TiDB 慢查询日志分析
2024/4/7 4:02:27

本文主要是介绍TiDB 慢查询日志分析,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
导读
TiDB 中的慢查询日志是一项 关键的性能监控工具,其主要作用在于协助数据库管理员追踪执行时间较长的 SQL 查询语句。 通过记录那些超过设定阈值的查询,慢查询日志为性能优化提供了关键的线索,有助于发现潜在的性能瓶颈,优化索引以及重构查询语句,从而提升数据库的整体性能。 本文将主要介绍 TiDB 中慢查询日志的功能,并探讨常用的慢查询日志分析方法 。
本文作者 :王勇,中金公司信息技术部高级架构师,负责中金公司盘古 PaaS 、中间件、数据库规划建设以及公司整体信息技术应用创新、开源治理工作,助力多个投行核心系统国产化落地。
慢查询相关参数
- tidb_enable_slow_log :用于控制是否开启 slow log 功能。
- tidb_slow_log_threshold :设置慢日志的阈值,执行时间超过阈值的 SQL 语句将被记录到慢日志中。默认值是 300 ms。
- tidb_query_log_max_len :设置慢日志记录 SQL 语句的最大长度。默认值是 4096 byte。
- tidb_redact_log :设置慢日志记录 SQL 时是否将用户数据脱敏用 ? 代替。默认值是 0 ,即关闭该功能。
- tidb_enable_collect_execution_info :设置是否记录执行计划中各个算子的物理执行信息,默认值是 1 。
慢查询日志原理
TiDB 的慢查询日志原理与 MySQL 一致,在每条 SQL 执行结束时,并且执行时间超过慢日志阈值时,会把 SQL 执行相关信息记录到慢日志中,同样的 SQL 多次执行超过阈值都会记录。
分析慢查询日志
由于 TiDB 是采用存算分离架构的分布式数据库,在这种架构下,每个 TiDB Server 节点都会产生慢日志。为方便查询慢日志,TiDB 提供了内存映射表 INFORMATION_SCHEMA.SLOW_QUERY ,并在 TiDB Dashboard 中提供专门的界面用于搜索和查看慢查询日志。官方文档中也提供了多种常见的慢查询日志查询语句,参考:慢查询日志 ( https://docs.pingcap.com/zh/tidb/v7.1/identify-slow-queries#查询-slow_querycluster_slow_query-示例 )。
然而,在系统高负载或异常情况下,短时间内生成过多慢 SQL 导致慢 SQL 变得难以分析,这也是像 MySQL 等数据库提供慢日志分析工具的原因,例如 mysqldumpslow 、 pt-query-digest 等工具。这些工具通常以某种聚合的方式输出结果,使结果更加清晰易懂。借鉴这些工具的思路,笔者开发了一条常用的慢日志分析 SQL,以更便捷地处理慢查询日志。
1 慢日志聚合查询 SQL
-- 慢查询日志,聚合查询 WITH ss AS (SELECT s.Digest ,s.Plan_digest, count(1) exec_count, sum(s.Succ) succ_count, round(sum(s.Query_time),4) sum_query_time, round(avg(s.Query_time),4) avg_query_time, sum(s.Total_keys) sum_total_keys, avg(s.Total_keys) avg_total_keys, sum(s.Process_keys) sum_process_keys, avg(s.Process_keys) avg_process_keys, min(s.`Time`) min_time, max(s.`Time`) max_time, round(max(s.Mem_max)/1024/1024,4) Mem_max, round(max(s.Disk_max)/1024/1024,4) Disk_max, avg(s.Result_rows) avg_Result_rows, max(s.Result_rows) max_Result_rows, sum(Plan_from_binding) Plan_from_binding FROM information_schema.cluster_slow_query s WHERE s.time>=adddate(now(),INTERVAL -1 DAY) AND s.time<=now() AND s.Is_internal =0 -- AND UPPER(s.query) NOT LIKE '%ANALYZE TABLE%' -- AND UPPER(s.query) NOT LIKE '%DBEAVER%' -- AND UPPER(s.query) NOT LIKE '%ADD INDEX%' -- AND UPPER(s.query) NOT LIKE '%CREATE INDEX%' GROUP BY s.Digest ,s.Plan_digest ORDER BY sum(s.Query_time) desc LIMIT 35) SELECT ss.Digest, -- SQL Digest ss.Plan_digest, -- PLAN Digest (SELECT s1.Query FROM information_schema.cluster_slow_query s1 WHERE s1.Digest=ss.digest AND s1.time>=ss.min_time AND s1.time<=ss.max_time LIMIT 1) query, -- SQL文本 (SELECT s2.plan FROM information_schema.cluster_slow_query s2 WHERE s2.Plan_digest=ss.plan_digest AND s2.time>=ss.min_time AND s2.time<=ss.max_time LIMIT 1) plan, -- 执行计划 ss.exec_count, -- SQL总执行次数 ss.succ_count, -- SQL执行成功次数 ss.sum_query_time, -- 总执行时间(秒) ss.avg_query_time, -- 平均单次执行时间(秒) ss.sum_total_keys, -- 总扫描key数量 ss.avg_total_keys, -- 平均单次扫描key数量 ss.sum_process_keys, -- 总处理key数量 ss.avg_process_keys, -- 平均单次处理key数量 ss.min_time, -- 查询时间段内第一次SQL执行结束时间 ss.max_time, -- 查询时间段内最后一次SQL执行结束时间 ss.Mem_max, -- 单次执行中内存占用最大值(MB) ss.Disk_max, -- 单次执行中磁盘占用最大值(MB) ss.avg_Result_rows, -- 平均返回行数 ss.max_Result_rows, -- 单次最大返回行数 ss.Plan_from_binding -- 走SQL binding的次数 FROM ss;
这条 SQL 是笔者常用的一条慢查询分析语句,大家可以根据个人需要灵活地调整排序字段、查询字段和查询条件,以满足不同场景下的分析需求。
在这个 SQL 中,query 和 plan 字段是使用标量子查询的方式获取。经过测试,这种写法相比直接使用 group by,能够节省大量内存,所以能够分析更长时间段的慢查询。
既然是聚合查询,为什么不直接用 statements_summary_history 表呢?笔者觉得有三点原因,一是 statements_summary_history 由于本身是半小时的聚合数据,在应对短时间段的性能分析时可能不够精细。二是早期版本的 statements_summary_history 是纯内存表,可能由于 TiDB Server OOM 重启而导致数据丢失,而慢查询日志是存储在文件中的,因此 TiDB Server OOM 重启不会导致慢查询日志丢失。三是 statements_summary_history 有容量限制,记录的 SQL 可能被驱逐出去,而慢查询日志默认记录超过 300 毫秒的查询,已满足分析需求了。
2 单条 SQL 执行历史
SELECT date_format(adddate(s.Time,interval - s.Query_time second),'%Y-%m-%d %H') sql_exec_start, count(1) exec_cnt, sum(s.Succ) succ_cnt, count(distinct s.Plan_digest) plan_cnt, case when count(distinct s.Plan_digest)<5 then group_concat(distinct substr( s.Plan_digest,1,4)) else null end plan_digest, round(sum(s.Query_time),4) sum_q_time, round(avg(s.Query_time),4) avg_q_time, sum(s.Total_keys) sum_t_keys, round(avg(s.Total_keys),4) avg_t_keys, sum(s.Process_keys) sum_p_keys, avg(s.Process_keys) avg_p_keys, round(max(s.Mem_max/1024/1024),2) Mem_max_m, round(max(s.Disk_max/1024/1024),2) Disk_max_m, round(avg(s.Result_rows),4) avg_rows, max(s.Result_rows) max_rows, sum(Plan_from_binding) PFB from information_schema.cluster_slow_query s where s.digest='a0adeeb79b71315ac13a77f3f11162106b5ec7b48212cf17c20c754263ab9228' and time>=adddate(now(),interval -3 day) and time<=now() group by date_format(adddate(s.Time,interval - s.Query_time second),'%Y-%m-%d %H') order by 1 desc;
这条 SQL 是笔者常用的另一条慢查询分析语句,用于分析单个 SQL 的历史执行情况。通过这个查询,可以清晰地了解特定 SQL 在历次执行中的变化,包括执行计划、扫描数据量、执行时间等方面的情况。
收集慢查询日志脚本
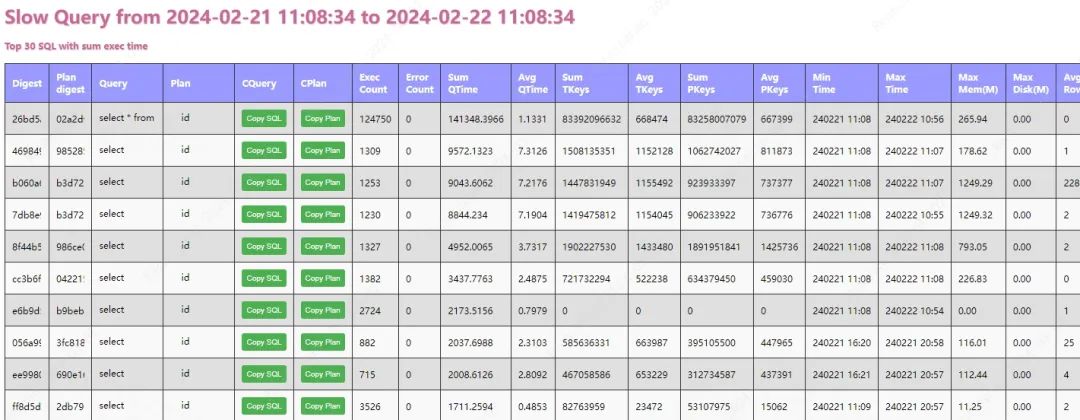
这个脚本用于生成 HTML 格式的慢日志分析结果,结合定时任务和 Nginx 的自动索引功能,可以轻松地收集和查看各个 TiDB 集群的慢日志。
脚本请在这个链接取: https://asktug.com/t/topic/1022684
效果展示:
总结
本文阐述了 TiDB 慢查询日志的相关配置和原理,并分享了笔者在实际工作中使用的慢查询日志分析 SQL。为读者提供了一种实际而有效的慢查询日志分析思路。
这篇关于TiDB 慢查询日志分析的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-11-15JavaMailSender是什么,怎么使用?-icode9专业技术文章分享
- 2024-11-15JWT 用户校验学习:从入门到实践
- 2024-11-15Nest学习:新手入门全面指南
- 2024-11-15RestfulAPI学习:新手入门指南
- 2024-11-15Server Component学习:入门教程与实践指南
- 2024-11-15动态路由入门:新手必读指南
- 2024-11-15JWT 用户校验入门:轻松掌握JWT认证基础
- 2024-11-15Nest后端开发入门指南
- 2024-11-15Nest后端开发入门教程
- 2024-11-15RestfulAPI入门:新手快速上手指南



