「布道师系列文章」解析 AutoMQ 对象存储中的文件存储格式
2024/5/8 21:02:59

本文主要是介绍「布道师系列文章」解析 AutoMQ 对象存储中的文件存储格式,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
作者|王金龙,知乎消息队列研发工程师,开源爱好者,长期关注云原生基础组件
01 背景
作为一款新一代消息中间件,AutoMQ 充分利用了云时代的存储基础设施,保证高性能的同时极大简化运维的繁琐程度。与基于物理机自建的 Kafka 集群相比,AutoMQ 的成本降低非常明显。这要归功于底层 s3stream 技术对 S3 对象存储的充分利用。接下来,让我们深入探讨一下 AutoMQ 在对象存储中的数据保存机制。
02 环境搭建
为了便于演示我们这里在 mac 环境下搭建一个基于 minio + AutoMQ 的演示环境。同时调整了相关参数便于更好的说明整体的消息内容。
1. 搭建 minio
brew install minio # 安装minio mkdir minio && minio server minio # 启动minio
Version: RELEASE.2024-04-06T05-26-02Z (go1.22.2 darwin/amd64) API: http://192.168.31.129:9000 http://198.18.0.1:9000 http://127.0.0.1:9000 RootUser: minioadmin RootPass: minioadmin WebUI: http://192.168.31.129:57026 http://198.18.0.1:57026 http://127.0.0.1:57026 RootUser: minioadmin RootPass: minioadmin
这里 webUI 可以登录到 minio 的控制台上便于操作,API 就是 minio 提供的 S3 API 接口,访问 S3 服务的 AK 和 SK 分别在命令行展示了。这里的 192.168.31.129 是我环境的本机 ip 地址。
我们需要登录到 webUI 上创建一个 bucket 用来保存数据,这里我们创建的 bucket 是 automq。
2. 对象存储检查 & 生成 AutoMQ 的启动命令
# 命令仅供演示 ./automq-kafka-admin.sh generate-s3-url --s3-access-key minioadmin --s3-secret-key minioadmin --s3-region ignore-here --s3-endpoint-protocol http --s3-endpoint http://192.168.31.129:9000 --s3-data-bucket automq --s3-ops-bucket automq --s3-path-style true
#################################### S3 PRECHECK ################################# [ OK ] Write s3 object [ OK ] Read s3 object [ OK ] Delete s3 object [ OK ] Write S3 object [ OK ] Upload s3 multipart object [ OK ] Read s3 multipart object [ OK ] Delete s3 object ########## S3 URL RESULT ############ Your S3 URL is: s3://192.168.31.129:9000?s3-access-key=minioadmin&s3-secret-key=minioadmin&s3-region=ignore-here&s3-endpoint-protocol=http&s3-data-bucket=automq&s3-path-style=true&s3-ops-bucket=automq&cluster-id=5kilSYquT962mUNQ8dL7qA ############ S3 URL USAGE ############## You can use s3url to generate start command to start AutoMQ ------------------------ COPY ME ------------------ bin/automq-kafka-admin.sh generate-start-command \ --s3-url="s3://192.168.31.129:9000?s3-access-key=minioadmin&s3-secret-key=minioadmin&s3-region=ignore-here&s3-endpoint-protocol=http&s3-data-bucket=automq&s3-path-style=true&s3-ops-bucket=automq&cluster-id=5kilSYquT962mUNQ8dL7qA" \ --controller-list="192.168.0.1:9093;192.168.0.2:9093;192.168.0.3:9093" \ --broker-list="192.168.0.4:9092;192.168.0.5:9092" TIPS: Replace the controller-list and broker-list with your real ip list.
这里我们调整一下启动命令,生成一个单节点的 kafka。
./automq-kafka-admin.sh generate-start-command \ --s3-url="s3://192.168.31.129:9000?s3-access-key=minioadmin&s3-secret-key=minioadmin&s3-region=ignore-here&s3-endpoint-protocol=http&s3-data-bucket=automq&s3-path-style=true&s3-ops-bucket=automq&cluster-id=5kilSYquT962mUNQ8dL7qA" \ --controller-list="192.168.31.129:9093" \ --broker-list="192.168.31.129:9092"
获得启动命令。
./kafka-server-start.sh --s3-url="s3://192.168.31.129:9000?s3-access-key=minioadmin&s3-secret-key=minioadmin&s3-region=ignore-here&s3-endpoint-protocol=http&s3-data-bucket=automq&s3-path-style=true&s3-ops-bucket=automq&cluster-id=5kilSYquT962mUNQ8dL7qA" --override process.roles=broker,controller --override node.id=0 --override controller.quorum.voters=0@192.168.31.129:9093 --override listeners=PLAINTEXT://192.168.31.129:9092,CONTROLLER://192.168.31.129:9093 --override advertised.listeners=PLAINTEXT://192.168.31.129:9092 \ --override s3.wal.upload.threshold=5242880 \ --override metadata.log.max.snapshot.interval.ms=60000 \ --override metadata.max.retention.ms=120000
为了演示方便我们调整一些参数。

3.创建 topic & 写入数据
# 创建topic ./kafka-topics.sh --create --topic automq-test --bootstrap-server 192.168.31.129:9092 # 写入数据,这里执行3次,每次写入5000条 ./kafka-producer-perf-test.sh --record-size=1024 --producer-props linger.ms=0 acks=-1 bootstrap.servers=main:9092 --num-records=50000 --throughput -1 --topic automq-test
这里写入成功,同时 kraft 生成了新的元数据快照完成后我们先停止 automq 节点。
这时可以从 minio 的 webUI 上看到数据已经写到我们之前创建的 bucket 上了。

至此准备工作完成。
03 元数据管理
可以看到对象存储里的数据名称和 topic 没有明显的映射关系,那么我们要如何从对象存储的数据中读取到实际的数据呢?
AutoMQ 使用了 Kafka 最新的基于 kraft 模式的元数据管理架构,该架构模式下用户无需运维一套新的 zookeeper 集群就可以完成整个 Kafka 集群的管理,同时该元数据架构的高性能为整个 Kafka 集群带来了更高的拓展性。AutoMQ 将对象存储中的数据和实际 topic 的映射保存在了 kraft 模式的元数据中,每次和对象存储的交互都会被元数据服务记录下来,这个映射信息会伴随着 Kafka Controller 和 Broker 之间的元数据复制流传递到每个 Broker 节点上。
我们这里使用 Kraft 元数据解析工具查看整体的映射关系。
Kraft 元数据会定期生成集群元数据的快照,可以在这个目录下 /tmp/kraft-combined-logs/__cluster_metadata-0 类似 000000000000000xxxxxx-00000000xxx.checkpoint 这样的文件就是 kraft 生成的快照。
# 打开快照文件 ./kafka-metadata-shell.sh -s /tmp/kraft-combined-logs/__cluster_metadata-0/000000000000000xxxxxx-00000000xxx.checkpoint
可以看到我们可以像操作 zookeeper 命令行一样获取整个集群的元数据信息。

在 topics 目录下我们能确定 automq-test 这个 topic 的 topicid 是 LeokTjQSRYOjo9Mx0AgopQ。
在 automq 目录下有 4 个子目录,分别是ꔷ kv:用来保存 kv 类型的元数据ꔷ nodes:用来保存 broker 信息 + broker 上保存的 StreamSetObjectꔷ objects:用来保存对象存储上的 object 的元数据信息ꔷ streams:用来保存 stream 流的元数据信息

这里的 kv 节点实际上记录的是这个 topic 对应的 MetaStream 的 streamId,也就是 3。
MetaStream 是什么?AutoMQ 会将一个 topic 中的元数据映射为 MetaStream,不同于保存数据 log 的 stream。MetaStream 会记录 topic 的数据 log 映射的元数据信息,leaderEpoch 的快照,producerSnapShot 的快照,以及整体 Topic 分区的数据范围的相关信息。
查看 streams/3 的内容,这里没有 streamobject,说明这个 stream 中的信息在 StreamSetObject 当中。

我们查看 nodes 节点里的 StreamSetObject 中的信息。
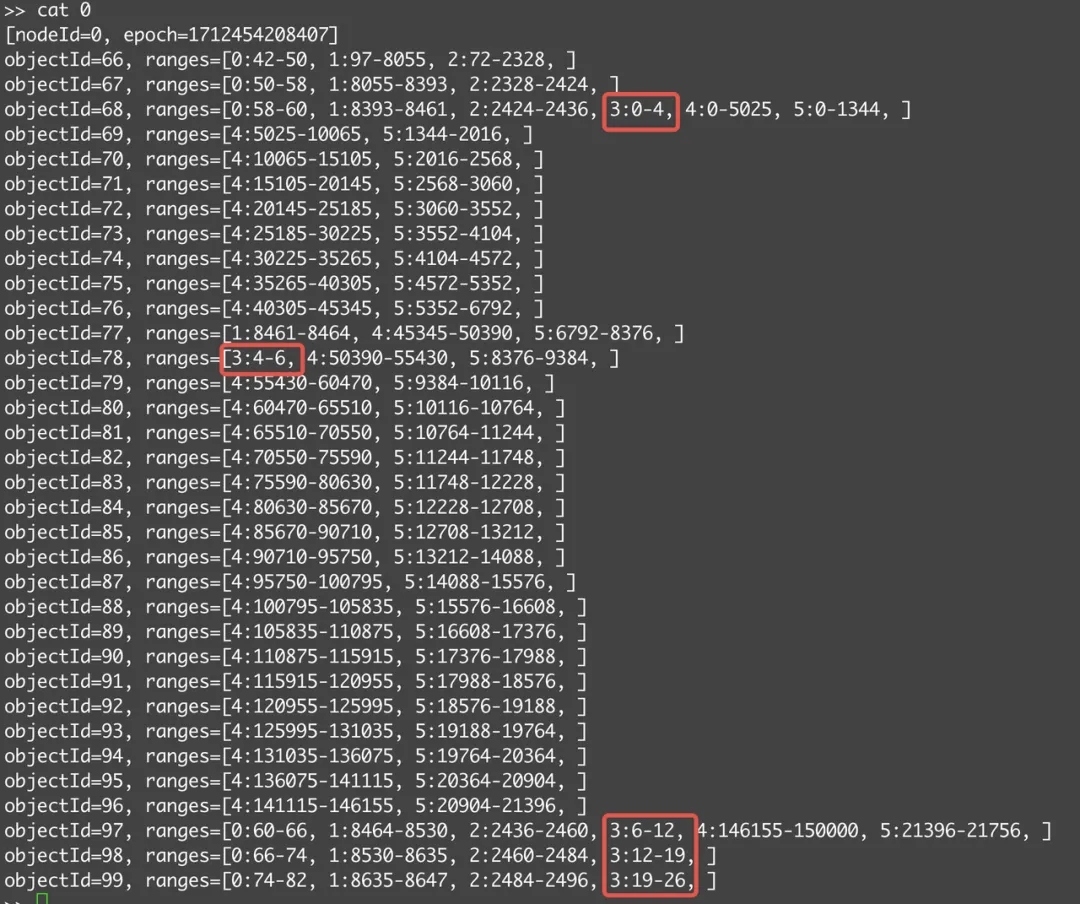
可以看到 object 68 和 78 这 2 个对象保存了 streamId=3 的这个流中的一部分数据。
AutoMQ 使用 objectId 进行对对象存储中的数据对象进行跟踪,上传时会根据 objectId 进行编码。这里 78 的对象对应的 S3 上的 key 是 e4000000/_kafka_HevPZiuuSiiyUU6ylL3C6Q/78,这是一个 5MB 的对象,同时里面包含了 3,4,5 这三个 stream 的部分数据。
04 对象存储中数据文件格式解析
1. 文件格式解析
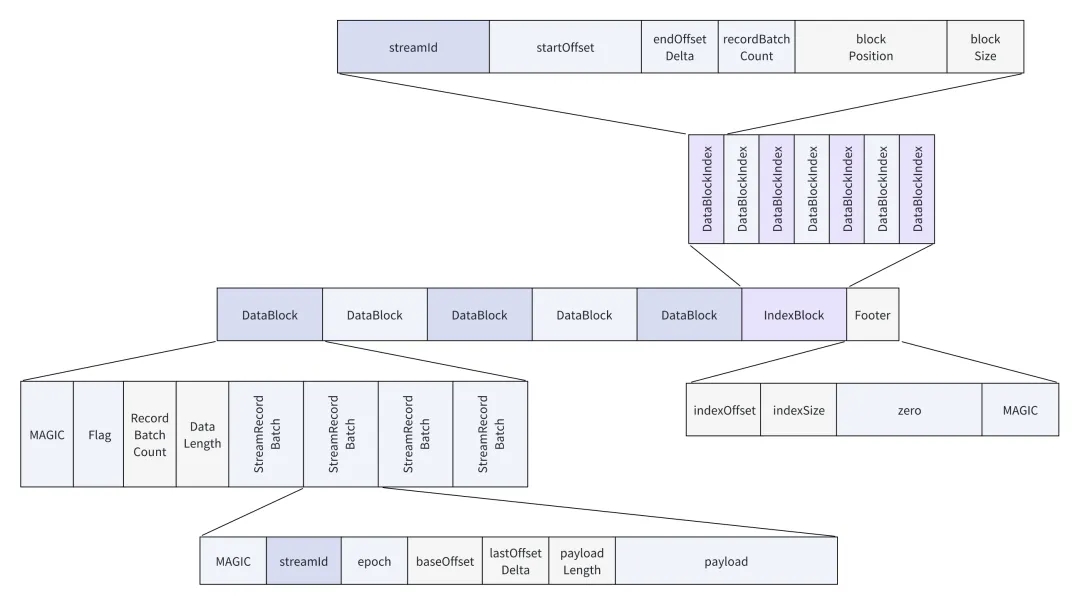
对象存储中的数据文件分为 DataBlock,IndexBlock,Footer 三个部分,分别保存实际的数据块,索引块,和文件元数据 Footer 信息。
其中文件元数据 Footer 为定长 48 字节的数据块,其中保存了索引块儿的数据位置和索引块的大小,我们可以通过这个信息快速定位到索引块的信息。
索引块 IndexBlock 为定长 36 字节的数据项集合的数据块,具体数据项的数目取决于整个文件中的 DataBlock 个数的多少。可以看到每个 DatablockIndex 中保存了( streamId, startOffset, endOffset ) 这个关于数据定位项的信息。通过每个 DataIndexBlock 中的 ( position, blockSize ) 的信息可以定位到文件的任意的 DataBlock。
数据块 DataBlock 用来保存实际写入的数据,如果 stream 是 datastream 的载体的话 StreamRecordbatch 对应每个 Kafka 写入的 RecordBatch。如果 stream 是 MetaStream 的话,则保存的是 Kafka topic 的相关元数据的 kv 对信息。
2. 文件上传时构建流程
每一个用户的写入数据会被封装为StreamRecordBatch,这个对象会序列化并保存到WAL当中。
详细流程可以阅读AutoMQ公众号:AutoMQ 如何基于裸设备实现高性能的 WAL 这篇文章了解相关原理
在数据写入到 wal 后,WAL 中的数据会同时在内存中缓存一份到 LogCache。
累积到一定数据后会触发上传对象存储的流程,上传数据时直接从 LogCache 获取 wal 中未上传到对象存储中的数据,减少对WAL的读取IO。
保存在 LogCache 中的 StreamRecordBatch 会按照( streamId, startOffset ) 来进行排序。这样这个上传数据的批次会将数据按照 ( stremId, startOffset ) 的顺序写入到同一个对象存储中的对象当中(这里假定每个 stream 中的累积数据不会超过阈值)。
数据块 DataBlock 编码完成全部写入完成后,会按照之前写入的信息构建 IndexBlock 块,DataBlock 已经确定了在对象中的位置,会根据这个信息生成每个 DataBlock 的 DataBlockIndex 信息,具体 DataBlockIndex 的数量根据前面写入的 DataBlock 数量决定。
这样整个对象的 IndexBlock 块的开始位置和块儿的长度就已经确定了,最后写入 Footer 文件元数据块记录 IndexBlock 的数据位置和块儿大小的相关信息,这样整个上传批次中的数据就完全保存到对象存储中的一个对象当中了。
3. 如何快速定位 DataBlock 的位置
通常读取数据的需求是快速定位到(steamId, offset)位置的数据。那么如何快速定位呢。
从 Footer 中可以获取 IndexBlock 块的位置,IndexBlock 块中的数据实际上是按照(streamId, startOffset) 排好序的,所以我们这里通过二分查找可以快速定位到实际的 DataBlock 中。
这样只要简单遍历 DataBlock 中全部的 StreamRecordBatch 对比实际的 offset 和 StreamRecordBatch 的 baseOffset 就可以快速定位所需的数据。
DataBlock 中的 StreamRecordBatch 数目比较多会影响实际在 DataBlock 中检索 offset 指定数据的时间,所以这里在上传对象的时候会将同一个 stream 中的所有数据按照 1MB 的大小进行拆分,这样每个 DataBlock 中保存的 StreamRecordBatch 不会因为过多导致影响检索指定 offset 数据的时间。
4. 合并上传到对象存储
每次触发 wal 数据上传时,实际是将多个 stream 中的数据上传到单个对象当中(不超过阈值的情况下)。
我们假定单个 Kafka Broker 负责的 topic 分区有 1000 个,其中元数据 MetaStream 和数据流分别占用一个 stream,则最大单个批次上传中的数据有 2000 个 stream,如果将这 2000 个 stream 均上传到单个对象当中,则相比上传到单个对象当中,对 S3 对象存储的 API 调用放大了 2000 倍,这样整体对象存储的 API 调用费用增加是非常惊人的。AutoMQ 通过高效的索引块以及合并上传到单个对象当中,极大减少了对象存储的 API 调用费用,同时保证了数据检索的高效。
05 元数据流 MetaStream 数据解析
这样我们知道如何解析对象存储中文件的格式了,让我们尝试解析一下 78 这个对象。
可以看到这个对象文件中的索引位置和大小,以及具体 DataBlock 的相关信息。
indexStartPosition: 5242006 indexBlockLength: 252 streamId=3, startOffset=4, endOffset=6, recordCount=2, startPosition=0, size=262 streamId=4, startOffset=50390, endOffset=51410, recordCount=68, startPosition=262, size=1060062 streamId=4, startOffset=51410, endOffset=52430, recordCount=68, startPosition=1060324, size=1060062 streamId=4, startOffset=52430, endOffset=53450, recordCount=68, startPosition=2120386, size=1060062 streamId=4, startOffset=53450, endOffset=54470, recordCount=68, startPosition=3180448, size=1060062 streamId=4, startOffset=54470, endOffset=55430, recordCount=64, startPosition=4240510, size=997706 streamId=5, startOffset=8376, endOffset=9384, recordCount=84, startPosition=5238216, size=3790
objectId=78, ranges=[3:4-6, 4:50390-55430, 5:8376-9384, ]
同时查看前文中的 StreamSetObject 的元数据,可以看到是吻合的,而且 streamId= 4 的数据被划分到了多个 DataBlock 当中。
MetaStream 实际是按照 Key Value 的方式记录到 s3Stream 存储层当中的。
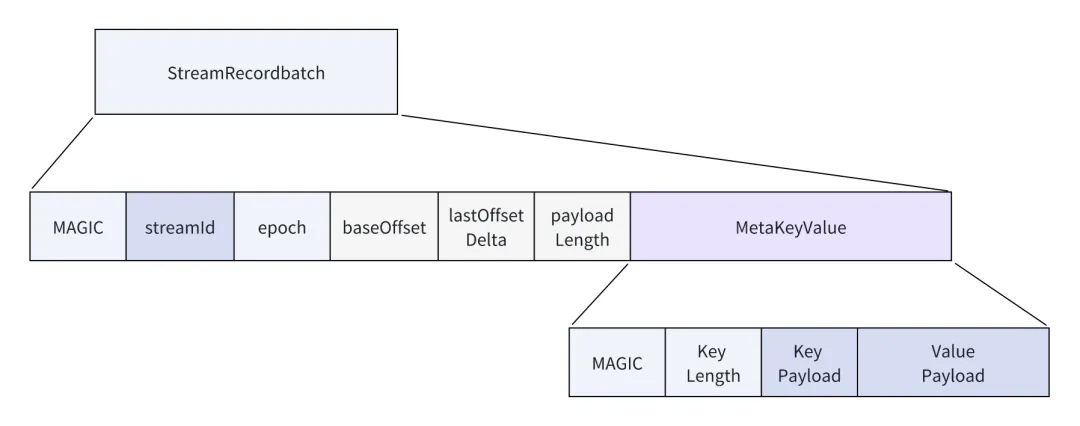
这里 Key Payload 是 java 中字符串的 utf-8 的编码,我们直接读取即可。
按照 IndexBlock 的索引读取 streamId=3 offset = [4,6)范围的数据。这里直接按照 AutoMQ 的定义进行了数据解析。
===========
StreamRecordBatch{streamId=3, epoch=0, baseOffset=4, count=1, size=138}
key=PRODUCER_SNAPSHOTS
offset=50555, content=[
ProducerStateEntry(producerId=7001, producerEpoch=0, currentTxnFirstOffset=OptionalLong.empty, coordinatorEpoch=-1, lastTimestamp=1712451139190, batchMetadata=[BatchMetadata(firstSeq=49935, lastSeq=49999, firstOffset=49935, lastOffset=49999, timestamp=1712451139190)]),
ProducerStateEntry(producerId=7002, producerEpoch=0, currentTxnFirstOffset=OptionalLong.empty, coordinatorEpoch=-1, lastTimestamp=1712451146293, batchMetadata=[BatchMetadata(firstSeq=480, lastSeq=554, firstOffset=50480, lastOffset=50554, timestamp=1712451146293)])
]
===========
StreamRecordBatch{streamId=3, epoch=0, baseOffset=5, count=1, size=48}
key=PARTITION, value={"s":0,"c":0,"r":50540,"cs":false}
可以看到 streamId=3 offset=4 保存的是 Kafka Producer 相关的快照信息,用于记录生产者幂等以及事务相关的元数据信息。offset=5 保存的是整个 Partition 的元数据信息,其中 startOffset ,cleanerOffset 均是 0,recoverOffset 是 50540。(对应 Kafka 中单个分区的数据维护相关概念)当前的快照并未停止 broker,所以获取到的是 cleanshutdwon 为 false 的状态,正常停机的话这个状态会是 true。
那么问题来了我们并没有数据流映射到的 stream 的 id 信息。猜测可能保存在 streamId=3, offset=[0,4) 这个区间。查看 StreamSetObject 的元数据可以发现这部分信息落在 68 这个对象当中。
直接解析这个对象。
===========
StreamRecordBatch{streamId=3, epoch=0, baseOffset=0, count=1, size=44}
key=PARTITION, value={"s":0,"c":0,"r":0,"cs":false}
===========
StreamRecordBatch{streamId=3, epoch=0, baseOffset=1, count=1, size=206}
key=LOG, value={"streamMap":{"log":4,"tim":5,"txn":-1},"segmentMetas":[{"bo":0,"ct":1712450996411,"lmt":0,"s":"","lsz":0,"ls":{"s":0,"e":-1},"ts":{"s":0,"e":-1},"txs":{"s":0,"e":-1},"fbt":0,"tle":{"t":-1,"o":0}}]}
===========
StreamRecordBatch{streamId=3, epoch=0, baseOffset=2, count=1, size=36}
key=LEADER_EPOCH_CHECKPOINT, value=ElasticLeaderEpochCheckpointMeta{version=0, entries=[]}
===========
StreamRecordBatch{streamId=3, epoch=0, baseOffset=3, count=1, size=48}
key=LEADER_EPOCH_CHECKPOINT, value=ElasticLeaderEpochCheckpointMeta{version=0, entries=[EpochEntry(epoch=0, startOffset=0)]}
我们可以看到从 Key 为 LOG 的对象当中记录了 streamMap 也就是数据流对应的相关 stream 信息。
{"streamMap":{"log":4,"tim":5,"txn":-1},"segmentMetas":[{"bo":0,"ct":1712450996411,"lmt":0,"s":"","lsz":0,"ls":{"s":0,"e":-1},"ts":{"s":0,"e":-1},"txs":{"s":0,"e":-1},"fbt":0,"tle":{"t":-1,"o":0}}]}
其中数据流对应的 stream 是 4。
到此我们就已经成功解析了整体 MetaStream 的元数据流中的信息。
06 数据流到 Kafka 消息的数据映射
根据之前的分析,我们只需要解析 stream 是 4 的数据文件并确定 Kafka 的数据是如何保存的即可。
这里我们知道一个 StreamRecordBatch 对应 Kafka 的一个 Recordbatch,那么获取到 DataBlock 之后我们尝试直接按照 Kafka 的数据格式解析。
获取对象 78,并尝试按照 Kafka V2 的数据格式进行解析。
===========
StreamRecordBatch{streamId=4, epoch=0, baseOffset=55400, count=15, size=15556}
checksum=4164202497, baseOffset=55400, maxTimestamp=1712451146370, timestampType=CREATE_TIME, baseOffset=55400, lastOffset=55414, nextOffset=55415, magic=2, producerId=7002, producerEpoch=0, baseSequence=5400, lastSequence=5414, compressionType=NONE, sizeInBytes=15556, partitionLeaderEpoch=0, isControlBatch=false, isTransactional=false
===========
StreamRecordBatch{streamId=4, epoch=0, baseOffset=55415, count=15, size=15556}
checksum=1825494209, baseOffset=55415, maxTimestamp=1712451146370, timestampType=CREATE_TIME, baseOffset=55415, lastOffset=55429, nextOffset=55430, magic=2, producerId=7002, producerEpoch=0, baseSequence=5415, lastSequence=5429, compressionType=NONE, sizeInBytes=15556, partitionLeaderEpoch=0, isControlBatch=false, isTransactional=false
可以看到数据解析成功!到此我们完成了整体的 AutoMQ 的数据格式的分析。
参考资料
[1] AutoMQ 参数配置文档:https://docs.automq.com/zh/docs/automq-s3kafka/ORGBwfdbNi28aIksMrCcMUCbn0g
[2] 原理剖析:AutoMQ 如何基于裸设备实现高性能的 WAL:https://mp.weixin.qq.com/s/rPBOFyVXbmauj-Yjy-rkbg
[3] Kafka RecordBatch 消息格式文档:https://kafka.apache.org/documentation/#recordbatch
关注 AutoMQ,探讨如何让 Kafka 利用云的弹性能力
4 月 20 日,AutoMQ 联合 StarRocks 和 KubeBlocks 将在北京举办《企业如何构建云原生现代化数据栈》Meetup。会议将探讨云原生现代化数据栈在不同场景下的实际应用案例。其中,京东 Kafka 云原生架构师钟厚会分享 AutoMQ 部署在 Kubernetes 上的经验,同时,AutoMQ 首席产品经理陈仲良为大家介绍 AutoMQ 的弹性能力和适用场景。

关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ
这篇关于「布道师系列文章」解析 AutoMQ 对象存储中的文件存储格式的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-21MQ-2烟雾传感器详解
- 2024-12-09Kafka消息丢失资料:新手入门指南
- 2024-12-07Kafka消息队列入门:轻松掌握Kafka消息队列
- 2024-12-07Kafka消息队列入门:轻松掌握消息队列基础知识
- 2024-12-07Kafka重复消费入门:轻松掌握Kafka消费的注意事项与实践
- 2024-12-07Kafka重复消费入门教程
- 2024-12-07RabbitMQ入门详解:新手必看的简单教程
- 2024-12-07RabbitMQ入门:新手必读教程
- 2024-12-06Kafka解耦学习入门教程
- 2024-12-06Kafka入门教程:快速上手指南



