深入探索智能问答:从检索到生成的技术之旅
2023/11/10 21:03:05

本文主要是介绍深入探索智能问答:从检索到生成的技术之旅,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
一、智能问答概述
智能问答 (Intelligent Question Answering, IQA) 是自然语言处理(NLP)中的一个核心子领域,旨在设计和开发可以解析、理解并回答用户提出的自然语言问题的系统。这些系统的目标不仅仅是返回与问题相关的文本,而是提供精确、凝练且直接的答案。

1. 语义理解
智能问答系统的核心组件之一是语义理解,即系统需要深入地理解用户提问的意图和背后的意义。
例子:当用户问:“金星是太阳系的第几颗行星?”而不是简单地返回与“金星”和“太阳系”相关的一段文本,系统应理解用户的真正意图并回答:“金星是太阳系的第二颗行星。”
2. 知识库和数据库
为了回答问题,智能问答系统通常需要访问大型的知识库或数据库,这些知识库包含了大量的事实、数据和信息。
例子:当用户询问:“苹果公司的创始人是谁?”系统会查询其知识库,并返回:“苹果公司的创始人是史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗纳德·韦恩。”
3. 上下文感知
高级的智能问答系统可以感知上下文,这意味着它们可以根据前面的对话或提问为用户提供更相关的答案。
例子:如果用户首先问:“巴黎位于哪个国家?”得到答案后,又问:“那里的官方语言是什么?”系统应该能够识别出“那里”指的是“巴黎”,并回答:“官方语言是法语。”
4. 动态学习和自适应
随着时间的推移,优秀的智能问答系统能够从用户的互动中学习,并改进其回答策略和准确性。
例子:如果一个系统频繁地收到关于某一新闻事件的问题,并且用户对其回答表示满意,系统应该能够识别这一事件的重要性,并在未来的查询中更加重视与之相关的信息。
二、发展历程

智能问答的历史是自然语言处理和计算机科学发展史的一个缩影。从最初的基于规则的系统到现在的深度学习模型,它不断地推动技术界前进,试图更好地理解和回应人类语言。
1. 基于规则的系统
在20世纪60、70年代,早期的问答系统主要依赖于硬编码的规则和固定的模式匹配。这些系统是基于人类定义的明确规则来识别问题并提供答案。
例子:一个基于规则的系统可能有一个简单的查找表,当用户询问“日本的首都是什么?”时,它会匹配“首都”和“日本”的关键词,然后返回存储的答案“东京”。
2. 统计方法的兴起
随着大数据和计算能力的增长,90年代和21世纪初,研究人员开始使用统计方法来改进问答系统。这些方法通常基于从大量文本中提取的概率来预测答案。
例子:当用户询问“谁写了《哈利·波特》?”系统会搜索大量的文档,统计与“哈利·波特”和“作者”相关的句子,最后确定“J.K.罗琳”是最可能的答案。
3. 深度学习和神经网络的突破
近十年来,随着深度学习技术的突破,问答系统得到了质的飞跃。神经网络,尤其是循环神经网络(RNN)和Transformer架构,使得模型可以处理复杂的语义结构和长距离依赖。
例子:BERT模型可以处理复杂的问题,如:“《安徒生童话》中描述的‘皇帝的新装’的寓意是什么?”BERT可以深入分析文本内容,识别出该故事是关于虚荣和盲目从众的。
4. 预训练模型
近年来,预训练模型如GPT-4、GPT-3.5、T5和XLNet等,已经在各种NLP任务上取得了前所未有的成果。这些模型首先在大量文本上进行预训练,然后可以通过迁移学习快速地适应特定的任务,如智能问答。
例子:使用GPT-4,当用户提出抽象问题,如:“人生的意义是什么?”GPT-3可以返回哲学、文学和各种文化背景下的多个观点,提供深入而全面的回答。
三、智能问答系统的主要类型

智能问答系统因应用场景、数据源和技术手段的不同而存在多种类型。以下是其中的一些主要类型及其特点:
-
基于知识库的问答系统:
-
依赖预定义的知识库来检索答案。
-
需要大量的知识工程师来维护和更新知识库。
-
在特定领域(如医学、法律)中表现较好,因为它们可以提供准确的、基于事实的答案。
例子:医学问答系统可能有一个知识库,其中包含各种疾病、症状和治疗方法的信息。
-
-
基于检索的问答系统:
-
从大量文本数据中检索与问题相关的片段。
-
依赖高效的信息检索技术。
-
能够处理开放领域的问题,但答案的准确性可能受限于数据源的质量。
例子:当用户询问某个历史事件的详细情况时,系统会从互联网上检索相关文章或百科全书来提供答案。
-
-
基于对话的问答系统:
-
与用户进行多轮对话,以便更好地理解其问题。
-
可以处理复杂和上下文依赖的问题。
-
通常依赖深度学习和上下文感知的模型。
例子:当用户问:“你知道巴黎吗?”系统回答:“当然,你想知道巴黎的哪方面信息?”用户继续:“它的历史建筑。”系统再进行具体的答复。
-
-
基于生成的问答系统:
-
不是从固定的数据源检索答案,而是实时生成答案。
-
通常使用神经网络,如序列到序列模型。
-
可以提供个性化和创造性的答案,但可能缺乏事实上的准确性。
例子:当用户询问:“如果莎士比亚是现代人,他会怎么评价智能手机?”系统可能生成一个富有创意的答案,尽管这不是基于真实事实的答案。
-
四、基于知识库的问答系统
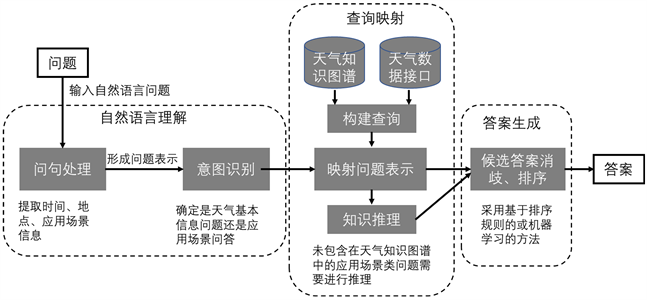
基于知识库的问答系统是一种专为解答基于事实和数据的问题而设计的系统。它们依赖于预定义的知识库,这些知识库通常包含大量的事实、关系和其他结构化信息。
定义:基于知识库的问答系统主要依赖于一个结构化的知识库,将用户的问题映射到知识库中的相关实体和关系,从而找到或生成答案。
例子:考虑一个知识库,其中包含关于国家、首都和地理位置的信息。对于问题“巴西的首都是什么?”,系统查询知识库并返回“巴西利亚”。
一个简单的基于知识库的问答系统实现如下:
# 定义简单的知识库
knowledge_base = {
'巴西': {'首都': '巴西利亚', '语言': '葡萄牙语'},
'法国': {'首都': '巴黎', '语言': '法语'},
# 更多的条目...
}
def knowledge_base_qa_system(question):
# 简单的字符串解析来提取实体和属性(真实系统会使用更复杂的NLP技术)
for country, attributes in knowledge_base.items():
if country in question:
for attribute, answer in attributes.items():
if attribute in question:
return answer
return "我不知道答案。"
# 测试问答系统
question = "巴西的首都是什么?"
print(knowledge_base_qa_system(question)) # 输出:巴西利亚
在这个简单示例中,我们定义了一个知识库,其中包含一些国家及其属性(如首都和官方语言)。问答系统通过简单地解析问题字符串来查询知识库并找到答案。实际上,真实的基于知识库的问答系统会使用更复杂的自然语言处理和知识图谱查询技术来解析问题和查找答案。
五、基于检索的问答系统
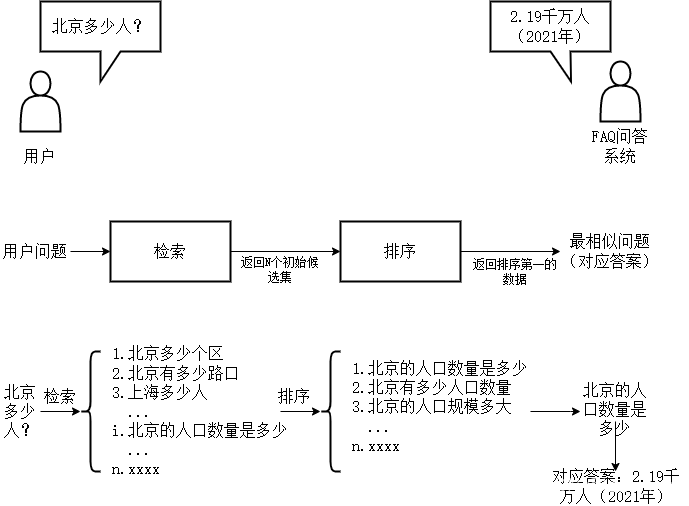
基于检索的问答系统是指根据用户问题的语义信息,从一个预先存在的大型文档或FAQ集中检索并返回最相关的答案。与基于知识库的问答系统不同,基于检索的系统不依赖于结构化数据,而是依赖于大量的文本数据。
定义:基于检索的问答系统使用语义搜索技术,对用户的问题和数据集中的问题进行比较,从而找到最匹配的答案。
例子:在一个包含医学文献的数据集中,对于问题“怎样预防流感?”,系统可能会返回一个相关医学研究中的段落,如“接种流感疫苗是预防流感的最有效方法。”
下面是一个简单的基于检索的问答系统的实现:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 定义一个简单的文档集合
documents = [
"接种流感疫苗是预防流感的最有效方法。",
"猫是可爱的宠物。",
"巴黎是法国的首都。",
# 更多文档...
]
vectorizer = TfidfVectorizer()
document_vectors = vectorizer.fit_transform(documents)
def retrieval_based_qa_system(question):
question_vector = vectorizer.transform([question])
similarities = cosine_similarity(question_vector, document_vectors)
best_match = documents[similarities.argmax()]
return best_match
# 测试问答系统
question = "如何避免得流感?"
print(retrieval_based_qa_system(question)) # 输出:接种流感疫苗是预防流感的最有效方法。
在这个简化的示例中,我们首先使用TF-IDF方法将文档转换为向量。当接收到一个问题时,我们同样将其转换为向量并使用余弦相似度来确定哪个文档与问题最为相似。然后返回最匹配的文档作为答案。
实际应用中,基于检索的问答系统可能会采用更复杂的深度学习模型、BERT等预训练模型来提高检索的准确性。
六、基于对话的问答系统
基于对话的问答系统不仅仅回答单一的问题,而是能与用户进行持续的交互,理解并维护对话上下文,从而为用户提供更加准确和个性化的答案。
定义:基于对话的问答系统是一种可以处理多轮对话、维护和利用对话上下文的系统,从而在与用户交互时提供更有深度和持续性的回答。
例子:用户可能会问:“推荐一部好看的电影。”系统回答:“你喜欢哪种类型的电影?”用户回答:“我喜欢科幻。”系统随后推荐:“那你可能会喜欢《星际穿越》。”
以下是一个简单的基于对话的问答系统的实现:
import random
# 对话上下文和推荐数据
context = {
'genre': None
}
recommendations = {
'科幻': ['星际穿越', '银河系漫游指南', '阿凡达'],
'爱情': ['泰坦尼克号', '爱情公寓', '罗马假日'],
# 更多类别...
}
def dialog_based_qa_system(question):
if "推荐" in question and "电影" in question:
return "你喜欢哪种类型的电影?", context
if context.get('genre') is None:
for genre, movies in recommendations.items():
if genre in question:
context['genre'] = genre
return f"那你可能会喜欢{random.choice(movies)}。", context
return "对不起,我不确定如何回答。", context
# 测试问答系统
question1 = "推荐一部好看的电影。"
response1, updated_context = dialog_based_qa_system(question1)
print(response1) # 输出:你喜欢哪种类型的电影?
question2 = "我喜欢科幻。"
response2, updated_context = dialog_based_qa_system(question2)
print(response2) # 输出:那你可能会喜欢星际穿越。
这是一个非常简化的例子。在这里,我们使用一个简单的上下文字典来跟踪对话中的状态。实际应用中,基于对话的问答系统可能会使用RNN、Transformer或其他深度学习架构来维护和利用对话上下文。此外,更高级的系统还可能包括情感分析、个性化推荐等特性。
七、基于生成的问答系统
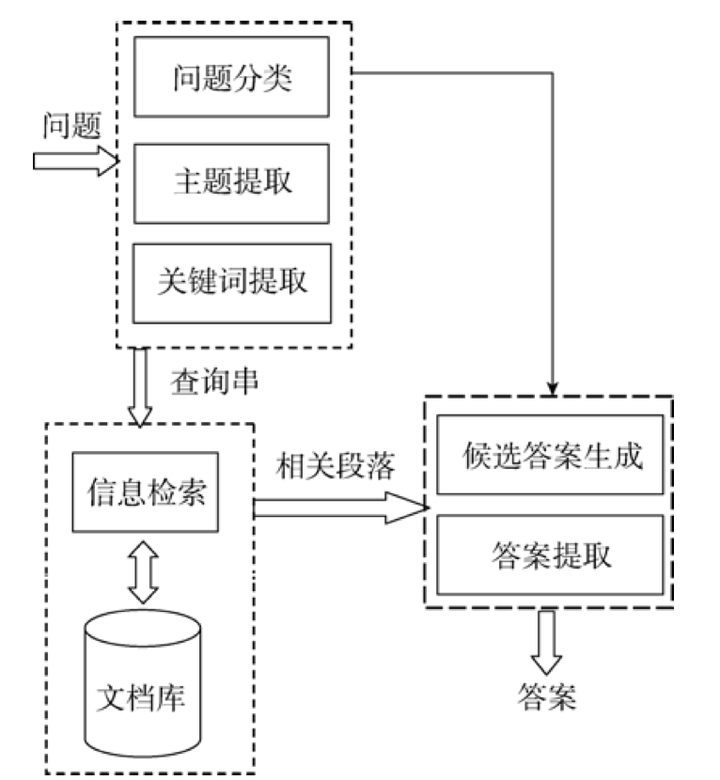
与基于检索或对话的问答系统不同,基于生成的问答系统的目标是生成全新的答案文本,而不是从预先定义的答案集或文档中选择答案。这些系统通常使用深度学习模型,特别是序列到序列(seq2seq)模型。
定义:基于生成的问答系统使用深度学习技术(如RNN、LSTM或Transformer)从头开始生成答案,而不是从现有文档或数据库中检索答案。
例子:当问到“太阳是什么?”时,系统可能会生成答案“太阳是一个主序星,位于我们的太阳系中心,它通过核聚变产生能量。”
下面是一个简化的基于PyTorch的生成问答系统的示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 假设我们有一个预训练的seq2seq模型
class Seq2SeqModel(nn.Module):
def __init__(self):
super(Seq2SeqModel, self).__init__()
# ... 模型定义(如编码器、解码器等)
def forward(self, input):
# ... 前向传播
pass
model = Seq2SeqModel()
model.load_state_dict(torch.load("pretrained_seq2seq_model.pth"))
model.eval()
def generate_based_qa_system(question):
question_tensor = torch.tensor(question) # 将问题转化为张量
with torch.no_grad():
generated_answer = model(question_tensor)
return generated_answer
# 测试问答系统
question = "太阳是什么?"
print(generate_based_qa_system(question))
这只是一个高级的框架,实际的生成问答系统会涉及许多其他复杂性,包括词嵌入、注意机制、解码策略等。实际的seq2seq模型实现也要复杂得多。使用如BERT、GPT-2或T5等预训练模型可以进一步提高生成问答系统的性能。
八、总结
经过深入的探索和技术解析,我们对自然语言处理中的智能问答系统有了更加深入的了解。从简单的基于检索的问答系统,到能与用户进行复杂多轮对话的对话系统,再到具备生成全新答案能力的生成式问答系统,我们目睹了问答技术的迅猛发展和应用广泛性。
然而,背后的技术进步并不仅仅是算法的改进或计算能力的增强。关键在于,随着大量数据的积累和开放,我们的机器学习模型得以在更加真实和多样的数据上进行训练。这也反映了一个核心原则:真实世界的多样性和复杂性是无法通过简单规则来完全捕获的。只有当我们的模型能够在真实的、多样的数据上进行学习,它们才能更好地为我们服务。
但我们也需要意识到,无论技术如何进步,真正的挑战并非仅仅在于如何构建一个更高效或更准确的问答系统。更为根本的挑战在于,如何确保我们的技术在为人类提供帮助的同时,也能够尊重用户的隐私、确保信息的真实性并避免偏见。在AI的发展中,技术和伦理应该并行发展。
这篇关于深入探索智能问答:从检索到生成的技术之旅的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-24酒店香薰厂家:创造独特客户体验
- 2024-12-22程序员出海做 AI 工具:如何用 similarweb 找到最佳流量渠道?
- 2024-12-20自建AI入门:生成模型介绍——GAN和VAE浅析
- 2024-12-20游戏引擎的进化史——从手工编码到超真实画面和人工智能
- 2024-12-20利用大型语言模型构建文本中的知识图谱:从文本到结构化数据的转换指南
- 2024-12-20揭秘百年人工智能:从深度学习到可解释AI
- 2024-12-20复杂RAG(检索增强生成)的入门介绍
- 2024-12-20基于大型语言模型的积木堆叠任务研究
- 2024-12-20从原型到生产:提升大型语言模型准确性的实战经验
- 2024-12-20啥是大模型1



