AI+OpenGL实现大眼特效
2023/11/20 23:03:10

本文主要是介绍AI+OpenGL实现大眼特效,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
随着科技的发展,AI(人工智能)技术已经越来越成熟,尤其是ChatGPT的出现,更是将AI技术推向了一个新的高度。
实际上,早在很多年前AI技术就已经广泛的应用于我们的日常生活中了,比如人脸识别、车牌自动识别等等,而在各种美颜App、视频App中更是大量使用了AI技术。
AI技术的分支有很多,如基于传统机器学习的AI技术,基于深度学习的AI技术等,但现在大家无一例外的都选择了基于深度学习的AI技术,因为这种基于大数据自主学习的AI技术给人们带来了一个又一个惊喜,基本上只要你有足够多的数据,足够深网络,足够强的算力,它就可以给你带来足够好的结果!
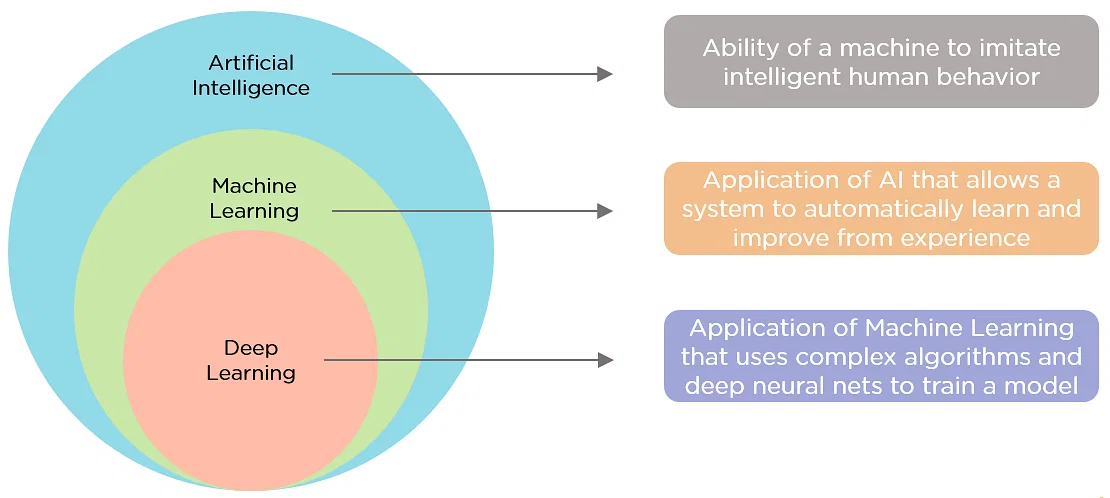
基于深度学习的AI技术
基于深度学习的AI技术分为两个阶段:模型训练 和 模型使用。
模型训练
模型训练是指使用大量的标注数据来训练一个深度神经网络,使其能够对输入数据进行正确的预测或分类。模型训练的过程包括以下几个步骤:
数据预处理:对原始数据进行清洗,归一化,增强,划分等操作,使其符合模型的输入要求。
网络搭建:根据任务的需求,选择合适的网络结构,如卷积神经网络,循环神经网络,生成对抗网络等,以及相应的参数,如层数,卷积核大小,激活函数,损失函数等。
网络训练:使用优化算法,如随机梯度下降,Adam等,不断更新网络的权重,使损失函数最小化,即模型的预测结果与真实标签的差距最小。
网络评估:使用一部分未参与训练的数据,如验证集或测试集,来评估模型的性能,如准确率,召回率,F1分数等,以及模型的泛化能力,即对未见过的数据的预测能力。
模型使用
模型使用是指将训练好的模型部署到实际的应用场景中,对新的输入数据进行预测或分类。模型使用的过程包括以下几个步骤:
数据输入:将需要处理的数据,如图片,视频,语音等,输入到模型中,进行相应的预处理,如裁剪,缩放,灰度化等。
数据输出:模型根据输入数据,输出相应的预测或分类结果,如人脸关键点,人眼位置,人眼状态等。
数据展示:将模型的输出结果,以合适的方式,如图形,文本,声音等,展示给用户,或者进行后续的处理,如特效制作,人脸美化等。
对于AI+OpenGL特效渲染来说,主要是使用别人训练好的模型,从不是从头训练。接下来咱们来了解一下有哪些比较好用的人脸模型。
常用的AI人脸模型库
为了方便开发者使用AI技术,有许多优秀的AI人脸模型库提供了丰富的功能和接口,可供你快速地部署和使用,如Google的MLKit, MediaPipe;腾讯的TengineKit等。当然除了上面几款免费的人脸识别AI库之外,像旷视的Face++、阿里、百度、华为等都有自己的限次免费或收费产品,大家可以自己去测试比较一下。
这里我重点向你介绍一下Google的两款产品MLKit和MediaPipe。
MLKit
MLKit是谷歌推出的一款移动端AI库,它针对移动设备进行了优化,可以在Android和iOS平台上使用。它主要完成两大类任务,计算机视觉和自然语言处理。
计算机视包括条形码扫描、人脸检测、人脸网格检测、文本识别、给图片加标签、对象检测和跟踪、数字墨水识别、姿势检测、自拍照细分等。
自然语言处理包括语言识别、翻译、智能回复、实体提取等。
其特点是功能齐全,接口简单,易使用。
MediaPipe
mediapipe是谷歌推出的一款跨平台的AI库,它提供了一系列的预训练模型,如人脸检测,人脸网格,手势识别,姿态估计等,以及一套灵活的流式处理框架,可以在Android,iOS,Web,桌面等平台上使用。它与MLKit相比,更底层,效率更高。 MLKit的部分功能就是由MediaPipe来提供支持的。
MediaPipe有很多优点,首先功能丰富,MediaPipe提供了多种类型的预训练模型,可以满足不同的应用场景,如人脸处理,人体分析,物体检测等。其次适配性好,MediaPipe可以在不同的平台和设备上运行,无需修改代码,可以实现一次开发,多端部署。可扩展性强,MediaPipe提供了一套流式处理框架,开发者可以自由地组合和修改模型,以及添加自定义的处理逻辑,实现定制化的功能。不过,MediaPipe的使用相对于MLKit来说稍复杂一些。
针对于不同的AI库,我们该如何选择呢?我的建议是对于实时性和跨平台性不高的应用选择MLKit,反之则应该选择MediaPipe。
对于我们要实现的大眼特效来说,这两款AI库都可满足我们的要求,其中,MLKit可以提供122个脸部关键点,而MediaPipe则可以提供多达468个脸部关键点。这里我们选择的是MLKit,因为它使用起来更简单些。
实现大眼特效的算法
通过前面介绍的MLKit或MediaPipe这类AI库,我们可以很轻松的定位人眼的位置。接下来咱们来了解一下实现大眼特效的算法。
关于大眼的算法有这样一篇论文, 其基本思想与我们之前讲的放大转场特效类似,我们只需以眼睛的中心点为中心,将靠近中心点的像素向外移动,即可得到放大的效果。
以上图为例,O为眼睛的中心,Radius为眼睛可以放大的最大距离,A为眼睛中的某一个点,想让眼睛放大,只需将 A 点移到 B 点,然后根据插值法,眼睛即可放大。
如何求得 B 点的坐标呢?可以使用下面的公式求得:
xd=k⋅(x1−x)+xyd=k⋅(y1−y)+y x_d = k \cdot (x_1 - x) + x y_d = k \cdot (y_1 - y) + y xd=k⋅(x1−x)+xyd=k⋅(y1−y)+y
在上述公式中,kkk为缩放因子,也可以称为放大缩小的倍数。
k=(1−(rrmax−1)2⋅a)⋅r k = (1-(\frac{r}{r_{max}} - 1) ^ 2 \cdot a ) \cdot r k=(1−(rmaxr−1)2⋅a)⋅r
这个公式其实就是弹簧变形公式,即弹簧压的越紧弹力越大,压的越松弹力越小。反应到眼睛上就是越靠近中心点放的越大,越远离中心点,放的越小,这样就会很自然。
公式中,rrr表示眼睛中的某个点到中心点的距离;rmaxr_{max}rmax表示眼睛到中心点的最大距离;KaTeX parse error: Expected '}', got '' at position 16: \frac{r}{r_{max̲}}表示弹簧的原始长度和最大长度的比值,它的范围是0到1,当弹簧没有受到任何外力时,它的值是0,当弹簧被拉伸到最大长度时,它的值是1。
但是,这个比值并不是我们想要的长度,因为我们想要的是距离眼睛中心越近的点放大得越多,距离眼睛中心越远的点放大得越少,而这个比值是相反的,它表示距离眼睛中心越近的点放大得越少,距离眼睛中心越远的点放大得越多。
为了解决这个问题,我们需要对这个比值做一些变换,让它符合我们的要求。首先,我们需要把这个比值减去1,这样就可以把它的范围从0到1变成-1到0,也就是把它的方向反过来,让距离眼睛中心越近的点的值越大,距离眼睛中心越远的点的值越小。这样,我们就得到了KaTeX parse error: Expected 'EOF', got '' at position 19: …rac{r}{r_{max}}̲ −1 ),它表示弹簧的原始长度和最大长度的差值,它的范围是-1到0,当弹簧没有受到任何外力时,它的值是-1,当弹簧被拉伸到最大长度时,它的值是0。
但我们还是希望取值的范围不要出现负数,因此我们对KaTeX parse error: Expected 'EOF', got '' at position 19: …rac{r}{r_{max}}̲ −1 )求平方,这样就将取值范围定位到了[0,1]这个范围内。同时,它也使得形变长度呈现一个二次曲线的变化,而不是一个线性的变化,从而形成一个更自然的放大效果。
公式中的aaa表示弹簧的形变系数,它的范围是0到1,它决定了弹簧的形变长度的最大值,也就是弹簧的最大缩放因子。当a的值越大时,弹簧的形变长度越大,也就是弹簧的缩放效果越明显,反之亦然。
这样,KaTeX parse error: Expected 'EOF', got '' at position 19: …rac{r}{r_{max}}̲−1)^2 \cdot a表示它的取值范围是[0,a],当弹簧没有受到任何外力时,它的值是aaa,当弹簧被拉伸到最大长度时,它的值是0。这一项的作用是让弹簧的形变长度随着aaa的变化而变化,从而实现不同的缩放效果。
那么,KaTeX parse error: Expected 'EOF', got '' at position 21: …rac{r}{r_{max}}̲−1)^2 \cdot a表示的就是在[1-a,1]这个范围内取值,当弹簧没有受到任何外力时,它的值是1 - a,当弹簧被拉伸到最大长度时,它的值是1。这一项的作用是让弹簧的形变长度随着r的变化而变化,从而实现不同的放大效果。
通过上面的讲解,我就将大眼特效的算法向你介绍清楚了。
具体实现
上面虽然我们将公式中各个部分的含义介绍清楚了,但还有几件事儿没有交待清楚。第一个aaa该如何取值呢?一般情况下,我们通过如下公式计算aaa的值:
a=15⋅512⋅512width⋅height/100 a = 15 \cdot \frac{512 \cdot 512}{width \cdot height} / 100 a=15⋅width⋅height512⋅512/100
其中,15 表示眼睛半径的像素距离;512x512表示标准图片的大小,让它除以实际图片的宽高使得不同分辨率的图片都可以得到相同的放大效果;最后除以 100 是把aaa限定在[0,1]之间。
另外,Radius该如何设置呢?如下图所示: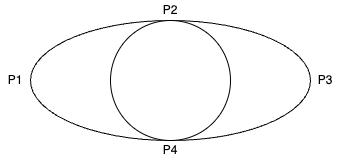
Radius表示的是人眼最大的取值范围,在上图中人眼的最大范围应该是P1到P3的距离。由于左右眼可能长度还不一样,因此应该分别取左右眼的Radius,再从中取最大值。计算公式如下:
KaTeX parse error: Expected 'EOF', got '\\' at position 16: R = |P_1-P_3| \̲\̲ Radius = max(R…
将上成的这些点弄清楚后,我们就可以将大眼特效的Shader代码写出来了,代码如下:
...
/**
cCoord: 当前采样纹理坐标
cPos: 形变圆中心坐标
rMax: 形变作用圆半径
alpha: 缩放系数
*/
vec2 newCoord(vec2 cCoord, vec2 cPos, float rMax, float alpha){
// 计算当前纹理坐标到眼睛中心的距离,对应 r
float r = distance(cCoord, cPos);
float k = 1.0 - pow(r / rMax - 1.0, 2.0) * alpha;
vec2 dCoord = cCoord
if (r < rMax){
dCoord = cPos + k * (cCoord - cPos);
}
return dCoord;
}
void main(){
float disLeft = distance(leftEyeCoord_1, leftEyeCoord_2);
float disRight = distance(rightEyeCoord_1, rightEyeCoord_2);
// 缩放圆作用半径rMax
float rMax = max(disLeft,disRight);
float a = 15x512x512/(width*height) / 100;
// aCoord是整副图像,
vec2 newCoord = newCoord(aCoord, left_eye_center, rMax, a); // 求左眼放大位置的采样点
newCoord = newCoord(newCoord, right_eye_center, rMax, a); // 求右眼放大位置的采样点
// 此newCoord就是大眼像素坐标值
gl_FragColor = texture2D(vTexture, newCoord);
}
...
至此,我们就使用 AI + OpenGL实现了大眼特效!
小结
本文介绍了如何利用AI和OpenGLES实现大眼特效,首先我们了解了基于深度学习的AI技术,分为模型训练和模型使用。 之后我向你介绍了两个常用的AI库MLKit 和 MediaPipe,其中MLKit用在移动端,其API简单易用;而MediaPipe具用跨平台的优势,功能强大。无论哪种AI库都可以让我们轻松获取人眼坐标。接下来我详细阐述了实现大眼特效的算法,我们利用AI获取人眼坐标,再根据弹簧公式就可以很容易的实现大眼特效了。
这篇关于AI+OpenGL实现大眼特效的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-11-15Tailwind开发入门教程:从零开始搭建第一个项目
- 2024-11-14Emotion教程:新手入门必备指南
- 2024-11-14音频生成的秘密武器:扩散模型在音乐创作中的应用
- 2024-11-14从数据科学家到AI开发者:2023年构建生成式AI网站应用的经验谈
- 2024-11-14基于AI的智能调试助手创业点子:用代码样例打造你的调试神器!
- 2024-11-14受控组件学习:从入门到初步掌握
- 2024-11-14Emotion学习入门指南
- 2024-11-14Emotion学习入门指南
- 2024-11-14获取参数学习:初学者指南
- 2024-11-14受控组件学习:从入门到实践



