【Redis】10道不得不会的Redis面试题
2022/6/18 4:20:13

本文主要是介绍【Redis】10道不得不会的Redis面试题,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
博主介绍: 🚀自媒体 JavaPub 独立维护人,全网粉丝15w+,csdn博客专家、java领域优质创作者,51ctoTOP10博主,知乎/掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和副业。🚀
以下是 Redis 面试题,相信大家都会有种及眼熟又陌生的感觉、看过可能在短暂的面试后又马上忘记了。JavaPub在这里整理这些容易忘记的重点知识及解答,建议收藏,经常温习查阅。
评论区见
@[toc]
Spring
1. Redis是什么?
一般问这个问题你最少要答出以下几点
Redis 是一个基于内存的 key-value 存储系统,数据结构包括字符串、list、set、zset(sorted set --有序集合)和hash,bitmap,GeoHash(坐标),HyperLogLog,Streams(5.x版本以后)
2. 你在哪些场景使用redis
你有实战经验,那就直接表演。如果没有,选几个下面的经典场景
- 作为队列使用,(因为是基于内存、一般不会作为消费队列、作为循环队列必要适用);
- 模拟类似于token这种需要设置过期时间的场景,登录失效;
- 分布式缓存,避免大量请求底层关系型数据库,大大降低数据库压力;
- 分布式锁;
- 基于 bitmap 实现布隆过滤器;
- 排行榜-基于zset(有序集合数据类型);
- 计数器-对于浏览量、播放量等并发较高,使用 redis incr 实现计数器功能;
- 分布式会话;
- 消息系统;
3. 为什么Redis是单线程的?
这个问题给一个官方答案
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
4. Redis持久化有几种方式?
redis 提供了两种持久化的方式,分别是快照方式(RDB Redis DataBase)和文件追加(AOF Append Only File)。
显而易见,快照方式重启恢复快、但是数据更容易丢失,文件追加数据更完整、重启恢复慢。
混合持久化方式,Redis 4.0之后新增的方式,混合持久化是结合RDB和AOF的优点,在写入的时候先把当前的数据以RDB的形式写入到文件的开头,再将后续的操作以AOF的格式存入文件当中,这样既能保证重启时的速度,又能降低数据丢失的风险。
在恢复时,先恢复快照方式保存的文件,然后再恢复追加文件中的增量数据。
5. 什么是缓存穿透?怎么解决?
缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空。
如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统。
这就叫做缓存穿透。
怎么解决?
-
对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert之后清理缓存。
-
对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该Bitmap过滤。
6. 什么是缓存雪崩?
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
怎么解决?
常用的解决方案有:
- 均匀过期
- 加互斥锁
- 缓存永不过期
- 双层缓存策略
均匀过期:设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
加互斥锁:跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
缓存永不过期:跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
双层缓存策略:使用主备两层缓存:
主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值。
备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。
7. Redis使用上如何做内存优化?
- 缩短键值的长度
- 缩短值的长度才是关键,如果值是一个大的业务对象,可以将对象序列化成二进制数组;
- 首先应该在业务上进行精简,去掉不必要的属性,避免存储一些没用的数据;
- 其次是序列化的工具选择上,应该选择更高效的序列化工具来降低字节数组大小;
- 以JAVA为例,内置的序列化方式无论从速度还是压缩比都不尽如人意,这时可以选择更高效的序列化工具,如: protostuff,kryo等
- 共享对象池
对象共享池指Redis内部维护[0-9999]的整数对象池。创建大量的整数类型redisObject存在内存开销,每个redisObject内部结构至少占16字节,甚至超过了整数自身空间消耗。所以Redis内存维护一个[0-9999]的整数对象池,用于节约内存。 除了整数值对象,其他类型如list,hash,set,zset内部元素也可以使用整数对象池。因此开发中在满足需求的前提下,尽量使用整数对象以节省内存。
- 字符串优化
因为redis的惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。尽量做新增不做更新。
- 编码优化
所谓编码就是具体使用哪种底层数据结构来实现。编码不同将直接影响数据的内存占用和读写效率。
这个需要掌握redis底层的数据结构。下图作为参考:
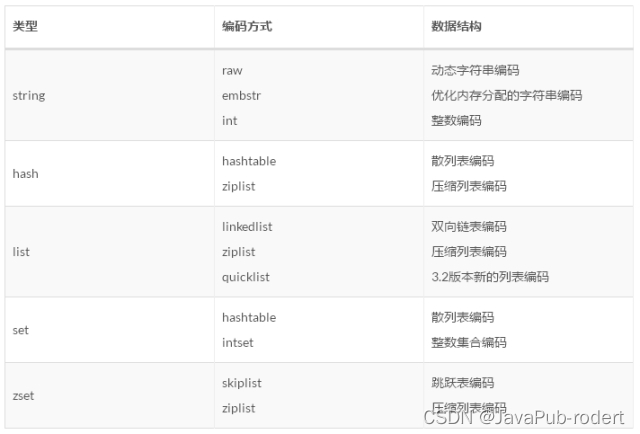
- 控制key的数量
8. 你们redis使用哪种部署方式?
redis部署分为单节点、主从部署(master-slave)、哨兵部署(Sentinel)、集群部署(cluster)。
单节点:也就是单机部署;
主从部署:分为一主一从或一主多从,主从之间同步分为全量或增量。量同步:master 节点通过 BGSAVE 生成对应的RDB文件,然后发送给slave节点,slave节点接收到写入命令后将master发送过来的文件加载并写入;增量同步:即在 master-slave 关系建立开始,master每执行一次数据变更的命令就会同步至slave节点。一般会将写请求转发到master,读请求转发到slave。提高了redis的性能。
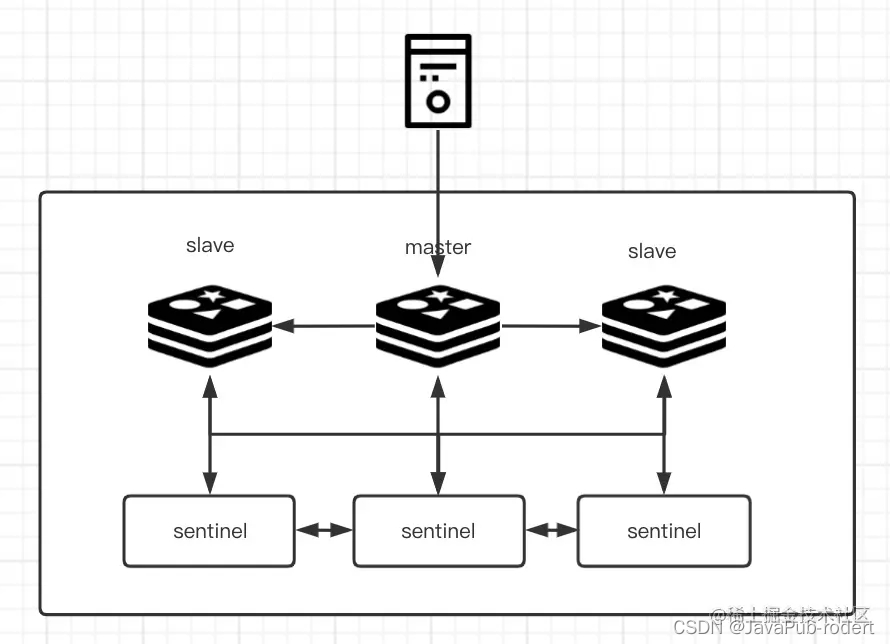
哨兵部署:分别有哨兵集群与Redis的主从集群,哨兵作为操作系统中的一个监控进程,对应监控每一个Redis实例,如果master服务异常(ping pong其中节点没有回复且超过了一定时间),就会多个哨兵之间进行确认,如果超过一半确认服务异常,则对master服务进行下线处理,并且选举出当前一个slave节点来转换成master节点;如果slave节点服务异常,也是经过多个哨兵确认后,进行下线处理。提高了redis集群高可用的特性,及横向扩展能力的增强。
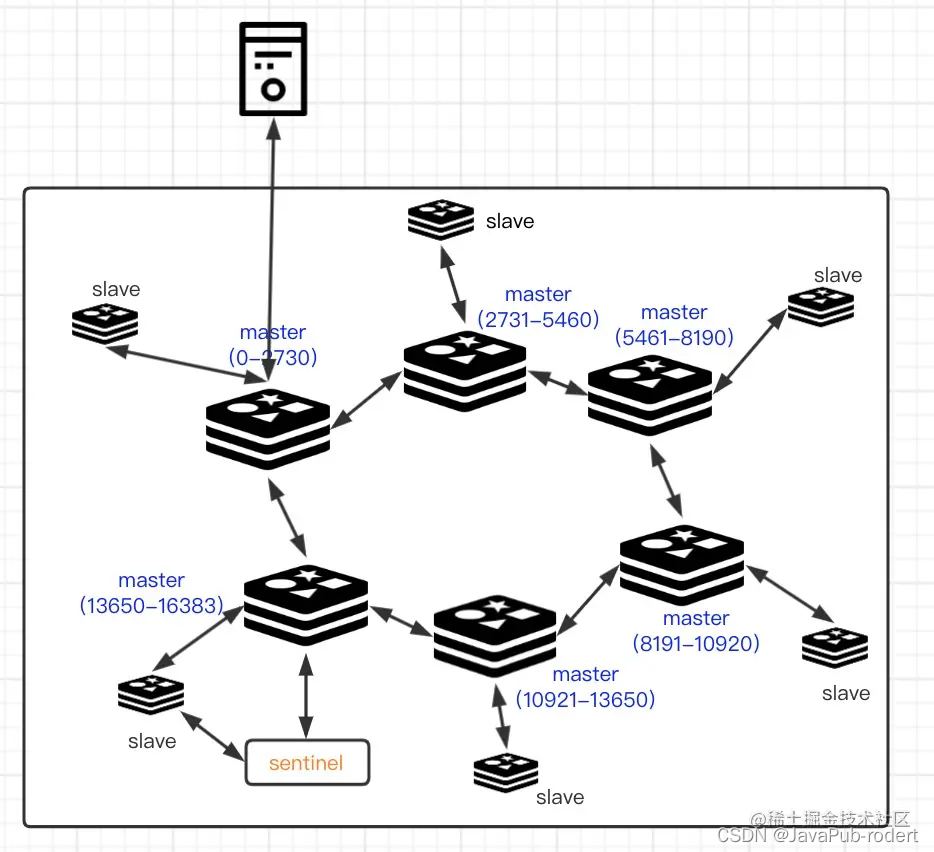
集群部署:属于**“去中心化”**的一种方式,多个 master 节点保存整个集群中的全部数据,而数据根据 key 进行 crc-16 校验算法进行散列,将 key 散列成对应 16383 个 slot,而 Redis cluster 集群中每个 master 节点负责不同的slot范围。每个 master 节点下还可以配置多个 slave 节点,同时也可以在集群中再使用 sentinel 哨兵提升整个集群的高可用性。
9. redis实现分布式锁要注意什么?
- 加锁过程要保证原子性;
- 保证谁加的锁只能被谁解锁,即Redis加锁的value,解锁时需要传入相同的value才能成功,保证value唯一性;
- 设置锁超时时间,防止加锁方异常无法释放锁时其他客户端无法获取锁,同时,超时时间要大于业务处理时间;
使用Redis命令 SET lock_key unique_value NX EX seconds 进行加锁,单命令操作,Redis是串行执行命令,所以能保证只有一个能加锁成功。
低谷蓄力
这篇关于【Redis】10道不得不会的Redis面试题的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-24Redis资料:新手入门快速指南
- 2024-12-24Redis资料:新手入门教程与实践指南
- 2024-12-24Redis资料:新手入门教程与实践指南
- 2024-12-07Redis高并发入门详解
- 2024-12-07Redis缓存入门:新手必读指南
- 2024-12-07Redis缓存入门:新手必读教程
- 2024-12-07Redis入门:新手必备的简单教程
- 2024-12-07Redis入门:新手必读的简单教程
- 2024-12-06Redis入门教程:从安装到基本操作
- 2024-12-06Redis缓存入门教程:轻松掌握缓存技巧



