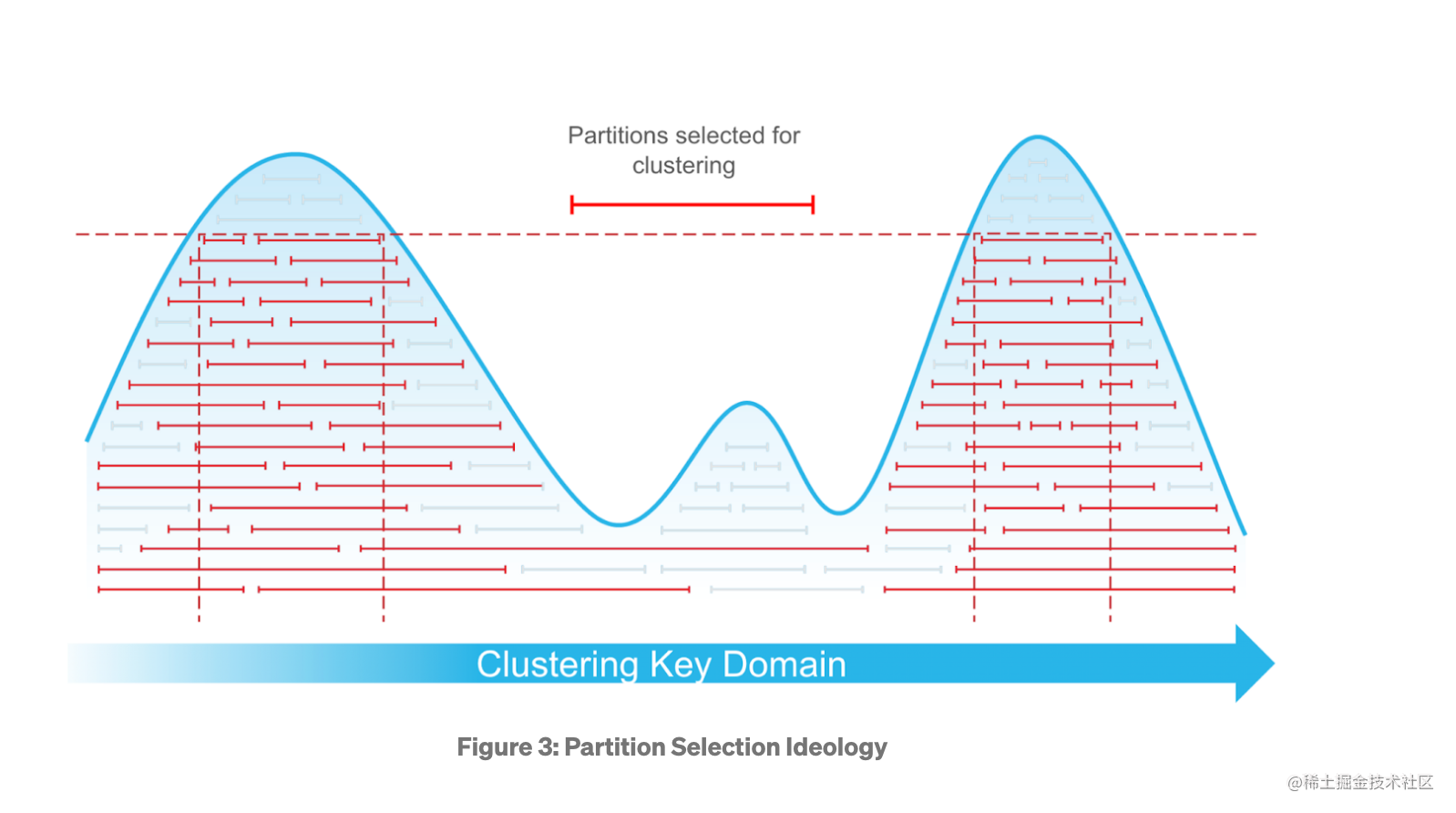
-
上面的曲线是如何构建的?
横轴对应的就是 Key 的 Range,纵轴表示 Depth,计算方式大概是:遍历所有的 Micro-Partition,将 Micro-Partition 的 Range 的 Depth 进行求和(即上面的 DepthOfOverflapPoint ),得出对应端点的 Y 值(这里应该可以用差分数组的数据结构进行优化) -
选择的策略是什么?
上图是选择了两个 Micro-Partition 列表的集合示例,选择的方式是顺序遍历所有的端点,如果端点的 Depth 超过了 AvgDepth,就会被选择,连续选择的端点构成一个 Range。 -
为什么不直接选最高的 Depth?
可以发现最高点 Depth 虽然最高,但覆盖的 Range 变窄,这样导致选择的 Micro-Partition 数量太小,对降低 AvgDepth 的影响较少。 -
选择的结果是什么?
看有多少个符合条件的波峰,上图是两个符合条件的波峰,这两个波峰互不重合,可以作为选择的结果集合,集合中内包含了 Micro-Partition 的 batches。
ClickHouse 中也有类似的选择策略算法,建议读者有时间也可以去了解下。
Part-Merge 任务
接收到 Selection 的列表后,Part-Merge 可以独立地进行 Micro-Partition 的排序和合并,类似一个归并排序的过程。合并后的 Micro-Partition 就是一个全局有序的大 Micro-Partition 了。值得一提的是,合并后的分区如果超过了 500 MB 的阈值上限,就会被分裂成更小的 Micro-Partition,这和 ClickHouse 存储一个大的分区文件是不同的。
猜测可能是:
- Snowflake 和 ClickHouse 不一样, 它不再维护 Micro-Partition 内部的稀疏索引,稀疏索引的最小粒度就是 Micro-Partition。
- 在云端对象存储中,读取整个 Micro-Partition 比在 Micro-Partition 内部进行部分 Range 虽然 IO 开销稍大,但差异不会太大,而且对象存储一般都有对象级别的 Cache,所以 Snowflake 的元数据只存储了 Micro-Partition 粒度的索引。
其他
- 收费
Snowflake 的 Auto Clustering 虽然没有使用客户的计算资源,但费用还是要算在用户头上的,在 Billing & Usage 页面可以看到对应的计费情况。
- 易用性
目前,市面上大部分数据仓库都需要用户在建表时指定分区字段,预先判断数据的分布情况,这无疑加重了用户的使用负担,如果查询模式跟分区无关,做查询优化则非常困难,Auto Clustering 则很好的解决了这些问题。
Databend 社区也在研发 Auto Clustering 功能,通过技术创新不断提升产品的易用性和智能性。
相关配图,参考文章来源:
• Automatic Clustering at Snowflake
• How does automatic clustering work in Snowflake
• zero-to-snowflake-automated-clustering-in-snowflake
这篇关于探索Snowflake auto clustering 设计的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-11-23增量更新怎么做?-icode9专业技术文章分享
- 2024-11-23压缩包加密方案有哪些?-icode9专业技术文章分享
- 2024-11-23用shell怎么写一个开机时自动同步远程仓库的代码?-icode9专业技术文章分享
- 2024-11-23webman可以同步自己的仓库吗?-icode9专业技术文章分享
- 2024-11-23在 Webman 中怎么判断是否有某命令进程正在运行?-icode9专业技术文章分享
- 2024-11-23如何重置new Swiper?-icode9专业技术文章分享
- 2024-11-23oss直传有什么好处?-icode9专业技术文章分享
- 2024-11-23如何将oss直传封装成一个组件在其他页面调用时都可以使用?-icode9专业技术文章分享
- 2024-11-23怎么使用laravel 11在代码里获取路由列表?-icode9专业技术文章分享
- 2024-11-22怎么实现ansible playbook 备份代码中命名包含时间戳功能?-icode9专业技术文章分享



