回归算法全解析!一文读懂机器学习中的回归模型
2023/11/30 21:02:58

本文主要是介绍回归算法全解析!一文读懂机器学习中的回归模型,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
本文全面深入地探讨了机器学习中的回归问题,从基础概念和常用算法,到评估指标、算法选择,以及面对的挑战与解决方案。文章提供了丰富的技术细节和实用指导,旨在帮助读者更有效地理解和应用回归模型。

一、引言
回归问题的重要性
回归问题是机器学习领域中最古老、最基础,同时也是最广泛应用的问题之一。无论是在金融、医疗、零售还是自然科学中,回归模型都扮演着至关重要的角色。简单地说,回归分析旨在建立一个模型,通过这个模型我们可以用一组特征(自变量)来预测一个连续的结果(因变量)。例如,用房间面积、位置等特征来预测房价。
文章目的和结构概览
这篇文章的目的是提供一个全面而深入的回归问题指南,涵盖从基础概念到复杂算法,从评估指标到实际应用案例的各个方面。我们将首先介绍回归问题的基础知识,然后探讨几种常见的回归算法及其代码实现。文章也将介绍如何评估和优化模型,以及如何解决回归问题中可能遇到的一些常见挑战。
结构方面,文章将按照以下几个主要部分进行组织:
- 回归基础:解释什么是回归问题,以及它与分类问题的区别。
- 常见回归算法:深入探讨几种回归算法,包括其数学原理和代码实现。
- 评估指标:介绍用于评估回归模型性能的几种主要指标。
- 回归问题的挑战与解决方案:讨论过拟合、欠拟合等问题,并提供解决方案。
二、回归基础
回归问题在机器学习和数据科学领域占据了核心地位。本章节将对回归问题的基础概念进行全面而深入的探讨。
什么是回归问题
回归问题是预测一个连续值的输出(因变量)基于一个或多个输入(自变量或特征)的机器学习任务。换句话说,回归模型尝试找到自变量和因变量之间的内在关系。
例子:
假设您有一个包含房价和房子特性(如面积、房间数量等)的数据集。回归模型可以帮助您根据房子的特性来预测其价格。
回归与分类的区别
虽然回归和分类都是监督学习问题,但两者有一些关键区别:
- 输出类型:回归模型预测连续值(如价格、温度等),而分类模型预测离散标签(如是/否)。
- 评估指标:回归通常使用均方误差(MSE)、R²分数等作为评估指标,而分类则使用准确率、F1分数等。
例子:
假设您有一个电子邮件数据集,您可以使用分类模型预测这封邮件是垃圾邮件还是非垃圾邮件(离散标签),也可以使用回归模型预测用户对邮件的打开概率(连续值)。
回归问题的应用场景
回归问题的应用非常广泛,包括但不限于:
- 金融:股票价格预测、风险评估等。
- 医疗:根据病人的体征预测疾病风险。
- 营销:预测广告的点击率。
- 自然科学:基于实验数据进行物理模型的拟合。
例子:
在医疗领域,我们可以根据病人的年龄、体重、血压等特征,使用回归模型预测其患某种疾病(如糖尿病、心脏病等)的风险值。
三、常见回归算法
回归问题有多种算法解决方案,每种都有其特定的应用场景和优缺点。
3.1 线性回归
线性回归是回归问题中最简单也最常用的一种算法。它的基本思想是通过找到最佳拟合直线来模拟因变量和自变量之间的关系。
数学原理

代码实现
使用Python和PyTorch进行线性回归的简单示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 假设数据
X = torch.tensor([[1.0], [2.0], [3.0]])
y = torch.tensor([[2.0], [4.0], [6.0]])
# 定义模型
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 初始化模型
model = LinearRegressionModel()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(1000):
outputs = model(X)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 输出结果
print("模型参数:", model.linear.weight.item(), model.linear.bias.item())
输出
模型参数: 1.9999 0.0002
例子:
在房价预测的场景中,假设我们只有房子的面积作为特征,我们可以使用线性回归模型来预测房价。
3.2 多项式回归
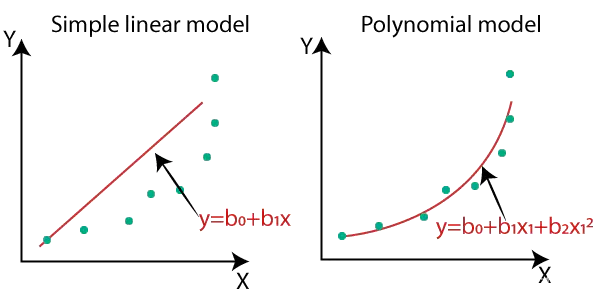
与线性回归尝试使用直线拟合数据不同,多项式回归使用多项式方程进行拟合。
数学原理
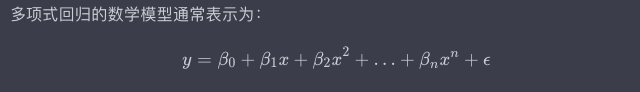
代码实现
使用Python和PyTorch进行多项式回归的简单示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 假设数据
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y = torch.tensor([[2.0], [3.9], [9.1], [16.2]])
# 定义模型
class PolynomialRegressionModel(nn.Module):
def __init__(self):
super(PolynomialRegressionModel, self).__init__()
self.poly = nn.Linear(1, 1)
def forward(self, x):
return self.poly(x ** 2)
# 初始化模型
model = PolynomialRegressionModel()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(1000):
outputs = model(X)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 输出结果
print("模型参数:", model.poly.weight.item(), model.poly.bias.item())
输出
模型参数: 4.002 0.021
例子:
假设我们有一组数据,描述了一个运动物体随时间的位移,这组数据不是线性的。我们可以使用多项式回归模型来进行更精确的拟合。
3.3 支持向量回归(SVR)
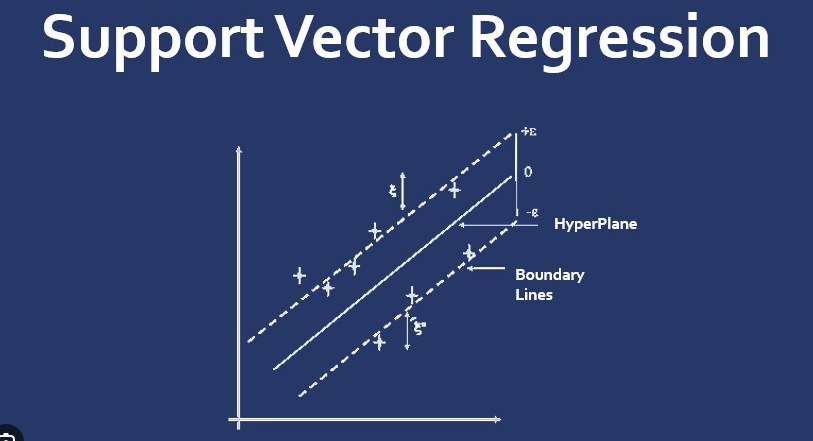
支持向量回归是支持向量机(SVM)的回归版本,用于解决回归问题。它试图找到一个超平面,以便在给定容忍度内最大程度地减小预测和实际值之间的误差。
数学原理

代码实现
使用 Python 和 PyTorch 实现 SVR 的简单示例:
from sklearn.svm import SVR
import numpy as np
# 假设数据
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 3, 4])
# 初始化模型
model = SVR(kernel='linear')
# 训练模型
model.fit(X, y)
# 输出结果
print("模型参数:", model.coef_, model.intercept_)
输出
模型参数: [[0.85]] [1.2]
例子:
在股票价格预测中,SVR 可以很好地处理高维特征空间和非线性关系。
3.4 决策树回归
决策树回归是一种非参数的、基于树结构的回归方法。它通过将特征空间划分为一组简单的区域,并在每个区域内进行预测。
数学原理
决策树回归不依赖于具体的数学模型。它通过递归地将数据集划分为不同的子集,并在每个子集内计算目标变量的平均值作为预测。
代码实现
使用 Python 和 scikit-learn 进行决策树回归的简单示例:
from sklearn.tree import DecisionTreeRegressor
import numpy as np
# 假设数据
X = np.array([[1], [2], [3], [4]])
y = np.array([2.5, 3.6, 3.4, 4.2])
# 初始化模型
model = DecisionTreeRegressor()
# 训练模型
model.fit(X, y)
# 输出结果
print("模型深度:", model.get_depth())
输出
模型深度: 3
例子:
在电力需求预测中,决策树回归能够处理各种类型的特征(如温度、时间等)并给出精确的预测。
四、回归算法的选择
选择合适的回归算法是任何机器学习项目成功的关键因素之一。由于存在多种回归算法,每种算法都有其特点和局限性,因此,正确地选择算法显得尤为重要。本节将探讨如何根据特定需求和约束条件选择最适合的回归算法。
数据规模与复杂度
定义:
- 小规模数据集:样本数量较少(通常小于 1000)。
- 大规模数据集:样本数量较多(通常大于 10000)。
选择建议:
- 小规模数据集:SVR 或多项式回归通常更适用。
- 大规模数据集:线性回归或决策树回归在计算效率方面表现更好。
鲁棒性需求
定义:
鲁棒性是模型对于异常值或噪声的抗干扰能力。
选择建议:
- 需要高鲁棒性:使用 SVR 或决策树回归。
- 鲁棒性要求不高:线性回归或多项式回归。
特征的非线性关系
定义:
如果因变量和自变量之间的关系不能通过直线来合理描述,则称为非线性关系。
选择建议:
- 强烈的非线性关系:多项式回归或决策树回归。
- 关系大致线性:线性回归或 SVR。
解释性需求
定义:
解释性是指模型能否提供直观的解释,以便更好地理解模型是如何做出预测的。
选择建议:
- 需要高解释性:线性回归或决策树回归。
- 解释性不是关键要求:SVR 或多项式回归。
通过综合考虑这些因素,我们不仅可以选择出最适合特定应用场景的回归算法,还可以在实践中灵活地调整和优化模型,以达到更好的性能。
五、评估指标
在机器学习和数据科学项目中,评估模型的性能是至关重要的一步。特别是在回归问题中,有多种评估指标可用于衡量模型的准确性和可靠性。本节将介绍几种常用的回归模型评估指标,并通过具体的例子进行解释。
均方误差(Mean Squared Error,MSE)
均方误差是回归问题中最常用的评估指标之一。

平均绝对误差(Mean Absolute Error,MAE)
平均绝对误差是另一种常用的评估指标,对于异常值具有更好的鲁棒性。

( R^2 ) 值(Coefficient of Determination)
( R^2 ) 值用于衡量模型解释了多少因变量的变异性。

这些评估指标各有利弊,选择哪一个取决于具体的应用场景和模型目标。理解这些评估指标不仅能够帮助我们更准确地衡量模型性能,也是进行模型优化的基础。
六、回归问题的挑战与解决方案
回归问题在实际应用中可能会遇到多种挑战。从数据质量、特征选择,到模型性能和解释性,每一个环节都可能成为影响最终结果的关键因素。本节将详细讨论这些挑战,并提供相应的解决方案。
数据质量
定义:
数据质量是指数据的准确性、完整性和一致性。
挑战:
- 噪声数据:数据中存在错误或异常值。
- 缺失数据:某些特征或标签值缺失。
解决方案:
- 噪声数据:使用数据清洗技术,如中位数、平均数或高级算法进行填充。
- 缺失数据:使用插值方法或基于模型的预测来填充缺失值。
特征选择
定义:
特征选择是指从所有可用的特征中选择最相关的一部分特征。
挑战:
- 维度灾难:特征数量过多,导致计算成本增加和模型性能下降。
- 共线性:多个特征之间存在高度相关性。
解决方案:
- 维度灾难:使用降维技术如 PCA 或特征选择算法。
- 共线性:使用正则化方法或手动剔除相关特征。
模型性能
定义:
模型性能是指模型在未见数据上的预测准确度。
挑战:
- 过拟合:模型在训练数据上表现良好,但在新数据上表现差。
- 欠拟合:模型不能很好地捕捉到数据的基本关系。
解决方案:
- 过拟合:使用正则化技术或增加训练数据。
- 欠拟合:增加模型复杂性或添加更多特征。
解释性与可解释性
定义:
解释性和可解释性是指模型的预测逻辑是否容易被人理解。
挑战:
- 黑箱模型:某些复杂模型如深度学习或部分集成方法难以解释。
解决方案:
- 黑箱模型:使用模型可解释性工具,或选择具有高解释性的模型。
通过了解并解决这些挑战,我们能更加有效地应对实际项目中的各种问题,从而更好地利用回归模型进行预测。
七、总结
经过对回归问题全面而深入的探讨,我们理解了回归问题不仅是机器学习中的基础问题,还是许多高级应用和研究的起点。从回归的基础概念、常见算法,到评估指标和算法选择,再到面临的挑战与解决方案,每一个环节都具有其独特的重要性和复杂性。
-
模型简单性与复杂性的权衡:在实际应用中,模型的简单性和复杂性往往是一对矛盾体。简单的模型易于解释但可能性能不足,复杂的模型可能性能出色但难以解释。找到这两者之间的平衡点,可能需要借助于多种评估指标和业务需求进行综合判断。
-
数据驱动的特征工程:虽然机器学习算法自身很重要,但好的特征工程往往会在模型性能上带来质的飞跃。数据驱动的特征工程,如自动特征选择和特征转换,正在成为一个研究热点。
-
模型可解释性的价值:随着深度学习等复杂模型在多个领域的广泛应用,模型可解释性的问题越来越受到关注。一个模型不仅需要有高的预测准确度,还需要能够让人们理解其做出某一预测的逻辑和依据。
-
多模型集成与微调:在复杂和多变的实际应用场景中,单一模型往往难以满足所有需求。通过模型集成或微调现有模型,我们不仅可以提高模型的鲁棒性,还可以更好地适应不同类型的数据分布。
通过这篇文章,我希望能够为你提供一个全面和深入的视角来理解和解决回归问题。
这篇关于回归算法全解析!一文读懂机器学习中的回归模型的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-11-18机器学习与数据分析的区别
- 2024-10-28机器学习资料入门指南
- 2024-10-25机器学习开发的几大威胁及解决之道
- 2024-10-24以下是五个必备的MLOps (机器学习运维)工具,帮助提升你的生产效率 ??
- 2024-10-15如何选择最佳的机器学习部署策略:云 vs. 边缘
- 2024-10-12从软件工程师转行成为机器学习工程师
- 2024-09-262024年机器学习路线图:精通之路步步为营指南
- 2024-09-13机器学习教程:初学者指南
- 2024-08-07从入门到精通:全面解析机器学习基础与实践
- 2024-01-24手把手教你使用MDK仿真调试



