Kubernetes核心组件之kube-proxy实现原理
2024/1/8 21:02:16

本文主要是介绍Kubernetes核心组件之kube-proxy实现原理,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
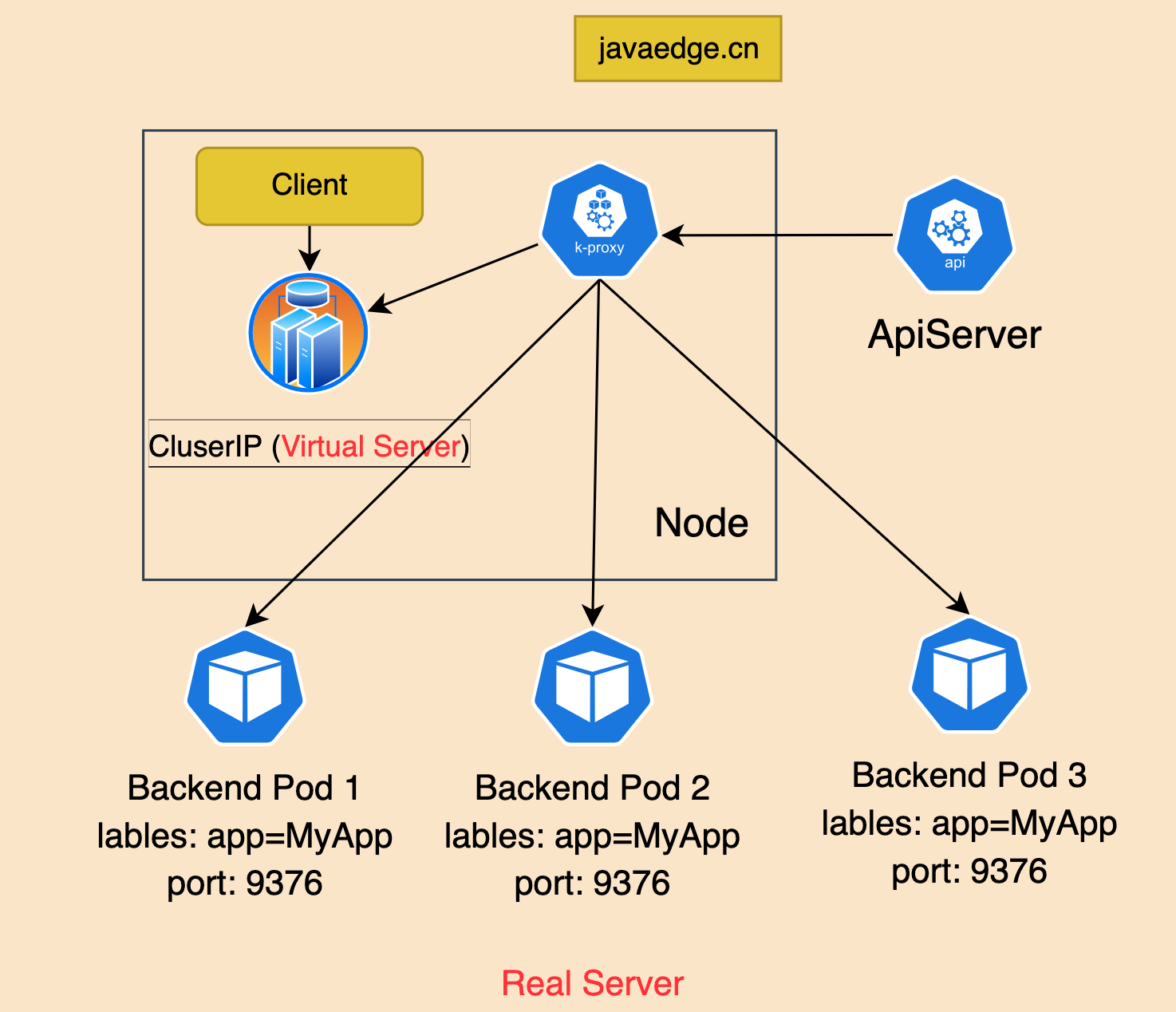
kube-proxy,负责为Service提供集群内部的服务发现和负载均衡。
1 介绍
了解不同网络组件的工作原理有助于正确设计和配置它们,以满足你的应用程序需求。
在Kubernetes网络的背后,有一个在幕后工作的组件。它将你的服务(Services)转化为一些可用的网络规则。这个组件被称为 Kube-Proxy。
本文展示Kube-Proxy的工作原理。我们将解释创建服务时发生的流程。并展示Kube-Proxy创建的一些示例规则。
2 什么是Kube-Proxy
Kubernetes中的Pods是临时的,可随时被终止或重启。由于这种行为,我们不能依赖于它们的IP地址,因为它们总是在变。
这就是 Service 对象发挥作用的地方。Services为Pods提供一个稳定的IP地址,用于连接Pods。每个Service与一组Pods相关联。当流量到达Service时,根据规则将其重定向到相应的后端Pods。
“Service到Pod”映射在网络层如何实现?
这就是Kube-Proxy的作用。
Kube-Proxy是安装在 每个节点 中的Kubernetes代理。它监视与Service对象及其端点相关的更改。然后将这些更改转换为节点内的实际网络规则。Kube-Proxy通常以 DaemonSet 的形式在集群中运行。但也可直接作为节点上的Linux进程安装。取决于你的集群安装类型:
- 用 kubeadm,它将以DaemonSet的形式安装Kube-Proxy
- 用官方Linux tarball二进制文件 手动安装集群组件,它将直接作为节点上的进程运行
3 工作原理
安装Kube-Proxy后,它将与API服务器进行身份验证。当新的Service或端点被添加或移除时,API服务器会将这些更改传递给Kube-Proxy。
Kube-Proxy然后在节点内将这些更改应用为 NAT 规则。这些NAT规则简单将Service IP映射到Pod IP。
当流量被发送到一个Service时,根据这些规则,它将被重定向到相应的后端Pods。
实例
有一类型为ClusterIP的Service SVC01。创建此Service时,API服务器将检查要与该Service关联的Pods。因此,它将查找具有与Service的 label selector 匹配的 labels 的Pods。称这些为 Pod01 和 Pod02。
现在APIServer将创建一个称为 endpoint 的抽象。每个endpoint代表一个Pod的IP。现在,SVC01与2个端点关联,对应我们的Pods。称这些为 EP01 和 EP02。
现在API服务器将 SVC01 的IP地址映射到2个IP地址 EP01 和 EP02。
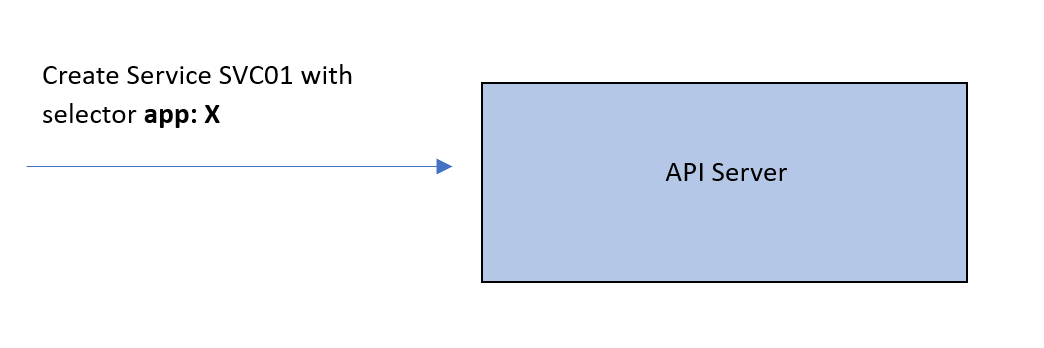
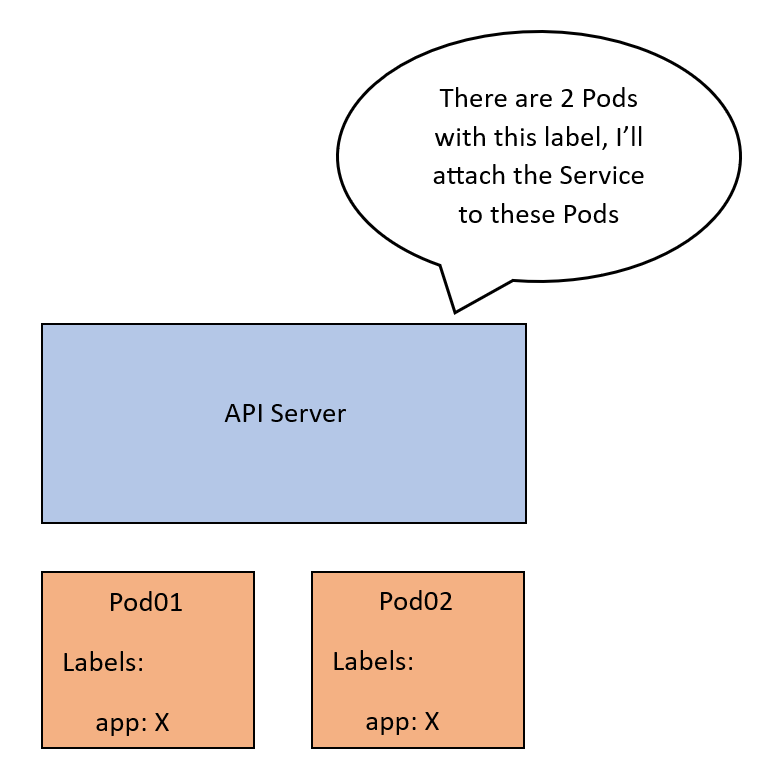
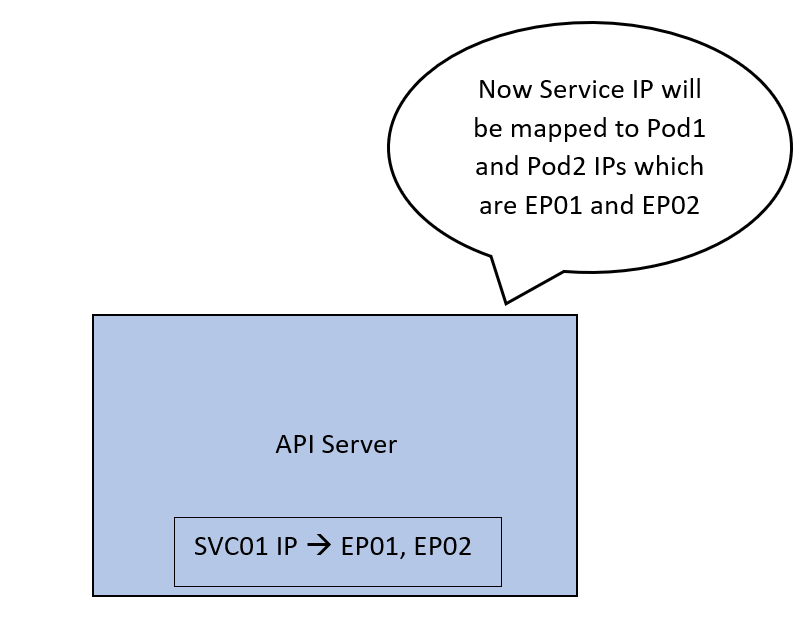
所有这些配置目前只是控制平面的一部分。我们希望这个映射实际上应用在网络上。一旦应用,到 SVC01 IP的流量将被转发到 EP01 或 EP02。
这就是Kube-Proxy的作用。API服务器将向每个节点的Kube-Proxy宣传这些更新。然后Kube-Proxy将其应用为节点内部的规则。
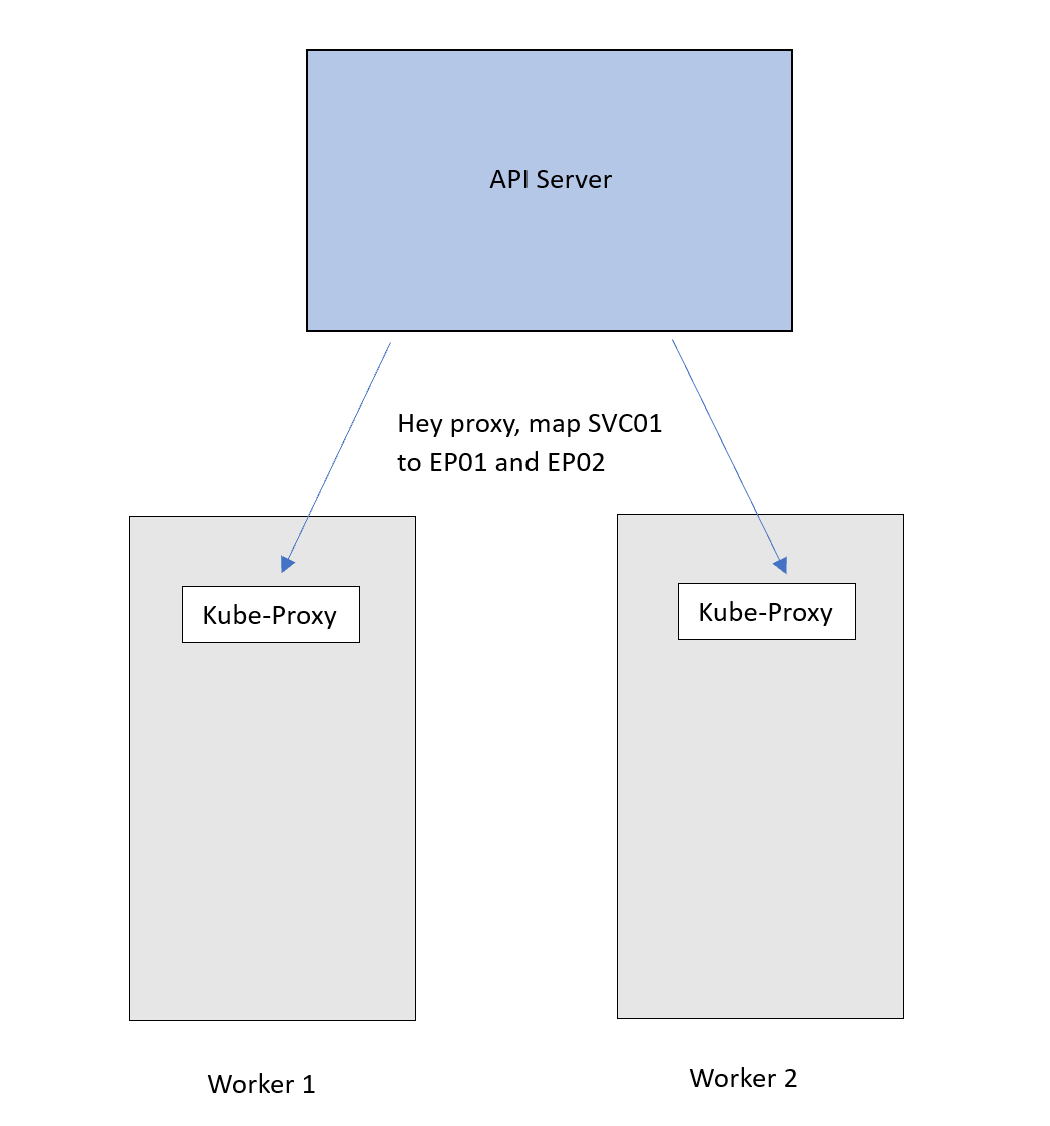
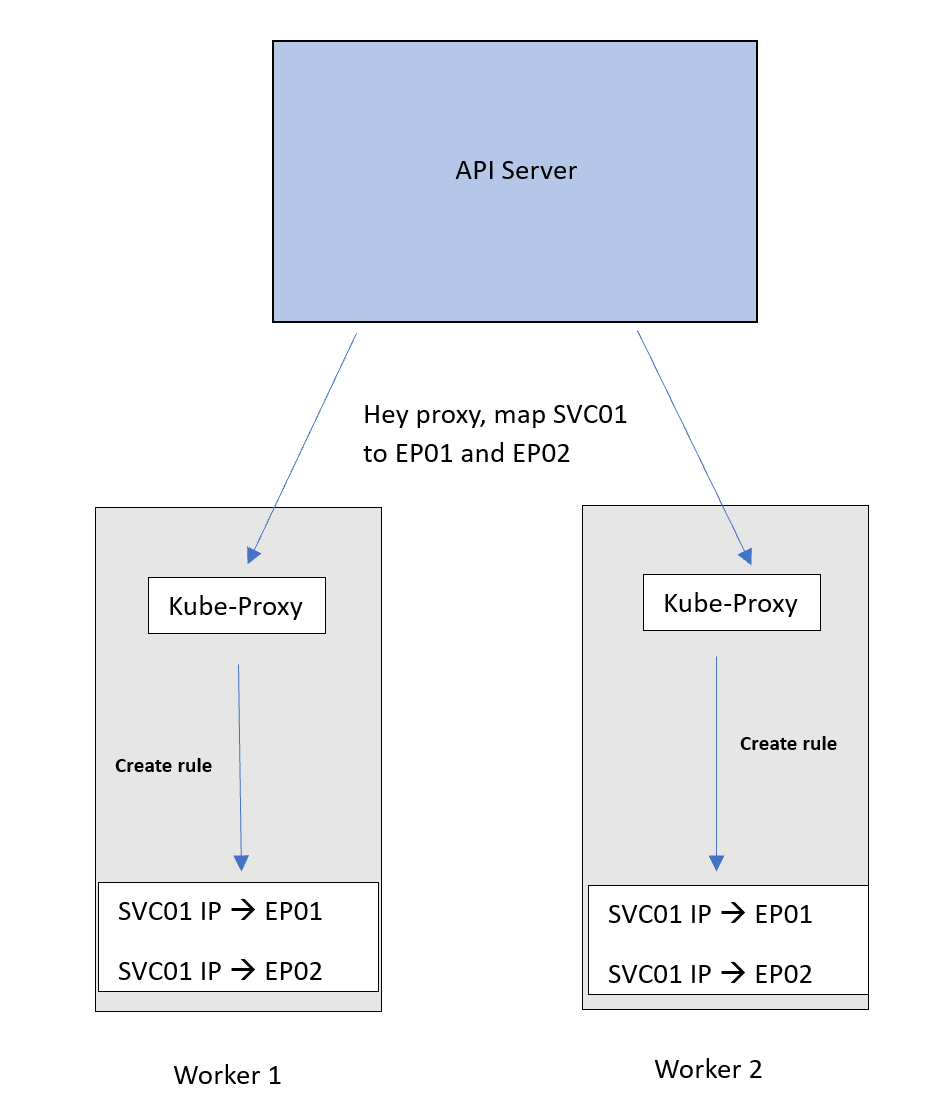
现在,流向SVC01 IP的流量将遵循这个 DNAT 规则,并被转发到Pods。请记住,EP01和EP02基本上是Pods的IP。
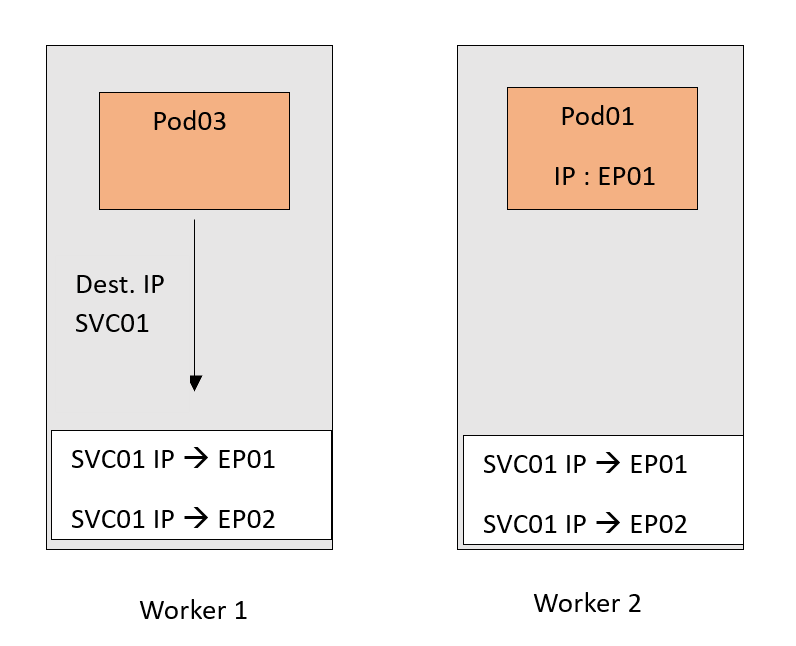
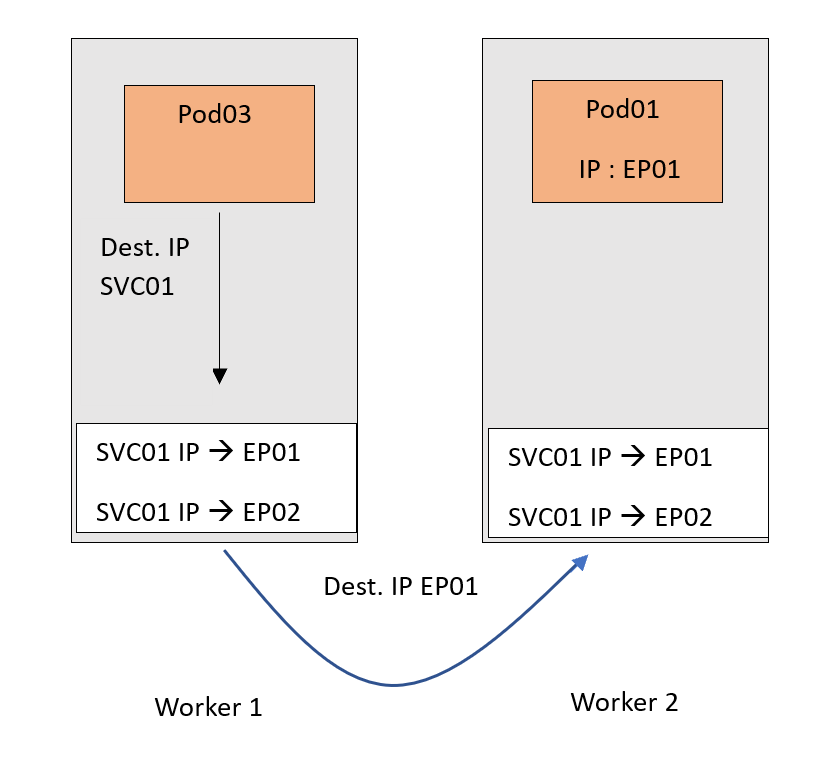
当然,我试图尽量简化情景。这只是为了集中关注Kube-Proxy的重要部分。然而,值得一提的有几点:
-
Service和endpoint是 IP和端口 映射,而不仅仅是IP。
-
在示例中,DNAT翻译发生在 源节点 上。这是因为我们使用了 ClusterIP 类型的Service。这就是为什么ClusterIP永远不会路由到集群外部的原因。它只能从集群内部访问,因为它基本上是一个内部NAT规则。换句话说,集群外部没有人知道这个IP。
-
如果使用其他类型Service,则在节点内部安装其他规则。它们可能被分开放置在所谓的 chain 中。虽然这超出了主题的范围,但链是Linux机器中的一组规则。它们有一个特定的类型,并且按照流量路径中的特定顺序应用。
-
NAT规则随机选择一个Pod。然而,此行为可能取决于Kube-Proxy的“模式”。
4 Kube-Proxy模式
Kube-Proxy可以不同模式运行。每个模式决定了Kube-Proxy如何实现我们提到的NAT规则。由于每个模式都有其优缺。
4.0 userspace 模式
k8s v1.2 就被淘汰:

在 proxy 的用户空间监听一个端口,所有的 svc 都转到这个端口,然后 proxy 内部应用层对其进行转发。proxy 会为每一个 svc 随机监听一个端口,并增加一个 iptables 规则。
从客户端到 ClusterIP:Port 的报文都会通过 iptables 规则被重定向到 Proxy Port,Kube-Proxy 收到报文后,然后分发给对应 Pod。

缺点
该模式下,流量的转发主要是在用户空间完成,客户端请求需借助 iptables 规则找到对应 Proxy Port,因为 iptables 在内核空间,这里的请求就会有一次从用户态=>内核态再返回=>用户态的传递过程, 一定程度降低服务性能。
默认用户空间模式下的 kube-proxy 通过轮转算法选择后端。
4.1 IPtables模式
默认和目前最广泛使用的模式。该模式下的Kube-Proxy依赖于Linux的一个特性IPtables。
iptables
Linux 中最常用的一种防火墙工具,还可用作 IP 转发和简单的负载均衡功能。基于 Linux 中的 netfilter 内核模块实现。 Netfilter 在协议中添加了一些钩子,它允许内核模块通过这些钩子注册回调函数,这样经过钩子的所有数据都会被注册在响应钩子上的函数处理,包括修改数据包内容、给数据包打标记或者丢掉数据包等。iptables 是运行在用户态的一个程序,通过 netlink 和内核的 netfilter 框架打交道,具有足够的灵活性来处理各种常见的数据包操作和过滤需求。它允许将灵活的规则序列附加到内核的数据包处理管道中的各种钩子上。
Netfilter 是 Linux 2.4.x 引入的一个子系统,它作为一个通用的、抽象的框架,提供一整套的 hook 函数的管理机制,使得诸如数据包过滤、网络地址转换(NAT)和基于协议类型的连接跟踪成为了可能。
在 kubernetes v1.2 之后 iptables 成为默认代理模式,这种模式下,kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会安装 iptables 规则,从而捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某个上面。因为流量转发都是在内核进行的,所以性能更高更加可靠。
IPtables作为一个内部的数据包处理和过滤组件。它检查发往和发自Linux机器的流量。然后,它对匹配特定条件的数据包应用特定的规则。
在运行此模式时,Kube-Proxy将Service到Pod的NAT规则插入IPtables。这样,流量在将目标IP从Service IP转换为Pod IP后被重定向到相应的后端Pods。
现在Kube-Proxy的角色可以更多地被描述为规则的“安装者”。
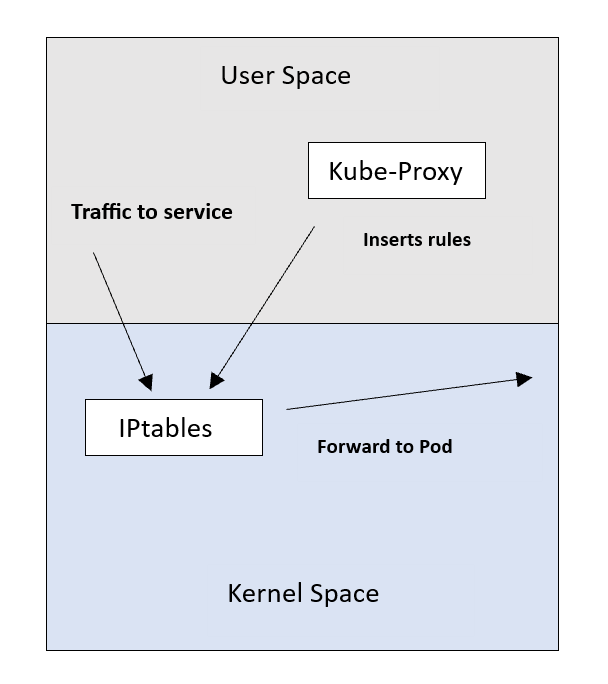

该模式下 iptables 做用户态的入口,kube-proxy 只是持续监听 Service 以及 Endpoints 对象的变化, iptables 通过设置的转发策略,直接将对 VIP 的请求转发给后端 Pod,iptables 使用 DNAT 来完成转发,其采用了随机数实现负载均衡。
如果 kube-proxy 在 iptables 模式下运行,并且所选的第一个 Pod 没有响应,则连接失败。 这与用户空间模式不同:在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接已失败, 并会自动使用其他后端 Pod 重试。
缺点
该模式相比 userspace 模式,克服了请求在用户态-内核态反复传递的问题,性能有所提升,但使用 iptables NAT 来完成转发,存在不可忽视的性能损耗,iptables 模式最主要问题是在 service 数量大的时候会产生太多的 iptables 规则,使用非增量式更新会引入一定时延,大规模情况下有明显性能问题。
IPtables使用顺序遍历其表。因为它最初是设计为一个数据包过滤组件。这种顺序算法在规则增加时不适用。在我们的场景中,这将是Service和端点的数量。将这一点低级别地看,该算法将按O(n)性能进行。这意味着查询次数的增加是线性增加。
此外,IPtables不支持特定的负载平衡算法。它使用一个随机等成本的分发方式,正如我们在第一个例子中提到的。
4.2 IPVS模式
专门设计用于负载平衡的Linux功能,成为Kube-Proxy使用的理想选择。在这种模式下,Kube-Proxy将规则插入到IPVS而非IPtables。
IPVS具有优化的查找算法(哈希),复杂度为O(1)。这意味着无论插入多少规则,它几乎都提供一致的性能。
在我们的情况下,这意味着对于Services和端点的更有效的连接处理。
IPVS还支持不同LB算法,如轮询,最小连接和其他哈希方法。
尽管它有优势,但是IPVS可能不在所有Linux系统中都存在。与几乎每个Linux操作系统都有的IPtables相比,IPVS可能不是所有Linux系统的核心功能。如果你的Services数量不太多,IPtables应该完美工作。
4.3 KernelSpace模式
此模式特定于Windows节点。在此模式中,Kube-proxy使用Windows的 Virtual Filtering Platform (VFP) 来插入数据包过滤规则。Windows上的 VFP 与Linux上的IPtables的工作方式相同,这意味着这些规则也将负责重写数据包封装并将目标IP地址替换为后端Pod的IP。
可将 VFP 想象成最初用于虚拟机网络的Hyper-V交换机的扩展。
5 如何检查Kube-Proxy模式
默认,Kube-Proxy在端口10249上运行,并暴露一组端点,你可以使用这些端点查询Kube-Proxy的信息。
你可以使用 /proxyMode 端点检查kube-proxy的模式。
首先通过SSH连接到集群中的一个节点。然后使用命令 curl -v localhost:10249/proxyMode。
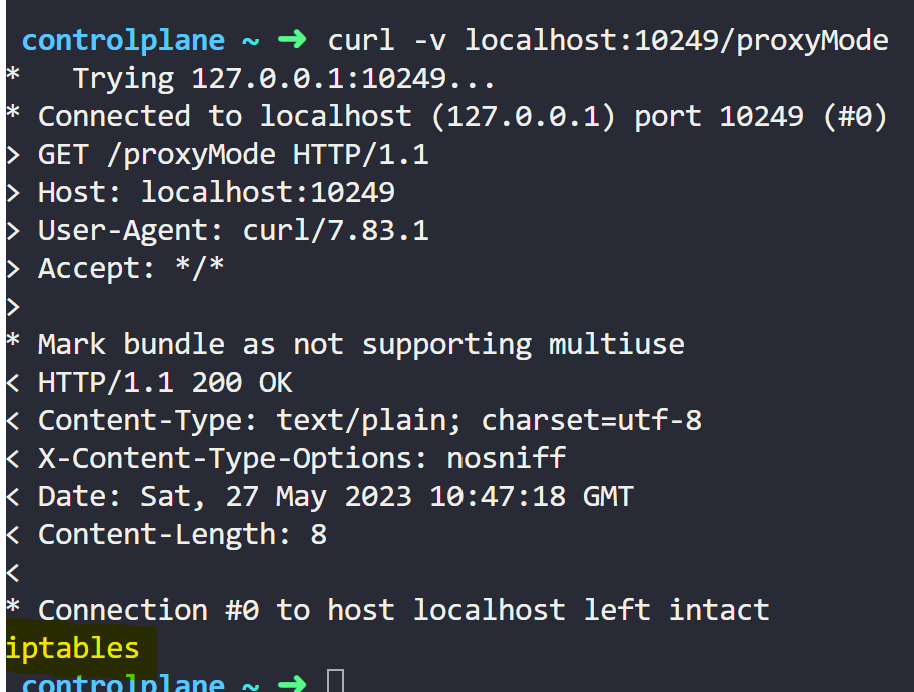
可看到Kube-Proxy正在使用iptables模式。
6 检查ClusterIP服务的IPtables规则
创建一个ClusterIP服务并检查创建的规则。
先决条件:
- 一个工作的Kubernetes集群(单节点或多节点)
- 安装了Kubectl以连接到集群并创建所需的资源
- 在我们将检查规则的节点上启用了SSH
步骤
先创建一个具有2个副本的redis部署。

现在让我们检查已创建的Pods。
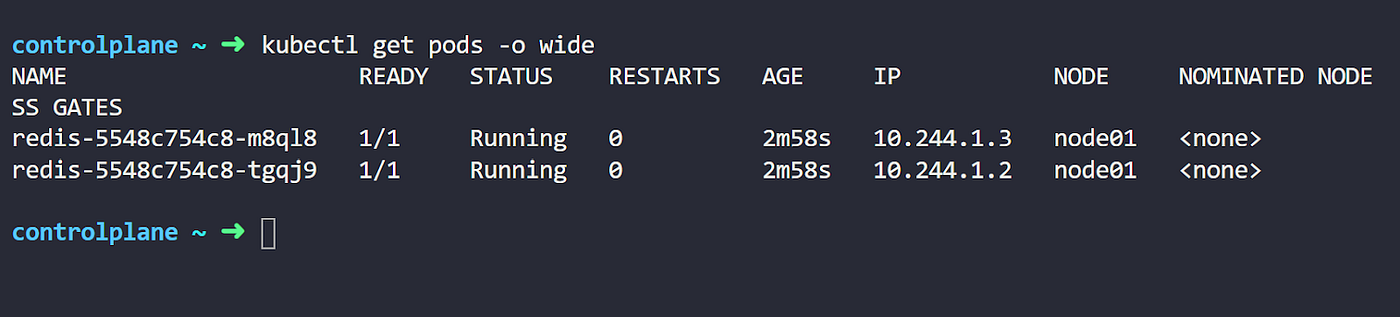
你可以看到我们有2个正在运行的Pods以及它们的IP地址。
创建一个与这些Pods关联的Service。为此,我们使用具有匹配Pods标签的选择器创建Service。
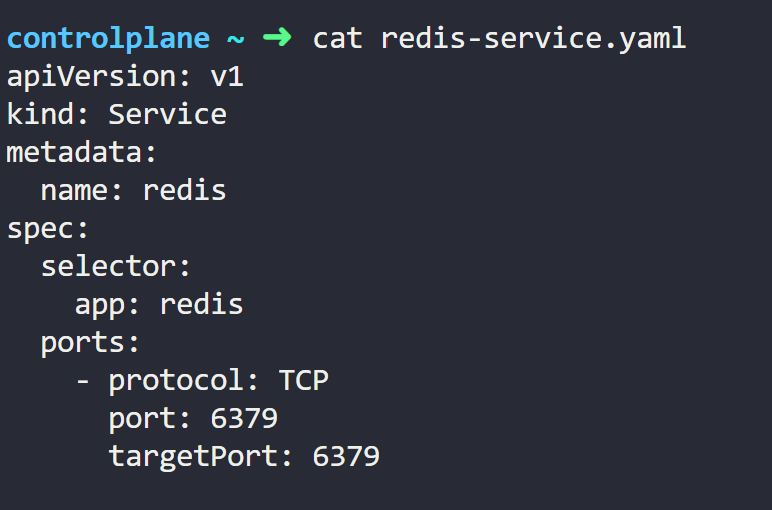
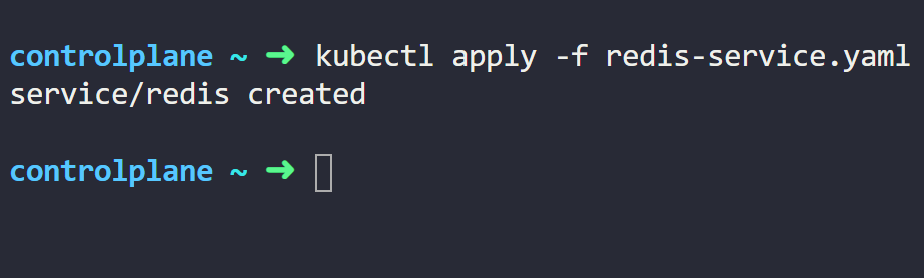
列出可用的服务,我们可以看到我们的 Redis 服务及其 IP 地址。
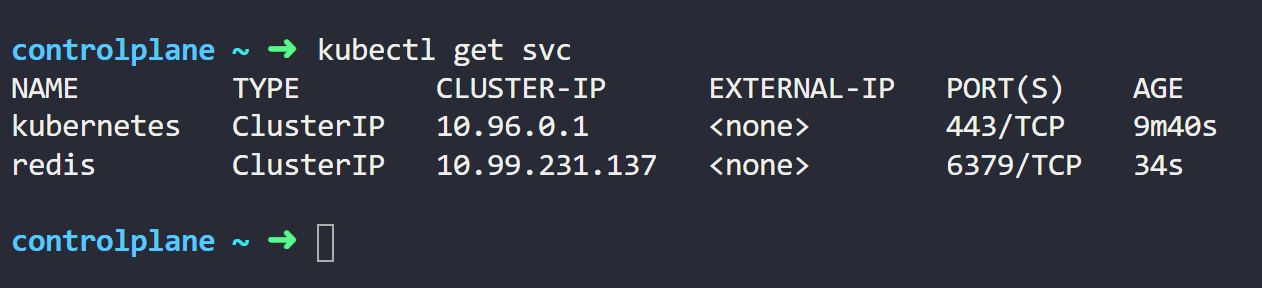
请注意,在 YAML 清单中,我们没有指定服务类型。这是因为默认类型是 ClusterIP。
- 现在,如果我们列出端点,我们会发现我们的服务有两个与我们的 Pod 相对应的端点。
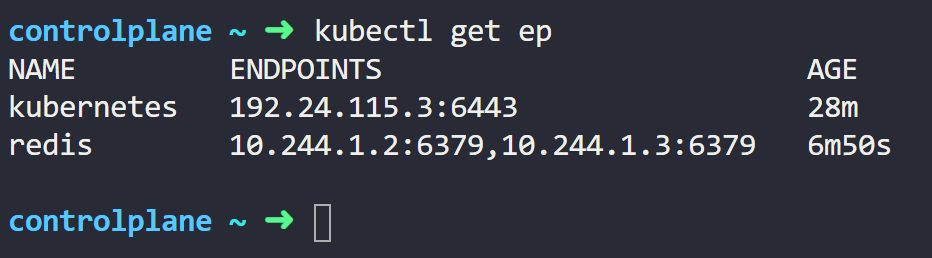
您会注意到这两个端点代表 Pod 的 IP 地址。
到目前为止,所有这些配置都相当直观。现在让我们深入探讨一下引擎下的魔术。
- 我们将列出其中一个节点上的 IPtables 规则。请注意,您首先需要 SSH 登录到节点才能运行以下命令。
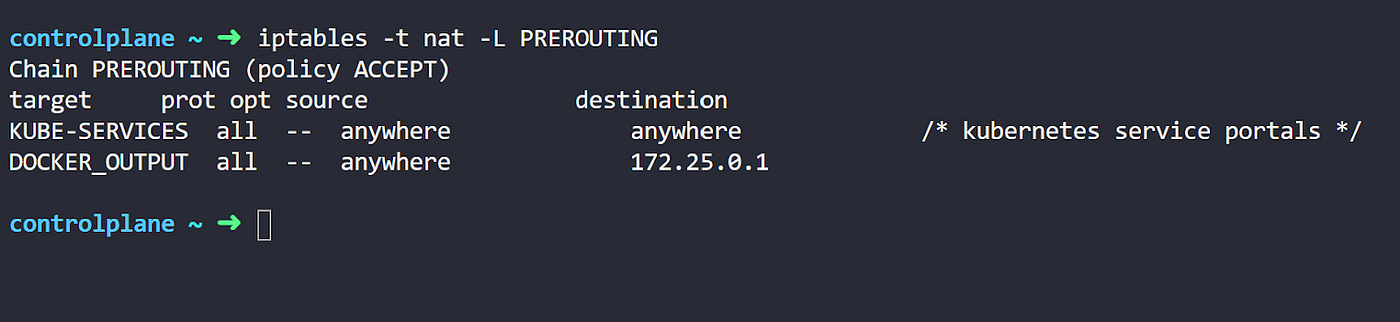
当然,我们不会在这里深入研究 IPtables 的所有细节。我们将尽量只突出我们场景中的重要信息。
首先让我们解释一下我们的命令选项。“-t nat” 是我们要列出的表的类型。IPtables 包含多个表类型,对于 Kube-Proxy,它使用 NAT 表。这是因为 Kube-Proxy 主要使用 IPtables 来翻译服务 IP。
还记得我们提到的链概念吗?这里的 “-L PREROUTING” 指的是表中链的名称。这是 IPtables 中默认存在的一个链。Kube-Proxy 将其规则挂接到该链中。
简而言之,在这里,我们要列出 PREROUTING 链中的 nat 规则。
现在让我们移动到命令输出。输出中最重要的部分是 KUBE-SERVICES 行。这是由 Kube-Proxy 为服务创建的自定义链。您会注意到该规则将任何源和任何目标的流量转发到此链中。
换句话说,通过 PREROUTING 链传递的数据包将被定向到 KUBE-SERVICES 链。
那么让我们查看这个 KUBE-SERVICES 中的内容。
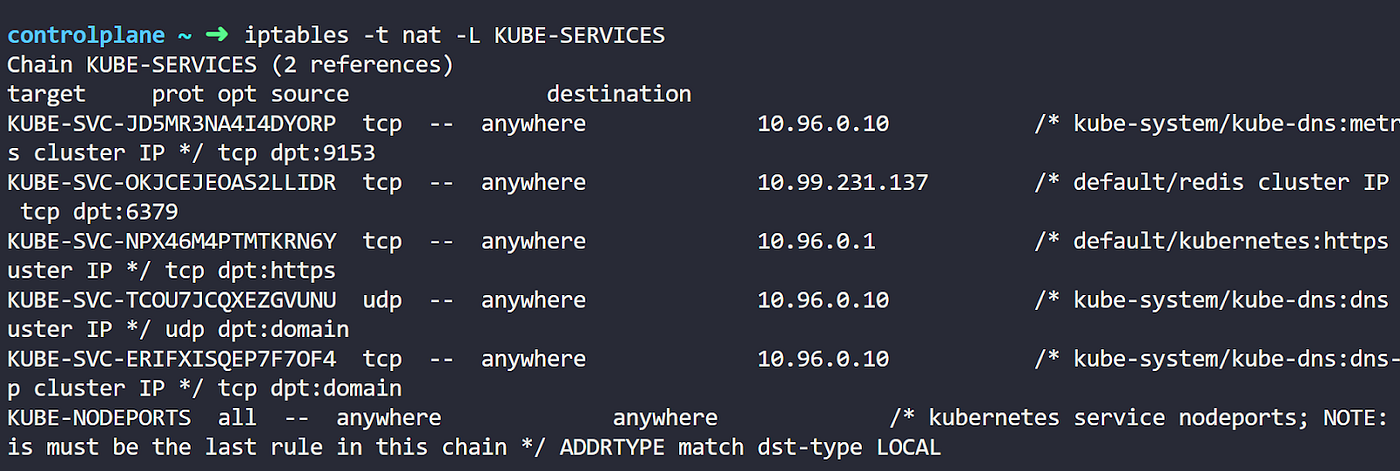
现在这里的加密是什么意思呢?嗯,简单地说,这些是另外一些链。
对我们来说,这里重要的是 IP 地址。您会注意到创建了一个特定链,其目标 IP 是服务的 IP(10.99.231.137)。这意味着流向服务的流量将进入该链。
您还可以在 IP 地址右侧看到一些信息。这些表示服务名称、服务类型和端口。
所有这些都确保我们正在查看 IPtables 的正确部分。现在让我们进入这个链。
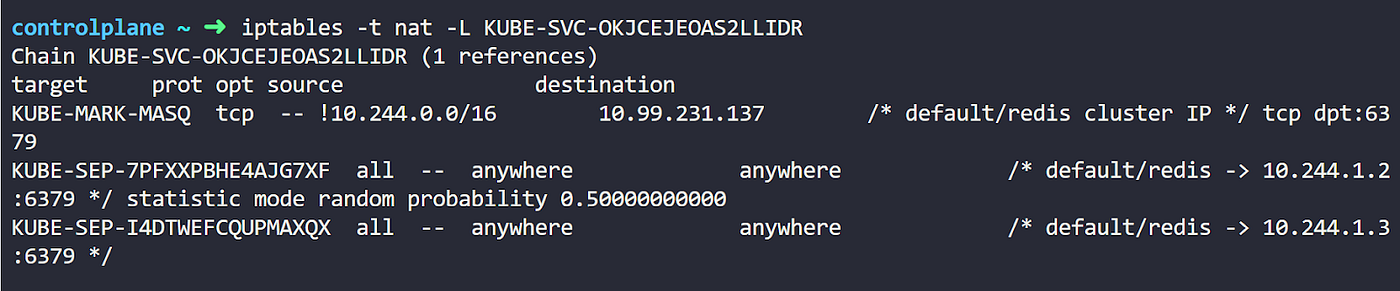
最后,我们到达了我们的 NAT 规则。您会发现创建了两个额外的链。每个都以 KUBE-SEP 开头,然后是一个随机的 ID。这对应于服务端点(SEP)。您可以看到每个链中列出的每个 Pod 的 IP 地址。
在中间看到这一行 statistic mode random probability 吗?这是 IPtables 在 Pod 之间进行的随机负载平衡规则。
进入这些 KUBE-SEP 链中的任何一个,我们可以看到它基本上是一个 DNAT 规则。

这就是服务的 IPtables 规则。由于现在您知道如何深入挖掘,您可以开始在您的环境中探索更多这些规则
7 FAQ
Kubernetes 服务是代理吗?
是的,Kubernetes 服务很像代理。
它提供一个稳定的 IP,客户端可以连接到该 IP。接收到该 IP 上的流量会被重定向到后端 Pod 的 IP。这克服了每次重新创建 Pod 时 Pod IP 更改的问题。
Kube-Proxy 能执行LB吗?
这取决于 Kube-Proxy 的哪个部分:
- Kube-Proxy 代理本身,答案是否定。Kube-Proxy 代理不接收实际流量,也不执行任何负载平衡。此代理仅是创建服务规则的控制平面的一部分
- Kube-Proxy 创建的规则,肯定的。Kube-Proxy 创建用于在多个 Pod 之间进行流量负载平衡的服务规则。这些 Pod 是彼此的副本,并与特定服务相关联
8 结论
Kube-Proxy 是一个 Kubernetes 代理,将服务定义转换为网络规则。它在集群中的每个节点上运行,并与 API 服务器通信以接收更新。然后,这些更新由节点内的 Kube-Proxy 填充。
通过创建这些规则,Kube-Proxy 允许发送到服务的流量被转发到正确的
Pod。这实现了 Pod IP 与连接到它的客户端的解耦。
作者简介:魔都国企技术专家兼架构,多家大厂后台研发和架构经验,负责复杂度极高业务系统的模块化、服务化、平台化研发工作。具有丰富带团队经验,深厚人才识别和培养的积累。
参考:
- 编程严选网
本文由博客一文多发平台 OpenWrite 发布!
这篇关于Kubernetes核心组件之kube-proxy实现原理的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-23云原生周刊:利用 eBPF 增强 K8s
- 2024-12-20/kubernetes 1.32版本更新解读:新特性和变化一目了然
- 2024-12-19拒绝 Helm? 如何在 K8s 上部署 KRaft 模式 Kafka 集群?
- 2024-12-16云原生周刊:Kubernetes v1.32 正式发布
- 2024-12-13Kubernetes上运行Minecraft:打造开发者平台的例子
- 2024-12-12深入 Kubernetes 的健康奥秘:探针(Probe)究竟有多强?
- 2024-12-10运维实战:K8s 上的 Doris 高可用集群最佳实践
- 2024-12-022024年最好用的十大Kubernetes工具
- 2024-12-02OPA守门人:Kubernetes集群策略编写指南
- 2024-11-26云原生周刊:K8s 严重漏洞



