解码知识图谱:从核心概念到技术实战
2023/11/12 21:03:04

本文主要是介绍解码知识图谱:从核心概念到技术实战,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
1. 概述
知识图谱作为一种特殊的信息表示技术,其在近年来在各种应用领域中都有所体现,尤其在自然语言处理(NLP)中,它的重要性更是日益凸显。知识图谱能够高效、有组织地存储和管理大量的信息,而且能够用图的形式表示出这些信息之间的关系,使得信息更具有语境,更易于理解和应用。
什么是知识图谱
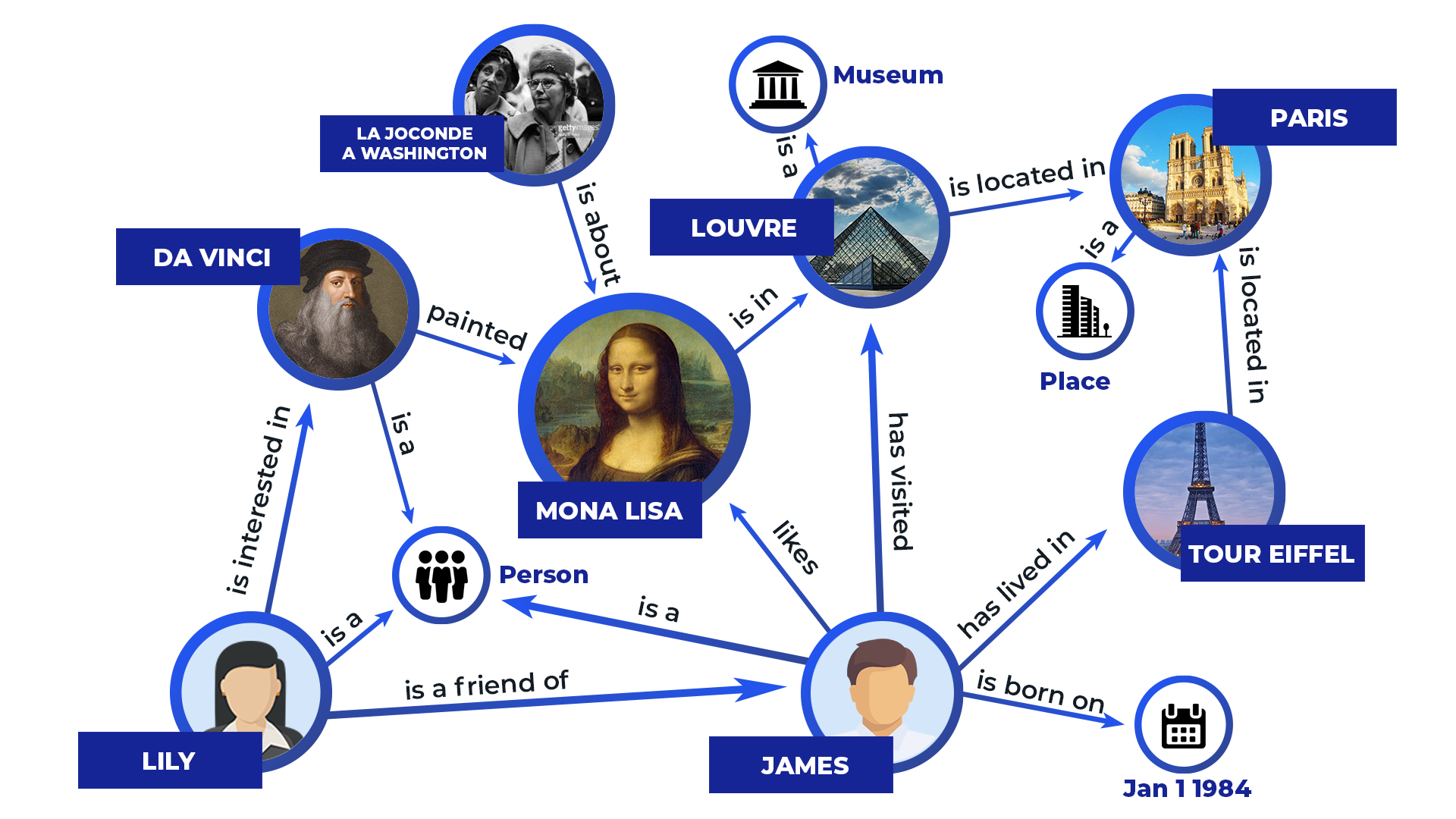
定义:知识图谱是一个结构化的信息库,其中的信息以图的形式组织,每个节点表示一个实体,每条边表示两个实体之间的关系。
例子:考虑一种场景,我们有一个音乐知识图谱。其中的节点可能包括“披头士乐队”、“摇滚音乐”和“1960s”,而边则可能表示“披头士乐队”是“摇滚音乐”的代表,以及“披头士乐队”在“1960s”非常受欢迎。
知识图谱与自然语言处理的关系
定义:在自然语言处理中,知识图谱被用作一种工具,帮助机器更好地理解和处理自然语言。通过知识图谱,机器可以理解文本中的实体及其关系,从而做出更加准确的决策或生成更为准确的回复。
例子:考虑一个问答系统。当用户询问“披头士乐队是哪一种音乐风格的代表?”时,系统可以通过查询知识图谱,得到“摇滚音乐”作为答案。这是因为知识图谱中已经存储了“披头士乐队”和“摇滚音乐”的关系。
总的来说,知识图谱为自然语言处理提供了一个结构化的信息源,能够大大提高其性能和准确性。而随着更多的研究和应用,我们可以期待知识图谱在自然语言处理中的作用将会越来越重要。
2. 发展历程
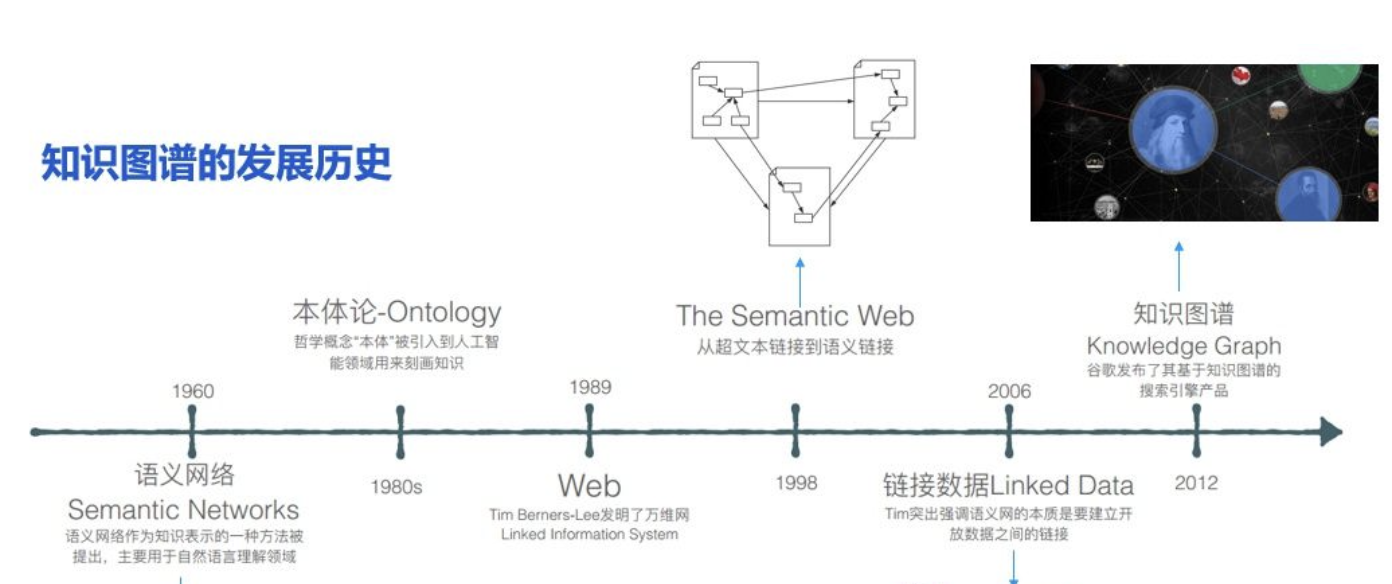
知识图谱这个概念并不是新鲜事物,但近些年由于技术进步和大数据的兴起,它得到了前所未有的关注和发展。从早期的语义网络和本体论到现在的大规模商业应用,知识图谱的发展脚步始终未停。
语义网络
定义:语义网络起源于20世纪60年代,是一种图形表示知识的方法,其中的节点代表概念,边表示概念之间的关系。
例子:考虑一个关于动物的简单语义网络。其中的节点包括“鸟”和“企鹅”,边表示“企鹅”是“鸟”的一种。但与此同时,可能还有另一条边表示“企鹅”不能飞。
本体论
定义:本体论在计算机科学中是一种对特定领域知识进行形式化描述的方法,它不仅描述了实体及其之间的关系,还包括了关于这些实体和关系的规则。
例子:在医学领域,本体论可以用来描述各种疾病、症状和治疗方法。例如,它可能会有一个规则表示:“如果一个人有症状A、B和C,则他很可能患有疾病X。”
大数据时代的知识图谱
定义:随着互联网的普及和大数据技术的进步,知识图谱开始被用于更为复杂的场景,如搜索引擎、智能助手和推荐系统。
例子:谷歌的“Knowledge Graph”是一个著名的应用,它帮助搜索引擎理解用户的查询,并提供相关的、结构化的信息。例如,当你搜索“阿尔伯特·爱因斯坦”时,你不仅会得到关于他的Wikipedia链接,还会看到他的生平、成就、相关人物等结构化信息。
知识图谱与深度学习的融合
定义:近年来,知识图谱和深度学习技术的结合已成为研究的热点,其中知识图谱为深度学习模型提供结构化的背景知识。
例子:在药物发现领域,知识图谱可以描述化合物、疾病和蛋白质等实体以及它们之间的关系。结合深度学习,研究者可以预测新的、未知的药物和疾病之间的关系,从而加速药物研发过程。
总的来说,知识图谱的发展历程反映了技术和应用的不断进步,从早期的理论研究到现在的商业应用,它始终处于知识表示和管理的前沿。
3. 研究内容
随着知识图谱领域的快速发展,其研究内容也变得日益丰富和多样。以下列出了一些核心的研究方向和相关的概念定义。
知识图谱的建模与表示
定义:知识图谱的建模与表示关注如何有效地组织、定义和表达知识中的实体和关系,以便于计算机处理和理解。
例子:Resource Description Framework (RDF) 是一种知识图谱的表示标准,它使用三元组(主体,谓词,宾体)来表达实体之间的关系,如:(巴黎, 是, 法国的首都)。
知识抽取
定义:知识抽取是从非结构化或半结构化数据源(如文本、图像或音频)中自动提取有价值的知识信息,并加入到知识图谱中。
例子:从新闻文章中自动识别并抽取出主要人物、事件和地点,然后将这些信息加入到现有的知识图谱中。
知识图谱的融合与对齐
定义:当面临多个来源或领域的知识图谱时,知识图谱的融合与对齐关注如何整合这些知识,确保其一致性和完整性。
例子:两个关于医学的知识图谱可能有部分重叠的内容,但在疾病的命名或分类上存在差异。通过对齐这两个图谱,可以生成一个更加完整和准确的医学知识库。
知识图谱的推理
定义:利用知识图谱中已有的知识进行逻辑推理,从而得到新的、隐含的知识信息。
例子:如果知识图谱中表示“A是B的父亲”和“B是C的父亲”,通过推理,我们可以得出“A是C的祖父”。
知识图谱的评估与验证
定义:为了确保知识图谱的质量和准确性,需要对其进行评估和验证,检查其内容是否准确、完整和一致。
例子:在加入新的知识到图谱中后,系统可能会自动比对已有的知识库,检测是否存在冲突或矛盾的信息。
总的来说,知识图谱研究的内容涵盖了从知识表示到知识应用的各个方面,其深度和广度都在不断扩展,为未来的技术进步和应用奠定了坚实的基础。
4. 知识图谱表示与存储
知识图谱的表示和存储是确保其高效使用的关键,因为这决定了如何查询、更新和扩展知识。下面我们深入探讨知识图谱的表示和存储技术。
RDF:一种知识图谱的表示方法
定义:Resource Description Framework (RDF) 是一种标准的知识图谱表示方法,采用三元组的形式来描述知识中的实体和关系。
例子:
一个RDF三元组可以表示为:
(巴黎, 是, 法国的首都)
Python代码:
# 一个简单的RDF三元组表示
triplet = ('巴黎', '是', '法国的首都')
print(triplet)
存储:使用图数据库
定义:图数据库是专为存储和查询图形结构的数据而设计的数据库。知识图谱由于其天然的图结构特性,与图数据库的存储和查询方式非常匹配。
例子:Neo4j 是一个流行的图数据库,可以用于存储和查询知识图谱。
Python代码:(这里我们使用py2neo库,这是Neo4j的一个Python客户端)
from py2neo import Graph, Node, Relationship
# 连接到Neo4j数据库
graph = Graph("http://localhost:7474", username="neo4j", password="password")
# 创建节点
paris = Node("City", name="巴黎")
france = Node("Country", name="法国")
# 创建关系
capital_relation = Relationship(paris, "是", france, description="法国的首都")
# 将节点和关系添加到图数据库中
graph.create(capital_relation)
嵌入:使用深度学习进行知识表示
定义:嵌入是将知识图谱中的实体和关系表示为低维向量,这种表示方法利用深度学习模型,如TransE,对知识进行编码。
例子:将"巴黎"和"是"这两个实体嵌入到一个维度为10的向量空间中。
PyTorch代码:
import torch
import torch.nn as nn
class EmbeddingModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(EmbeddingModel, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
def forward(self, input_ids):
return self.embeddings(input_ids)
# 假设我们的词汇表大小为1000,嵌入维度为10
model = EmbeddingModel(1000, 10)
# 获取"巴黎"和"是"的嵌入向量
# 这里我们仅为示例,随机指定"巴黎"和"是"的id为5和10
paris_embedding = model(torch.tensor([5]))
is_embedding = model(torch.tensor([10]))
print(paris_embedding)
print(is_embedding)
总结:知识图谱的表示与存储是其核心技术之一,确保了知识的高效查询和更新。从传统的RDF表示到现代的深度学习嵌入方法,这一领域始终在不断发展和创新。
5. 知识图谱获取与构建
知识图谱的获取与构建是知识图谱研究的核心部分,关注如何从各种数据源中自动或半自动提取、整合知识,并形成结构化的知识图谱。
知识抽取
定义:知识抽取是从非结构化或半结构化数据中自动识别和提取实体、关系和事件的过程。
例子:从一篇介绍史蒂夫·乔布斯的文章中抽取“史蒂夫·乔布斯是Apple的创始人”这一信息。
Python代码:(这里使用Spacy库进行简单的命名实体识别)
import spacy
# 加载模型
nlp = spacy.load("en_core_web_sm")
text = "Steve Jobs was the co-founder of Apple."
doc = nlp(text)
# 抽取实体
for ent in doc.ents:
print(ent.text, ent.label_)
知识融合
定义:知识融合是整合来自多个知识源的知识,消除冲突和冗余,形成统一、一致的知识图谱。
例子:从两个数据库中分别获取“史蒂夫·乔布斯,Apple创始人”和“乔布斯,苹果公司联合创始人”,并整合为“史蒂夫·乔布斯是Apple公司的联合创始人”。
Python代码:(简化的融合示例)
knowledge1 = {"name": "史蒂夫·乔布斯", "title": "Apple创始人"}
knowledge2 = {"name": "乔布斯", "title": "苹果公司联合创始人"}
def fuse_knowledge(k1, k2):
fused_knowledge = {}
fused_knowledge["name"] = k1["name"] # 选择更全的名称
# 合并title,简化为选择k2的title
fused_knowledge["title"] = k2["title"]
return fused_knowledge
result = fuse_knowledge(knowledge1, knowledge2)
print(result)
知识校验
定义:知识校验是检查知识图谱中的信息是否准确、一致和可靠,以确保其质量。
例子:验证“史蒂夫·乔布斯是Microsoft的创始人”是否正确。
Python代码:(假设我们有一个已验证的知识库来检查此信息)
validated_knowledge_base = {
"史蒂夫·乔布斯": "Apple的创始人",
"比尔·盖茨": "Microsoft的创始人"
}
def validate_knowledge(entity, claim):
if entity in validated_knowledge_base:
return validated_knowledge_base[entity] == claim
return False
is_valid = validate_knowledge("史蒂夫·乔布斯", "Microsoft的创始人")
print(is_valid) # 输出为False,因为此知识是错误的
知识图谱的获取与构建是一个复杂而持续的过程,涉及多个步骤和技术。上述代码仅为简化示例,真实的知识获取与构建会更为复杂,但基本思路是相似的。
6. 知识图谱推理
知识图谱推理是知识图谱的核心研究领域之一,涉及利用现有知识图谱中的实体和关系,推导和预测新的关系或属性。
逻辑推理
定义:逻辑推理使用形式化逻辑来推导知识图谱中的新关系或属性,通常基于预定义的规则或模式。
例子:给定以下知识:
- 所有人都是生物。
- Tom是一个人。
我们可以推断出:Tom是一个生物。
Python代码:
knowledge_base = {
"所有人": "生物",
"Tom": "人"
}
def logic_inference(entity):
if entity in knowledge_base:
if knowledge_base[entity] == "人":
return "生物"
return knowledge_base[entity]
return None
result = logic_inference("Tom")
print(result) # 输出:生物
知识嵌入推理
定义:知识嵌入推理使用深度学习模型,如TransE或TransH,将知识图谱中的实体和关系映射到低维向量空间,并通过向量运算进行推理。
例子:给定知识"北京" - “是” -> “中国的首都”,我们可以推断出其他类似的关系,如"东京" - “是” -> “日本的首都”。
PyTorch代码:
import torch
import torch.nn as nn
import torch.optim as optim
# 使用TransE模型的简化版本
class TransE(nn.Module):
def __init__(self, entity_size, relation_size, embedding_dim):
super(TransE, self).__init__()
self.entity_embeddings = nn.Embedding(entity_size, embedding_dim)
self.relation_embeddings = nn.Embedding(relation_size, embedding_dim)
def forward(self, head, relation):
head_embedding = self.entity_embeddings(head)
relation_embedding = self.relation_embeddings(relation)
return head_embedding + relation_embedding
# 假设我们有3个实体和1个关系
model = TransE(3, 1, 10)
# 训练模型... (这里略过训练过程)
# 推理
beijing_id, is_id, tokyo_id = 0, 0, 2
predicted_tail = model(beijing_id, is_id)
actual_tail = model.entity_embeddings(torch.tensor(tokyo_id))
# 计算相似性
similarity = torch.nn.functional.cosine_similarity(predicted_tail, actual_tail)
print(similarity)
路径推理
定义:路径推理是基于知识图谱中实体间的多跳关系来推导新的关系。
例子:如果知道"A是B的朋友"和"B是C的朋友",我们可以推断"A可能认识C"。
Python代码:
relations = {
"A": ["B"],
"B": ["C"]
}
def path_inference(entity):
friends = relations.get(entity, [])
friends_of_friends = []
for friend in friends:
friends_of_friends.extend(relations.get(friend, []))
return friends_of_friends
result = path_inference("A")
print(result) # 输出:['C']
知识图谱推理是一个富有挑战性的领域,因为它需要处理大量的知识,并从中推导出新的、有用的信息。上述方法和代码提供了一个入门级的概览,实际的应用和研究会更加复杂。
总结
知识图谱在过去的几年里已经从一个学术的概念逐渐转化为广泛应用于实际业务场景的强大工具。从最基本的概念、发展历程、研究内容,到更加复杂的知识图谱的表示、存储、获取、构建和推理,我们逐步深入了解了这一领域的技术内涵。
但是,纵观整个知识图谱的发展历程,其中最为突出的一个特点是:知识图谱是一个持续演进的领域。随着数据的增长、技术的进步以及应用场景的扩展,知识图谱所需处理的问题也在持续变化和扩展。
另外,我认为有两个核心洞见值得进一步思考:
-
知识图谱与人类思维:知识图谱不仅仅是一种存储和管理知识的工具,更重要的是,它在某种程度上模拟了人类的思维模式。我们如何组织、链接和使用知识,都在知识图谱中得到了很好的体现。因此,对知识图谱的研究实际上也加深了我们对人类认知的理解。
-
技术与应用的平衡:知识图谱的发展不应仅仅停留在技术层面。更为关键的是,如何将这些技术应用于实际问题,实现知识的最大化利用。这需要我们不断地进行技术和应用之间的平衡,确保知识图谱的技术进步能够真正地服务于实际的业务需求。
这篇关于解码知识图谱:从核心概念到技术实战的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-24酒店香薰厂家:创造独特客户体验
- 2024-12-22程序员出海做 AI 工具:如何用 similarweb 找到最佳流量渠道?
- 2024-12-20自建AI入门:生成模型介绍——GAN和VAE浅析
- 2024-12-20游戏引擎的进化史——从手工编码到超真实画面和人工智能
- 2024-12-20利用大型语言模型构建文本中的知识图谱:从文本到结构化数据的转换指南
- 2024-12-20揭秘百年人工智能:从深度学习到可解释AI
- 2024-12-20复杂RAG(检索增强生成)的入门介绍
- 2024-12-20基于大型语言模型的积木堆叠任务研究
- 2024-12-20从原型到生产:提升大型语言模型准确性的实战经验
- 2024-12-20啥是大模型1



