【2023年】第43天 使用DCGAN生成人脸照片
2023/8/24 21:23:00

本文主要是介绍【2023年】第43天 使用DCGAN生成人脸照片,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
1. 数据集
- CelebA数据集是一种用于人脸属性分析的大型数据集。该数据集包含超过20万个名人身份的人脸图像,每个人脸图像都带有40个不同的属性标签,包括年龄、性别、微笑等。
- CelebA数据集是由香港中文大学的计算机科学与工程学院(CUHK)创建的。它是一个广泛使用的数据集,被广泛用于人脸识别、人脸属性分析、人脸合成等相关研究领域。该数据集中的人脸图像来自互联网上的名人照片,包括电影明星、音乐家、运动员等。
- CelebA数据集中的人脸图像具有较大的变化,如姿势、表情、光照和背景等。这使得该数据集对于研究人脸属性分析的鲁棒性和准确性非常有价值。
- CelebA数据集还具有可扩展性,它提供了大量的图像样本和属性标签,可以用于深度学习等大规模训练和评估任务。
2. 重温DCGAN的结构
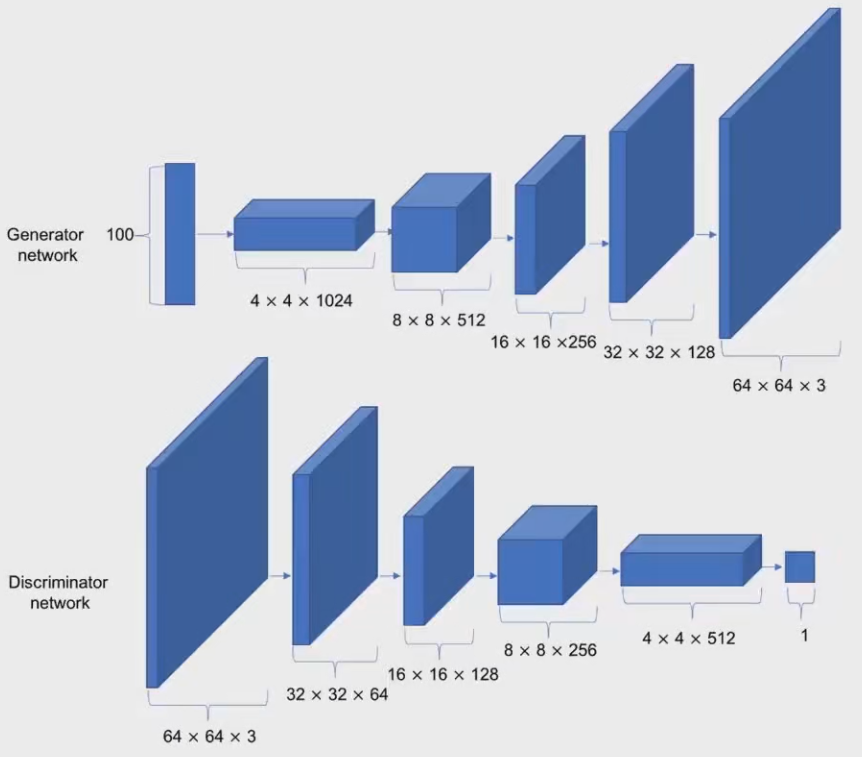
- 关于DCGAN的生成器和判别器,二者可以看作是一个相反的过程。
3. 程序实现
- 关于每部分代码的解释都已注释的形式呈现。
# HyperParameters
class Hyperparameters:
# Data
device = 'cpu' # cpu,也就是推理的设备
data_root = 'D:/data'
image_size = 64 # 指的是我们整个网络运行的人脸图片的大小,我们会得到64*64这样的大小
seed = 1234 # 随机种子设置为1234
# Model
z_dim = 100 # laten z dimension,也就是生成器的输入是一个100维的高斯分布
data_channels = 3 # RGB face
# Exp
batch_size = 64
n_workers = 2 # data loader works,加载数据的时候启用多少个cpu
beta = 0.5 # adam optimizer 0.5,优化器,一般会设置为0.9
init_lr = 0.0002
epochs = 1000
verbose_step = 250 # evaluation: store image during training
save_step = 1000 # save model step
HP = Hyperparameters()
# only face images, no target / label
from Gface.log.config import HP
from torchvision import transforms as T # torchaudio(speech) / torchtext(text)
import torchvision.datasets as TD
from torch.utils.data import DataLoader
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # openKMP cause unexpected error
# apply a label to corresponding
data_face = TD.ImageFolder(root=HP.data_root,
transform=T.Compose([
T.Resize(HP.image_size), # 64x64x3
T.CenterCrop(HP.image_size),
T.ToTensor(), # to [0, 1]
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # can't apply ImageNet statistic
]),
)
face_loader = DataLoader(data_face,
batch_size=HP.batch_size,
shuffle=True,
num_workers=HP.n_workers) # 2 workers
# normalize: x_norm = (x - x_avg) / std de-normalize: x_denorm = (x_norm * std) + x_avg
invTrans = T.Compose([
T.Normalize(mean=[0., 0., 0.], std=[1/0.5, 1/0.5, 1/0.5]),
T.Normalize(mean=[-0.5, -0.5, -0.5], std=[1., 1., 1.]),
])
if __name__ == '__main__':
import matplotlib.pyplot as plt
import torchvision.utils as vutils
for data, _ in face_loader:
print(data.size()) # NCHW
# format into 8x8 image grid
grid = vutils.make_grid(data, nrow=8) #
plt.imshow(invTrans(grid).permute(1, 2, 0)) # NHWC
plt.show()
break
import torch
from torch import nn
from Gface.log.config import HP
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.projection_layer = nn.Linear(HP.z_dim, 4*4*1024) # 1. feature/data transform 2. shape transform
self.generator = nn.Sequential(
# TransposeConv layer: 1
nn.ConvTranspose2d(in_channels=1024, # [N, 512, 8, 8]
out_channels=512,
kernel_size=(4, 4),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(512),
nn.ReLU(),
# TransposeConv layer: 2
nn.ConvTranspose2d(in_channels=512, # [N, 256, 16, 16]
out_channels=256,
kernel_size=(4, 4),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
# TransposeConv layer: 3
nn.ConvTranspose2d(in_channels=256, # [N, 128, 32, 32]
out_channels=128,
kernel_size=(4, 4),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(128),
nn.ReLU(),
# TransposeConv layer: final
nn.ConvTranspose2d(in_channels=128, # [N, 3, 64, 64]
out_channels=HP.data_channels, # output channel: 3 (RGB)
kernel_size=(4, 4),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.Tanh() # [0, 1] Relu [0, inf]
)
def forward(self, latent_z): # latent space (Ramdon Input / Noise) : [N, 100]
z = self.projection_layer(latent_z) # [N, 4*4*1024]
z_projected = z.view(-1, 1024, 4, 4) # [N, 1024, 4, 4]: NCHW
return self.generator(z_projected)
@staticmethod
def weights_init(layer):
layer_class_name = layer.__class__.__name__
if 'Conv' in layer_class_name:
nn.init.normal_(layer.weight.data, 0.0, 0.02)
elif 'BatchNorm' in layer_class_name:
nn.init.normal_(layer.weight.data, 1.0, 0.02)
nn.init.normal_(layer.bias.data, 0.)
if __name__ == '__main__':
z = torch.randn(size=(64, 100))
G = Generator()
g_out = G(z) # generator output
print(g_out.size())
import matplotlib.pyplot as plt
import torchvision.utils as vutils
from Gface.log.dataset_face import invTrans
# format into 8x8 image grid
grid = vutils.make_grid(g_out, nrow=8) #
plt.imshow(invTrans(grid).permute(1, 2, 0)) # NHWC
plt.show()
# Discriminator : Binary classification model
import torch
from torch import nn
from Gface.log.config import HP
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.discriminator = nn.Sequential( # 1. shape transform 2. use conv layer as "feature extraction"
# conv layer : 1
nn.Conv2d(in_channels=HP.data_channels, # [N, 16, 32, 32]
out_channels=16,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.LeakyReLU(0.2),
# conv layer : 2
nn.Conv2d(in_channels=16, # [N, 32, 16, 16]
out_channels=32,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2),
# conv layer : 3
nn.Conv2d(in_channels=32, # [N, 64, 8, 8]
out_channels=64,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
# conv layer : 4
nn.Conv2d(in_channels=64, # [N, 128, 4, 4]
out_channels=128,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
# conv layer : 5
nn.Conv2d(in_channels=128, # [N, 256, 2, 2]
out_channels=256,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
)
self.linear = nn.Linear(256*2*2, 1)
self.out_ac = nn.Sigmoid()
def forward(self, image):
out_d = self.discriminator(image) # image [N, 3, 64, 64] -> [N, 256, 2, 2]
out_d = out_d.view(-1, 256*2*2) # tensor flatten
return self.out_ac(self.linear(out_d))
@staticmethod
def weights_init(layer):
layer_class_name = layer.__class__.__name__
if 'Conv' in layer_class_name:
nn.init.normal_(layer.weight.data, 0.0, 0.02)
elif 'BatchNorm' in layer_class_name:
nn.init.normal_(layer.weight.data, 1.0, 0.02)
nn.init.normal_(layer.bias.data, 0.)
if __name__ == '__main__':
g_z = torch.randn(size=(64, 3, 64, 64))
D = Discriminator()
d_out = D(g_z)
print(d_out.size())
# 1. trainer for DCGAN
# 2. GAN relative training skills & tips
import os
from argparse import ArgumentParser
import torch.optim as optim
import torch
import random
import numpy as np
import torch.nn as nn
from tensorboardX import SummaryWriter
from Gface.log.generator import Generator
from Gface.log.discriminator import Discriminator
import torchvision.utils as vutils
from Gface.log.config import HP
from Gface.log.dataset_face import face_loader, invTrans
logger = SummaryWriter('./log')
# seed init: Ensure Reproducible Result
torch.random.manual_seed(HP.seed)
torch.cuda.manual_seed(HP.seed)
random.seed(HP.seed)
np.random.seed(HP.seed)
def save_checkpoint(model_, epoch_, optm, checkpoint_path):
save_dict = {
'epoch': epoch_,
'model_state_dict': model_.state_dict(),
'optimizer_state_dict': optm.state_dict()
}
torch.save(save_dict, checkpoint_path)
def train():
parser = ArgumentParser(description='Model Training')
parser.add_argument(
'--c', # G and D checkpoint path: model_g_xxx.pth~model_d_xxx.pth
default=None,
type=str,
help='training from scratch or resume training'
)
args = parser.parse_args()
# model init
G = Generator() # new a generator model instance
G.apply(G.weights_init) # apply weight init for G
D = Discriminator() # new a discriminator model instance
D.apply(D.weights_init) # apply weight init for G
G.to(HP.device)
D.to(HP.device)
# loss criterion
criterion = nn.BCELoss() # binary classification loss
# optimizer
optimizer_g = optim.Adam(G.parameters(), lr=HP.init_lr, betas=(HP.beta, 0.999))
optimizer_d = optim.Adam(D.parameters(), lr=HP.init_lr, betas=(HP.beta, 0.999))
start_epoch, step = 0, 0 # start position
if args.c: # model_g_xxx.pth~model_d_xxx.pth
model_g_path = args.c.split('~')[0]
checkpoint_g = torch.load(model_g_path)
G.load_state_dict(checkpoint_g['model_state_dict'])
optimizer_g.load_state_dict(checkpoint_g['optimizer_state_dict'])
start_epoch_gc = checkpoint_g['epoch']
model_d_path = args.c.split('~')[1]
checkpoint_d = torch.load(model_d_path)
D.load_state_dict(checkpoint_d['model_state_dict'])
optimizer_d.load_state_dict(checkpoint_d['optimizer_state_dict'])
start_epoch_dc = checkpoint_d['epoch']
start_epoch = start_epoch_gc if start_epoch_dc > start_epoch_gc else start_epoch_dc
print('Resume Training From Epoch: %d' % start_epoch)
else:
print('Training From Scratch!')
G.train() # set training flag
D.train() # set training flag
# fixed latent z for G logger
fixed_latent_z = torch.randn(size=(64, 100), device=HP.device)
# main loop
for epoch in range(start_epoch, HP.epochs):
print('Start Epoch: %d, Steps: %d' % (epoch, len(face_loader)))
for batch, _ in face_loader: # batch shape [N, 3, 64, 64]
# ################# D Update #########################
# log(D(x)) + log(1-D(G(z)))
# ################# D Update #########################
b_size = batch.size(0) # 64
optimizer_d.zero_grad() # gradient clean
# gt: ground truth: real data
# label smoothing: 0.85, 0.1 / softmax: logist output -> [0, 1] Temperature Softmax
# multi label: 1.jpg : cat and dog
labels_gt = torch.full(size=(b_size, ), fill_value=0.9, dtype=torch.float, device=HP.device)
predict_labels_gt = D(batch.to(HP.device)).squeeze() # [64, 1] -> [64,]
loss_d_of_gt = criterion(predict_labels_gt, labels_gt)
labels_fake = torch.full(size=(b_size, ), fill_value=0.1, dtype=torch.float, device=HP.device)
latent_z = torch.randn(size=(b_size, HP.z_dim), device=HP.device)
predict_labels_fake = D(G(latent_z)).squeeze() # [64, 1] - > [64,]
loss_d_of_fake = criterion(predict_labels_fake, labels_fake)
loss_D = loss_d_of_gt + loss_d_of_fake # add the two parts
loss_D.backward()
optimizer_d.step()
logger.add_scalar('Loss/Discriminator', loss_D.mean().item(), step)
# ################# G Update #########################
# log(1-D(G(z)))
# ################# G Update #########################
optimizer_g.zero_grad() # G gradient clean
latent_z = torch.randn(size=(b_size, HP.z_dim), device=HP.device)
labels_for_g = torch.full(size=(b_size, ), fill_value=0.9, dtype=torch.float, device=HP.device)
predict_labels_from_g = D(G(latent_z)).squeeze() # [N, ]
loss_G = criterion(predict_labels_from_g, labels_for_g)
loss_G.backward()
optimizer_g.step()
logger.add_scalar('Loss/Generator', loss_G.mean().item(), step)
if not step % HP.verbose_step:
with torch.no_grad():
fake_image_dev = G(fixed_latent_z)
logger.add_image('Generator Faces', invTrans(vutils.make_grid(fake_image_dev.detach().cpu(), nrow=8)), step)
if not step % HP.save_step: # save G and D
model_path = 'model_g_%d_%d.pth' % (epoch, step)
save_checkpoint(G, epoch, optimizer_g, os.path.join('model_save', model_path))
model_path = 'model_d_%d_%d.pth' % (epoch, step)
save_checkpoint(D, epoch, optimizer_d, os.path.join('model_save', model_path))
step += 1
logger.flush()
print('Epoch: [%d/%d], step: %d G loss: %.3f, D loss %.3f' %
(epoch, HP.epochs, step, loss_G.mean().item(), loss_D.mean().item()))
logger.close()
if __name__ == '__main__':
train()
# 1. how to use G?
import torch
from Gface.log.dataset_face import invTrans
from Gface.log.generator import Generator
from Gface.log.config import HP
import matplotlib.pyplot as plt
import torchvision.utils as vutils
# new an generator model instance
G = Generator()
checkpoint = torch.load('./model_save/model_g_71_225000.pth', map_location='cpu')
G.load_state_dict(checkpoint['model_state_dict'])
G.to(HP.device)
G.eval() # set evaluation mode
while 1:
# 1. Disentangled representation: manual set Z: [0.3, 0, ]
# 2. any input: z: fuzzy image -> high resolution image / mel -> audio/speech(vocoder)
latent_z = torch.randn(size=(HP.batch_size, HP.z_dim), device=HP.device)
fake_faces = G(latent_z)
grid = vutils.make_grid(fake_faces, nrow=8) # format into a "big" image
plt.imshow(invTrans(grid).permute(1, 2, 0)) # HWC
plt.show()
input()
- 到此,我们就训练了生成器和判别器,并完成了生成人脸照片的任务。
这篇关于【2023年】第43天 使用DCGAN生成人脸照片的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2025-01-05Easysearch 可搜索快照功能,看这篇就够了
- 2025-01-04BOT+EPC模式在基础设施项目中的应用与优势
- 2025-01-03用LangChain构建会检索和搜索的智能聊天机器人指南
- 2025-01-03图像文字理解,OCR、大模型还是多模态模型?PalliGema2在QLoRA技术上的微调与应用
- 2025-01-03混合搜索:用LanceDB实现语义和关键词结合的搜索技术(应用于实际项目)
- 2025-01-03停止思考数据管道,开始构建数据平台:介绍Analytics Engineering Framework
- 2025-01-03如果 Azure-Samples/aks-store-demo 使用了 Score 会怎样?
- 2025-01-03Apache Flink概述:实时数据处理的利器
- 2025-01-01使用 SVN合并操作时,怎么解决冲突的情况?-icode9专业技术文章分享
- 2025-01-01告别Anaconda?试试这些替代品吧



