x.ai还是OpenAI?埃隆·马斯克的AI帝国【2】
2023/6/11 21:22:08

本文主要是介绍x.ai还是OpenAI?埃隆·马斯克的AI帝国【2】,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
上期内容咱们提到了埃隆马斯克的特斯拉是自动驾驶领域的领导者,大家可能近些年也都有从各类渠道听到过Tesla自动驾驶有关的新闻。不同于像包括Google子公司Waymo在内的大多数使用激光雷达来实现自动驾驶的公司,特斯拉采用的是只需要视频输入就能理解汽车周围环境,并实现自动驾驶的方法。在2021年的计算机视觉和模式识别会议CVPR 2021的自动驾驶研讨会,特斯拉首席人工智能科学家Andrej Karpathy详细介绍了特斯拉的这套基于深度学习的自动驾驶系统。
神经网络算法,如deep neural networks等,是自动驾驶领域的主要技术,但是深度学习在检测图像中的物体时也会出错。反对纯计算机视觉方法的主要论点是,神经网络是否可以在没有激光雷达深度图帮助的情况下进行测距和深度估计存在不确定性。为了解决现有深度学习框架识别图像不够准确的问题,特斯拉找到的第一剂灵丹妙药是他们包含数百万视频的、而且经过精心标注的庞大数据集。
为了更高效的处理和标注数据,特斯拉开发了一套具有巧妙分工的半自动数据标记系统,其中神经网络执行重复性工作,该技术涉及神经网络、雷达数据和人工审查的组合,而人类负责高级认知问题和极端情况。特斯拉在全球销售了数百万辆配备摄像头的汽车,在收集训练汽车计算机视觉深度学习模型所需的数据方面处于统治性地位。特斯拉自动驾驶团队积累了1.5 PB的数据,其中包括一百万个10秒视频和60亿个带有边界框、深度和速度注释的对象。
下面这段视频展示了在远距离、灰尘、或者是雨雪天气中物体都能被一致的检测到的效果,就是图中的那个粉色方块。

特斯拉构建的基于RNN的深度学习模型是一套非常复杂的多层神经网络系统,它通过大概这么几个步骤来实现了利用安装在汽车周围的八个摄像头的自动驾驶。首先是需要能够处理摄像头采集到的图片,比如从中识别出汽车、行人、交通灯等。然后,来自多个摄像头的图像需要能够被拼接在一起,形成这样的向量空间Vector Space,就是现实世界的一个3D投影。这段录像就展示了在缝合到一起的影像中检测机动车道的效果,里面的蓝线就是不同摄像头采集到的图片的分界线。第三,有了这些处理好的数据之后,就要对它们进行特征处理,这里除了视频之外合理还要引入汽车的速度、加速度、所处的空间位置、时间等因素。最终,这些处理好的特征会被输入基于RNN的深度学习神经网络里,RNN会及时跟踪任何时间点发生的事情,并有能力选择性地读取和处理这些数据,当汽车在行驶时,它只会高效的更新汽车附近和汽车能见范围内的部分。这里对于算法的细节省略了一万句,有兴趣的小伙伴可以在公众号后台留言获取详细的引用资料。


图 5. 相机连接到 3D 向量空间(来自Tesla AI Day)
图 6. 缝合到 3D 空间中的车道检测(来自Tesla AI Day)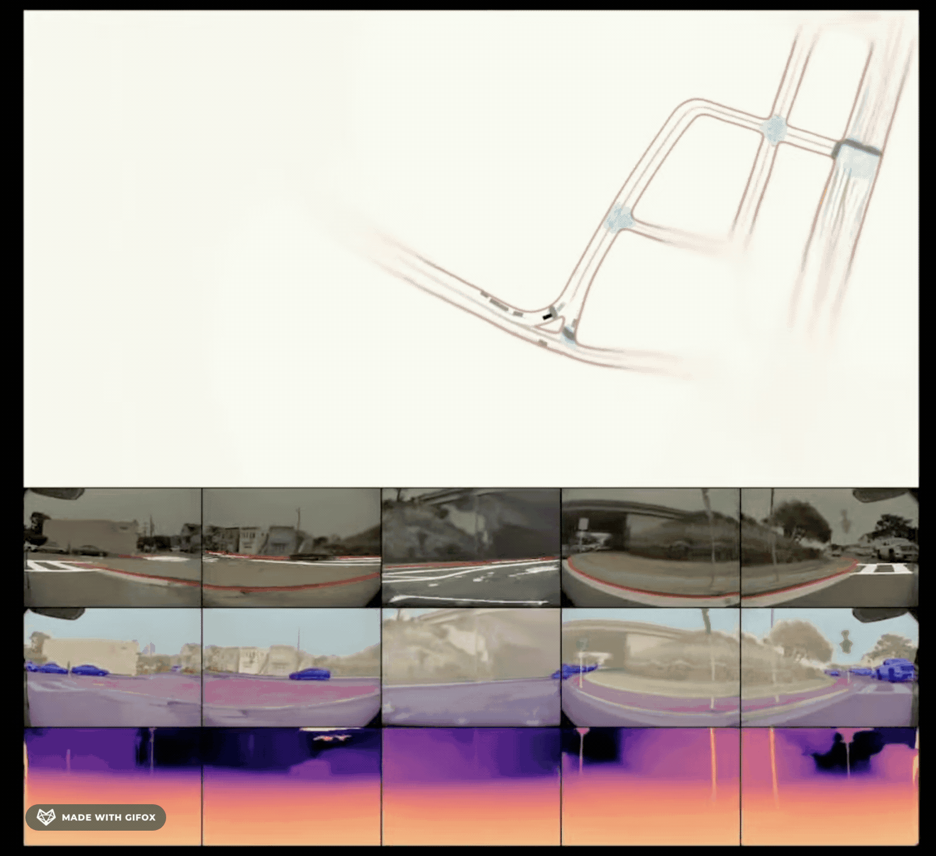
图 11. 空间 RNN(来自Tesla AI Day)
简单总结回顾一下就是,首先进行单个视频的采集和处理,然后缝合多个摄像头采集的图像,之后进行特征处理,最后通过RNN实现最终的处理。虽然特斯拉在这个领域取得了不小的突破,但当前业界得到的深度学习模型依然有它的局限,比如说它很难进行逻辑推理,也就是举一反三,处理训练数据集中完全没有出现过的新情况的能力不足。
这是一段由人工智能加工整理的内容,怕学AI太难,那我们就先和AI玩起来。聊完特斯拉,下期内容我们再来聊聊SpaceX。再见。

可交互的可视化机器学习开源教程 - https://github.com/ocademy-ai/machine-learning
这篇关于x.ai还是OpenAI?埃隆·马斯克的AI帝国【2】的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-24酒店香薰厂家:创造独特客户体验
- 2024-12-22程序员出海做 AI 工具:如何用 similarweb 找到最佳流量渠道?
- 2024-12-20自建AI入门:生成模型介绍——GAN和VAE浅析
- 2024-12-20游戏引擎的进化史——从手工编码到超真实画面和人工智能
- 2024-12-20利用大型语言模型构建文本中的知识图谱:从文本到结构化数据的转换指南
- 2024-12-20揭秘百年人工智能:从深度学习到可解释AI
- 2024-12-20复杂RAG(检索增强生成)的入门介绍
- 2024-12-20基于大型语言模型的积木堆叠任务研究
- 2024-12-20从原型到生产:提升大型语言模型准确性的实战经验
- 2024-12-20啥是大模型1



