全网最全图解Kafka适用场景
2023/11/24 21:03:02

本文主要是介绍全网最全图解Kafka适用场景,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
消息系统
消息系统被用于各种场景,如解耦数据生产者,缓存未处理的消息。Kafka 可作为传统的消息系统的替代者,与传统消息系统相比,kafka有更好的吞吐量、更好的可用性,这有利于处理大规模的消息。
根据经验,通常消息传递对吞吐量要求较低,但可能要求较低的端到端延迟,并经常依赖kafka可靠的durable机制。
在这方面,Kafka可以与传统的消息传递系统(ActiveMQ 和RabbitMQ)相媲美。
存储系统
写入到kafka中的数据是落地到了磁盘上,并且有冗余备份,kafka允许producer等待确认,通过配置,可实现直到所有的replication完成复制才算写入成功,这样可保证数据的可用性。
Kafka认真对待存储,并允许client自行控制读取位置,你可以认为kafka是-种特殊的文件系统,它能够提供高性能、低延迟、高可用的日志提交存储。
日志聚合
日志系统一般需要如下功能:日志的收集、清洗、聚合、存储、展示。Kafka常用来替代其他日志聚合解决方案。
和Scribe、Flume相比,Kafka提供同样好的性能、更健壮的堆积保障、更低的端到端延迟。
日志会落地,导致kafka做日志聚合更昂贵。
kafka可实现日志的:
- 清洗(需编码)
- 聚合(可靠但昂贵,因需落地磁盘)
- 存储
ELK是现在比较流行的日志系统。在kafka的配合 下才是更成熟的方案,kafka在ELK技术栈中,主要起到buffer的作用,必要时可进行日志的汇流。
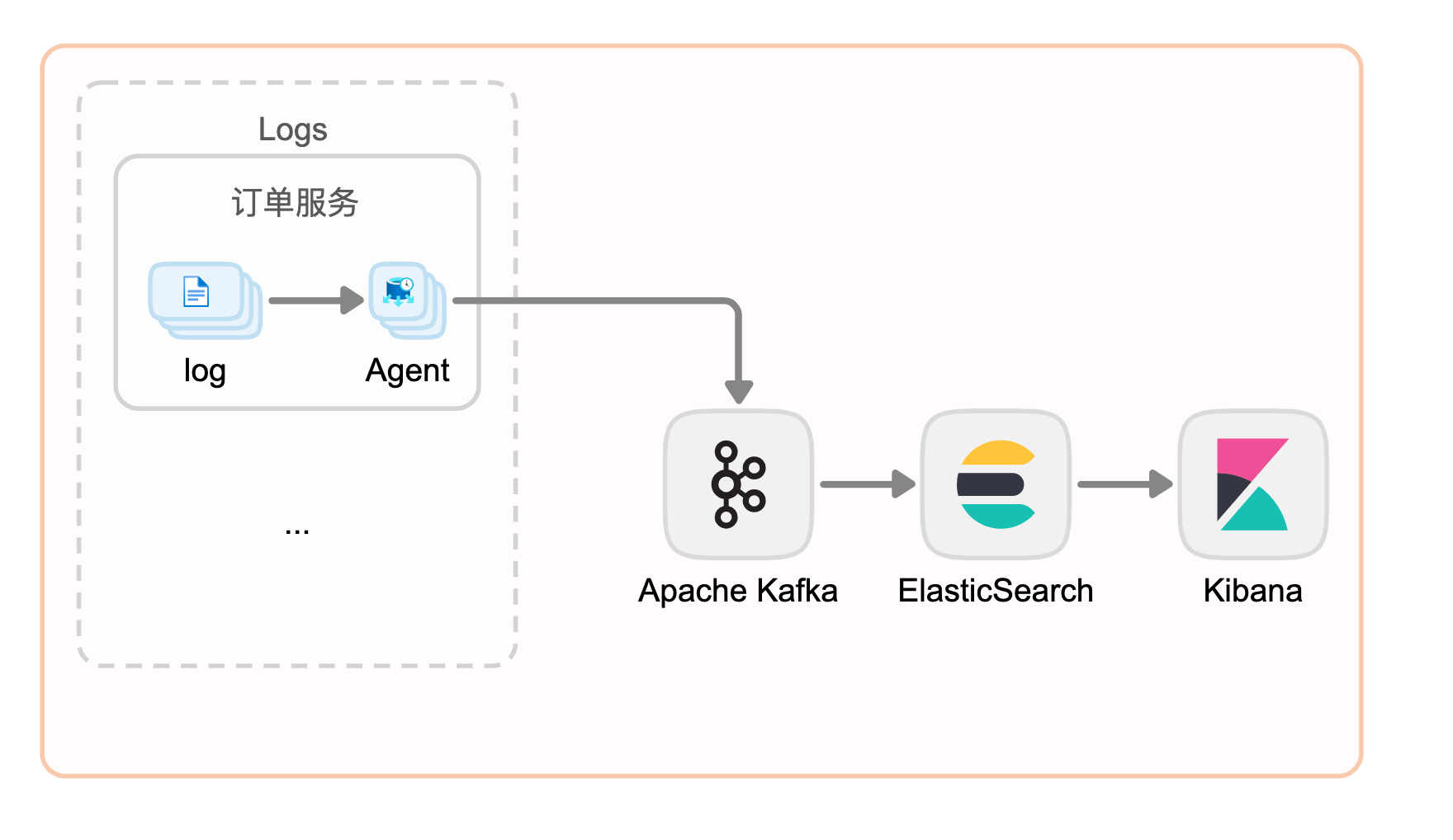
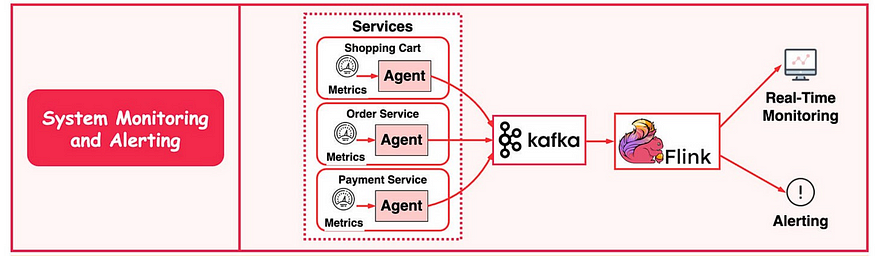
系统监控与报警
与日志分析系统类似,我们需要收集系统指标以进行监控和故障排除。
区别在于指标是结构化数据,而日志是非结构化文本。指标数据发送到 Kafka 并在 Flink 中聚合。聚合数据由实时监控仪表板和警报系统(例如 PagerDuty)使用。
Commit Log
Kafka 可充当分布式系统的一种外部提交日志。日志有助于在节点之间复制数据,并充当故障节点恢复数据的重新同步机制。
Kafka 中的日志压缩功能有助于支持这种用法。
跟踪网站活动 - 推荐系统
kafka的最初始作用就是,将用户行为跟踪管道重构为一组实时发布-订阅源。
把网站活动(浏览网页、搜索或其他的用户操作)发布到中心topics中,每种活动类型对应一个topic。基于这些订阅源,能够实现一系列用例,如实时处理、实时监视、批量地将Kafka的数据加载到Hadoop或离线数仓系统,进行离线数据处理并生成报告。
每个用户浏览网页时都生成了许多活动信息,因此活动跟踪的数据量通常非常大。(Kafka实际应用)
像亚马逊这样的电子商务网站使用过去的行为和相似的用户来计算产品推荐。
下图展示了推荐系统的工作原理。 Kafka 传输原始点击流数据,Flink 对其进行处理,模型训练则使用来自数据湖的聚合数据。
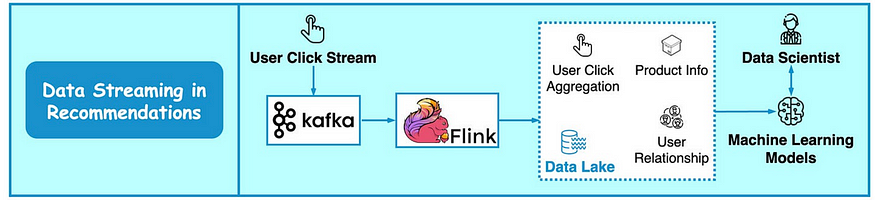 这使得能够持续改进每个用户的推荐的相关性。 Kafka 的另一个重要用例是实时点击流分析。
这使得能够持续改进每个用户的推荐的相关性。 Kafka 的另一个重要用例是实时点击流分析。
流处理 - kafka stream API
Kafka社区认为仅仅提供数据生产、消费机制是不够的,他们还要提供流数据实时处理机制
从0.10.0.0开始, Kafka通过提供Strearms API来提供轻量,但功能强大的流处理。实际上就是Streams API帮助解决流引用中一些棘手的问题,比如:
- 处理无序的数据
- 代码变化后再次处理数据
- 进行有状态的流式计算
Streams API的流处理包含多个阶段,从input topics消费数据,做各种处理,将结果写入到目标topic, Streans API基于kafka提供的核心原语构建,它使用kafka consumer、 producer来输入、输出,用Kfka来做状态存储。
流处理框架: flink、spark streaming、Storm本是正统流处理框架,Kafka在流处理更多扮演流存储角色。
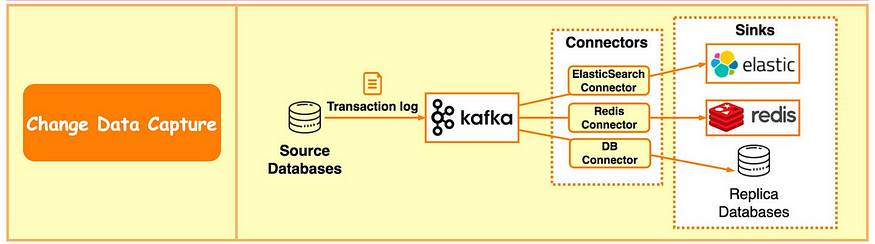
CDC( Change data capture,变更数据捕获)
- CDC将数据库变化流式传输到其他系统,以进行复制或缓存/索引更新
- Kafka 还是构建data pipeline的绝佳工具,使用它从各种来源获取数据、应用处理规则并将数据存储在仓库、数据湖或数据网格中
- 如下,事务日志发送到 Kafka 并由 ElasticSearch、Redis 和辅助数据库摄取。
系统迁移
升级遗留服务具有挑战性:
- 旧语言
- 复杂逻辑
- 缺乏测试
可利用MQ降低风险。
为升级订单服务,更新旧的订单服务以消费来自 Kafka 的输入并将结果写入 ORDER topic。新订单服务使用相同的输入并将结果写入 ORDERNEW topic:
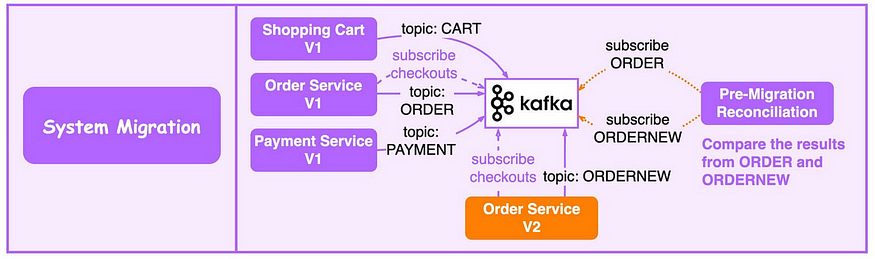
Reconciliation调节服务比较 ORDER 和 ORDERNEW。如果它们相同,则新服务通过测试。
事件溯源
如果将事件作为系统中的一等公民(即事实来源),那存储应用程序的状态就是一系列事件,系统中的其他所有内容都可根据这些持久且不可变的事件重新计算。
事件溯源就是捕获一系列事件中状态的变化。通常使用 Kafka 作为主要事件存储。如果发生任何故障、回滚或需要重建状态,可随时重新应用 Kafka 中的事件。
这篇关于全网最全图解Kafka适用场景的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-21MQ-2烟雾传感器详解
- 2024-12-09Kafka消息丢失资料:新手入门指南
- 2024-12-07Kafka消息队列入门:轻松掌握Kafka消息队列
- 2024-12-07Kafka消息队列入门:轻松掌握消息队列基础知识
- 2024-12-07Kafka重复消费入门:轻松掌握Kafka消费的注意事项与实践
- 2024-12-07Kafka重复消费入门教程
- 2024-12-07RabbitMQ入门详解:新手必看的简单教程
- 2024-12-07RabbitMQ入门:新手必读教程
- 2024-12-06Kafka解耦学习入门教程
- 2024-12-06Kafka入门教程:快速上手指南





