使用 Prometheus 在 KubeSphere 上监控 KubeEdge 边缘节点(Jetson) CPU、GPU 状态
2024/5/8 21:03:07

本文主要是介绍使用 Prometheus 在 KubeSphere 上监控 KubeEdge 边缘节点(Jetson) CPU、GPU 状态,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
作者:朱亚光,之江实验室工程师,云原生/开源爱好者。
KubeSphere 边缘节点的可观测性
在边缘计算场景下,KubeSphere 基于 KubeEdge 实现应用与工作负载在云端与边缘节点的统一分发与管理,解决在海量边、端设备上完成应用交付、运维、管控的需求。
根据 KubeSphere 的支持矩阵,只有 1.23.x 版本的 K8s 支持边缘计算,而且 KubeSphere 界面也没有边缘节点资源使用率等监控信息的显示。

本文基于 KubeSphere 和 KubeEdge 构建云边一体化计算平台,通过 Prometheus 来监控 Nvidia Jetson 边缘设备状态,实现 KubeSphere 在边缘节点的可观测性。
| 组件 | 版本 |
|---|---|
| KubeSphere | 3.4.1 |
| containerd | 1.7.2 |
| K8s | 1.26.0 |
| KubeEdge | 1.15.1 |
| Jetson 型号 | NVIDIA Jetson Xavier NX (16GB ram) |
| Jtop | 4.2.7 |
| JetPack | 5.1.3-b29 |
| Docker | 24.0.5 |
部署 K8s 环境
参考 KubeSphere 部署文档。通过 KubeKey 可以快速部署一套 K8s 集群。
// all in one 方式部署一台 单 master 的 k8s 集群 ./kk create cluster --with-kubernetes v1.26.0 --with-kubesphere v3.4.1 --container-manager containerd
部署 KubeEdge 环境
参考 在 KubeSphere 上部署最新版的 KubeEdge,部署 KubeEdge。
开启边缘节点日志查询功能
-
vim /etc/kubeedge/config/edgecore.yaml
-
enable=true


开启后,可以方便查询 pod 日志,定位问题。
修改 KubeSphere 配置
开启 KubeEdge 边缘节点插件
- 修改 configmap–ClusterConfiguration

- advertiseAddress 设置为 cloudhub 所在的物理机地址

KubeSphere 开启边缘节点文档链接:https://www.kubesphere.io/zh/docs/v3.3/pluggable-components/kubeedge/。
修改完发现可以显示边缘节点,但是没有 CPU 和 内存信息,发现边缘节点没有 node-exporter 这个 pod。

修改 node-exporter 亲和性
kubectl get ds -n kubesphere-monitoring-system 发现不会部署到边缘节点上。
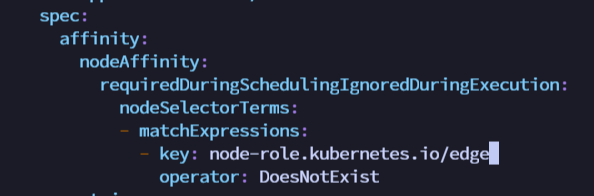
修改为:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role.kubernetes.io/edgetest -- 修改这里,让亲和性失效
operator: DoesNotExist
node-exporter 是部署在边缘节点上了,但是 pods 起不来。
通过kubectl edit 该失败的 pod,我们发现 node-exporter 这个pod 里面有两个容器,其中 kube-rbac-proxy 这个容器启动失败。看这个容器的日志,发现是 kube-rbac-proxy 想要获取 KUBERNETES_SERVICE_HOST 和 KUBERNETES_SERVICE_PORT 这两个环境变量,但是获取失败,所以容器启动失败。
在 K8s 的集群中,当创建 pod 时,会在 pod 中增加 KUBERNETES_SERVICE_HOST 和 KUBERNETES_SERVICE_PORT 这两个环境变量,用于 pod 内的进程对 kube-apiserver 的访问,但是在 KubeEdge 的 edge 节点上创建的 pod 中,这两个环境变量存在,但它是空的。
向 KubeEdge 的开发人员咨询,他们说会在 KubeEdge 1.17 版本上增加这两个环境变量的设置。参考如下:
https://github.com/wackxu/kubeedge/blob/4a7c00783de9b11e56e56968b2cc950a7d32a403/docs/proposals/edge-pod-list-watch-natively.md。
另一方面,推荐安装 EdgeMesh,安装之后在 edge 的 pod 上就可以访问 kubernetes.default.svc.cluster.local:443 了。
EdgeMesh 部署
-
配置 cloudcore configmap
kubectl edit cm cloudcore -n kubeedge设置 dynamicController=true.修改完 重启 cloudcore
kubectl delete pod cloudcore-776ffcbbb9-s6ff8 -n kubeedge -
配置 edgecore 模块,配置 metaServer=true 和 clusterDNS
$ vim /etc/kubeedge/config/edgecore.yaml modules: ... metaManager: metaServer: enable: true //配置这里 ... modules: ... edged: ... tailoredKubeletConfig: ... clusterDNS: //配置这里 - 169.254.96.16 ... //重启edgecore $ systemctl restart edgecore

修改完,验证是否修改成功。
$ curl 127.0.0.1:10550/api/v1/services
{"apiVersion":"v1","items":[{"apiVersion":"v1","kind":"Service","metadata":{"creationTimestamp":"2021-04-14T06:30:05Z","labels":{"component":"apiserver","provider":"kubernetes"},"name":"kubernetes","namespace":"default","resourceVersion":"147","selfLink":"default/services/kubernetes","uid":"55eeebea-08cf-4d1a-8b04-e85f8ae112a9"},"spec":{"clusterIP":"10.96.0.1","ports":[{"name":"https","port":443,"protocol":"TCP","targetPort":6443}],"sessionAffinity":"None","type":"ClusterIP"},"status":{"loadBalancer":{}}},{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{"prometheus.io/port":"9153","prometheus.io/scrape":"true"},"creationTimestamp":"2021-04-14T06:30:07Z","labels":{"k8s-app":"kube-dns","kubernetes.io/cluster-service":"true","kubernetes.io/name":"KubeDNS"},"name":"kube-dns","namespace":"kube-system","resourceVersion":"203","selfLink":"kube-system/services/kube-dns","uid":"c221ac20-cbfa-406b-812a-c44b9d82d6dc"},"spec":{"clusterIP":"10.96.0.10","ports":[{"name":"dns","port":53,"protocol":"UDP","targetPort":53},{"name":"dns-tcp","port":53,"protocol":"TCP","targetPort":53},{"name":"metrics","port":9153,"protocol":"TCP","targetPort":9153}],"selector":{"k8s-app":"kube-dns"},"sessionAffinity":"None","type":"ClusterIP"},"status":{"loadBalancer":{}}}],"kind":"ServiceList","metadata":{"resourceVersion":"377360","selfLink":"/api/v1/services"}}
-
安装 EdgeMesh
git clone https://github.com/kubeedge/edgemesh.git cd edgemesh kubectl apply -f build/crds/istio/ kubectl apply -f build/agent/resources/

dnsPolicy
EdgeMesh 部署完成后,edge 节点上的 node-exporter 中的两个境变量还是空的,也无法访问 kubernetes.default.svc.cluster.local:443,原因是该 pod 中 DNS 服务器配置错误,应该是 169.254.96.16 的,但是却是跟宿主机一样的 DNS 配置。
kubectl exec -it node-exporter-hcmfg -n kubesphere-monitoring-system -- sh Defaulted container "node-exporter" out of: node-exporter, kube-rbac-proxy $ cat /etc/resolv.conf nameserver 127.0.0.53
将 dnsPolicy 修改为 ClusterFirstWithHostNet,之后重启 node-exporter,DNS 的配置正确。
kubectl edit ds node-exporter -n kubesphere-monitoring-system
dnsPolicy: ClusterFirstWithHostNet hostNetwork: true
添加环境变量
vim /etc/systemd/system/edgecore.service
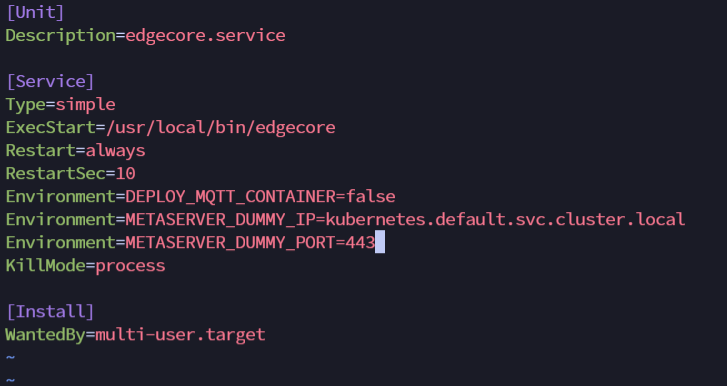
Environment=METASERVER_DUMMY_IP=kubernetes.default.svc.cluster.local Environment=METASERVER_DUMMY_PORT=443
修改完重启 edgecore。
systemctl daemon-reload systemctl restart edgecore
node-exporter 变成 running!!!
在边缘节点 curl http://127.0.0.1:9100/metrics 可以发现采集到了边缘节点的数据。
最后我们可以将 KubeSphere 的 K8s 服务通过 NodePort 暴露出来。就可以在页面查看。
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.39.1
name: prometheus-k8s-nodeport
namespace: kubesphere-monitoring-system
spec:
ports:
- port: 9090
targetPort: 9090
protocol: TCP
nodePort: 32143
selector:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 10800
type: NodePort
通过访问 master IP + 32143 端口,就可以访问边缘节点 node-exporter 数据。

然后界面上也出现了 CPU 和内存的信息。

搞定了 CPU 和内存,接下来就是 GPU 了。
监控 Jetson GPU 状态
安装 Jtop
首先 Jetson 是一个 ARM 设备,所以无法运行 nvidia-smi ,需要安装 Jtop。
sudo apt-get install python3-pip python3-dev -y sudo -H pip3 install jetson-stats sudo systemctl restart jtop.service
安装 Jetson GPU Exporter
参考博客,制作 Jetson GPU Exporter 镜像,并且对应的 Grafana 仪表盘都有。

Dockerfile
FROM python:3-buster RUN pip install --upgrade pip && pip install -U jetson-stats prometheus-client RUN mkdir -p /root COPY jetson_stats_prometheus_collector.py /root/jetson_stats_prometheus_collector.py WORKDIR /root USER root RUN chmod +x /root/jetson_stats_prometheus_collector.py ENTRYPOINT ["python3", "/root/jetson_stats_prometheus_collector.py"]
jetson_stats_prometheus_collector.py 代码
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import atexit
import os
from jtop import jtop, JtopException
from prometheus_client.core import InfoMetricFamily, GaugeMetricFamily, REGISTRY, CounterMetricFamily
from prometheus_client import make_wsgi_app
from wsgiref.simple_server import make_server
class CustomCollector(object):
def __init__(self):
atexit.register(self.cleanup)
self._jetson = jtop()
self._jetson.start()
def cleanup(self):
print("Closing jetson-stats connection...")
self._jetson.close()
def collect(self):
# spin传入true,表示不会等待下一次数据读取完成
if self._jetson.ok(spin=True):
#
# Board info
#
i = InfoMetricFamily('gpu_info_board', 'Board sys info', labels=['board_info'])
i.add_metric(['info'], {
'machine': self._jetson.board['info']['machine'] if 'machine' in self._jetson.board.get('info', {}) else self._jetson.board['hardware']['Module'],
'jetpack': self._jetson.board['info']['jetpack'] if 'jetpack' in self._jetson.board.get('info', {}) else self._jetson.board['hardware']['Jetpack'],
'l4t': self._jetson.board['info']['L4T'] if 'L4T' in self._jetson.board.get('info', {}) else self._jetson.board['hardware']['L4T']
})
yield i
i = InfoMetricFamily('gpu_info_hardware', 'Board hardware info', labels=['board_hw'])
i.add_metric(['hardware'], {
'codename': self._jetson.board['hardware'].get('Codename', self._jetson.board['hardware'].get('CODENAME', 'unknown')),
'soc': self._jetson.board['hardware'].get('SoC', self._jetson.board['hardware'].get('SOC', 'unknown')),
'module': self._jetson.board['hardware'].get('P-Number', self._jetson.board['hardware'].get('MODULE', 'unknown')),
'board': self._jetson.board['hardware'].get('699-level Part Number', self._jetson.board['hardware'].get('BOARD', 'unknown')),
'cuda_arch_bin': self._jetson.board['hardware'].get('CUDA Arch BIN', self._jetson.board['hardware'].get('CUDA_ARCH_BIN', 'unknown')),
'serial_number': self._jetson.board['hardware'].get('Serial Number', self._jetson.board['hardware'].get('SERIAL_NUMBER', 'unknown')),
})
yield i
#
# NV power mode
#
i = InfoMetricFamily('gpu_nvpmode', 'NV power mode', labels=['nvpmode'])
i.add_metric(['mode'], {'mode': self._jetson.nvpmodel.name})
yield i
#
# System uptime
#
g = GaugeMetricFamily('gpu_uptime', 'System uptime', labels=['uptime'])
days = self._jetson.uptime.days
seconds = self._jetson.uptime.seconds
hours = seconds//3600
minutes = (seconds//60) % 60
g.add_metric(['days'], days)
g.add_metric(['hours'], hours)
g.add_metric(['minutes'], minutes)
yield g
#
# CPU usage
#
g = GaugeMetricFamily('gpu_usage_cpu', 'CPU % schedutil', labels=['cpu'])
g.add_metric(['cpu_1'], self._jetson.stats['CPU1'] if ('CPU1' in self._jetson.stats and isinstance(self._jetson.stats['CPU1'], int)) else 0)
g.add_metric(['cpu_2'], self._jetson.stats['CPU2'] if ('CPU2' in self._jetson.stats and isinstance(self._jetson.stats['CPU2'], int)) else 0)
g.add_metric(['cpu_3'], self._jetson.stats['CPU3'] if ('CPU3' in self._jetson.stats and isinstance(self._jetson.stats['CPU3'], int)) else 0)
g.add_metric(['cpu_4'], self._jetson.stats['CPU4'] if ('CPU4' in self._jetson.stats and isinstance(self._jetson.stats['CPU4'], int)) else 0)
g.add_metric(['cpu_5'], self._jetson.stats['CPU5'] if ('CPU5' in self._jetson.stats and isinstance(self._jetson.stats['CPU5'], int)) else 0)
g.add_metric(['cpu_6'], self._jetson.stats['CPU6'] if ('CPU6' in self._jetson.stats and isinstance(self._jetson.stats['CPU6'], int)) else 0)
g.add_metric(['cpu_7'], self._jetson.stats['CPU7'] if ('CPU7' in self._jetson.stats and isinstance(self._jetson.stats['CPU7'], int)) else 0)
g.add_metric(['cpu_8'], self._jetson.stats['CPU8'] if ('CPU8' in self._jetson.stats and isinstance(self._jetson.stats['CPU8'], int)) else 0)
yield g
#
# GPU usage
#
g = GaugeMetricFamily('gpu_usage_gpu', 'GPU % schedutil', labels=['gpu'])
g.add_metric(['val'], self._jetson.stats['GPU'])
yield g
#
# Fan usage
#
g = GaugeMetricFamily('gpu_usage_fan', 'Fan usage', labels=['fan'])
g.add_metric(['speed'], self._jetson.fan.get('speed', self._jetson.fan.get('pwmfan', {'speed': [0] })['speed'][0]))
yield g
#
# Sensor temperatures
#
g = GaugeMetricFamily('gpu_temperatures', 'Sensor temperatures', labels=['temperature'])
keys = ['AO', 'GPU', 'Tdiode', 'AUX', 'CPU', 'thermal', 'Tboard']
for key in keys:
if key in self._jetson.temperature:
g.add_metric([key.lower()], self._jetson.temperature[key]['temp'] if isinstance(self._jetson.temperature[key], dict) else self._jetson.temperature.get(key, 0))
yield g
#
# Power
#
g = GaugeMetricFamily('gpu_usage_power', 'Power usage', labels=['power'])
if isinstance(self._jetson.power, dict):
g.add_metric(['cv'], self._jetson.power['rail']['VDD_CPU_CV']['avg'] if 'VDD_CPU_CV' in self._jetson.power['rail'] else self._jetson.power['rail'].get('CV', { 'avg': 0 }).get('avg'))
g.add_metric(['gpu'], self._jetson.power['rail']['VDD_GPU_SOC']['avg'] if 'VDD_GPU_SOC' in self._jetson.power['rail'] else self._jetson.power['rail'].get('GPU', { 'avg': 0 }).get('avg'))
g.add_metric(['sys5v'], self._jetson.power['rail']['VIN_SYS_5V0']['avg'] if 'VIN_SYS_5V0' in self._jetson.power['rail'] else self._jetson.power['rail'].get('SYS5V', { 'avg': 0 }).get('avg'))
if isinstance(self._jetson.power, tuple):
g.add_metric(['cv'], self._jetson.power[1]['CV']['cur'] if 'CV' in self._jetson.power[1] else 0)
g.add_metric(['gpu'], self._jetson.power[1]['GPU']['cur'] if 'GPU' in self._jetson.power[1] else 0)
g.add_metric(['sys5v'], self._jetson.power[1]['SYS5V']['cur'] if 'SYS5V' in self._jetson.power[1] else 0)
yield g
#
# Processes
#
try:
processes = self._jetson.processes
# key exists in dict
i = InfoMetricFamily('gpu_processes', 'Process usage', labels=['process'])
for index in range(len(processes)):
i.add_metric(['info'], {
'pid': str(processes[index][0]),
'user': processes[index][1],
'gpu': processes[index][2],
'type': processes[index][3],
'priority': str(processes[index][4]),
'state': processes[index][5],
'cpu': str(processes[index][6]),
'memory': str(processes[index][7]),
'gpu_memory': str(processes[index][8]),
'name': processes[index][9],
})
yield i
except AttributeError:
# key doesn't exist in dict
i = 0
if __name__ == '__main__':
port = os.environ.get('PORT', 9998)
REGISTRY.register(CustomCollector())
app = make_wsgi_app()
httpd = make_server('', int(port), app)
print('Serving on port: ', port)
try:
httpd.serve_forever()
except KeyboardInterrupt:
print('Goodbye!')
记得给 Jetson 的板子打标签,确保 GPU 的 Exporter 在 Jetson 上执行。否则在其他 node 上执行会因为采集不到数据而报错.
kubectl label node edge-wpx machine.type=jetson
新建 KubeSphere 资源
新建 ServiceAccount、DaemonSet、Service、servicemonitor,目的是将 jetson-exporter 采集到的数据提供给 KubeSphere 的 Prometheus。
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: jetson-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.0.0
name: jetson-exporter
namespace: kubesphere-monitoring-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: jetson-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.0.0
name: jetson-exporter
namespace: kubesphere-monitoring-system
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: jetson-exporter
app.kubernetes.io/part-of: kube-prometheus
template:
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: jetson-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.0.0
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role.kubernetes.io/edge
operator: Exists
containers:
- image: jetson-status-exporter:v1
imagePullPolicy: IfNotPresent
name: jetson-exporter
resources:
limits:
cpu: "1"
memory: 500Mi
requests:
cpu: 102m
memory: 180Mi
ports:
- containerPort: 9998
hostPort: 9998
name: http
protocol: TCP
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /run/jtop.sock
name: jtop-sock
readOnly: true
dnsPolicy: ClusterFirstWithHostNet
hostNetwork: true
hostPID: true
nodeSelector:
kubernetes.io/os: linux
machine.type: jetson
restartPolicy: Always
schedulerName: default-scheduler
serviceAccount: jetson-exporter
terminationGracePeriodSeconds: 30
tolerations:
- operator: Exists
volumes:
- hostPath:
path: /run/jtop.sock
type: Socket
name: jtop-sock
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: jetson-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.0.0
name: jetson-exporter
namespace: kubesphere-monitoring-system
spec:
clusterIP: None
clusterIPs:
- None
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: http
port: 9998
protocol: TCP
targetPort: http
selector:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: jetson-exporter
app.kubernetes.io/part-of: kube-prometheus
sessionAffinity: None
type: ClusterIP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: jetson-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/vendor: kubesphere
app.kubernetes.io/version: 1.0.0
name: jetson-exporter
namespace: kubesphere-monitoring-system
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 1m
port: http
relabelings:
- action: replace
regex: (.*)
replacement: $1
sourceLabels:
- __meta_kubernetes_pod_node_name
targetLabel: instance
- action: labeldrop
regex: (service|endpoint|container)
scheme: http
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
selector:
matchLabels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: jetson-exporter
app.kubernetes.io/part-of: kube-prometheus
部署完成后,jetson-exporter pod running。

重启 Prometheus pod,重新加载配置后,可以在 Prometheus 界面看到新增加的 GPU exporter 的 target。
kubectl delete pod prometheus-k8s-0 -n kubesphere-monitoring-system

在 KubeSphere 前端,查看 GPU 监控数据
前端需要修改 KubeSphere 的 console 的代码,这里属于前端内容,这里就不详细说明了。
其次将 Prometheus 的 SVC 端口暴露出来,通过 nodeport 的方式将 Prometheus 的端口暴露出来,前端通过 http 接口来查询 GPU 的状态。
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.39.1
name: prometheus-k8s-nodeport
namespace: kubesphere-monitoring-system
spec:
ports:
- port: 9090
targetPort: 9090
protocol: TCP
nodePort: 32143
selector:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 10800
type: NodePort
http 接口
查询瞬时值: get http://masterip:32143/api/v1/query?query=gpu_info_board_info&time=1711431293.686 get http://masterip:32143/api/v1/query?query=gpu_info_hardware_info&time=1711431590.574 get http://masterip:32143/api/v1/query?query=gpu_usage_gpu&time=1711431590.574 其中query为查询字段名,time是查询的时间 查询某个时间段的采集值: get http://10.11.140.87:32143/api/v1/query_range?query=gpu_usage_gpu&start=1711428221.998&end=1711431821.998&step=14 其中query为查询字段名,start和end是起始结束时间,step是间隔时间
这样就成功在 KubeSphere,监控 KubeEdge 边缘节点 Jetson 的 GPU 状态了。

总结
基于 KubeEdge,我们在 KubeSphere 的前端界面上实现了边缘设备的可观测性,包括 GPU 信息的可观测性。
对于边缘节点 CPU、内存状态的监控,首先修改亲和性,让 KubeSphere 自带的 node-exporter 能够采集边缘节点监控数据,接下来利用 KubeEdge 的 EdgeMesh 将采集的数据提供给 KubeSphere 的 Prometheus。这样就实现了 CPU、内存信息的监控。
对于边缘节点 GPU 状态的监控,安装 jtop 获取 GPU 使用率、温度等数据,然后开发 Jetson GPU Exporter,将 jtop 获取的信息发送给 KubeSphere 的 Prometheus,通过修改 KubeSphere 前端 ks-console 的代码,在界面上通过 http 接口获取 Prometheus 数据,这样就实现了 GPU 使用率等信息监控。
本文由博客一文多发平台 OpenWrite 发布!
这篇关于使用 Prometheus 在 KubeSphere 上监控 KubeEdge 边缘节点(Jetson) CPU、GPU 状态的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-21Kubernetes生产环境问题排查指南:实战教程
- 2024-12-20使用Encore.ts构建和部署TypeScript微服务到Kubernetes集群
- 2024-12-20Kubernetes:从理念到1.0的历程
- 2024-12-18第28天:Kubernetes中的蓝绿部署讲解
- 2024-12-15从零到Kubernetes安全大师:简化集群安全防护
- 2024-12-15掌握Kubernetes节点调度:污点、容忍、节点选择器和节点亲和性
- 2024-12-14第五天:与容器互动
- 2024-12-11CKA(Kubernetes管理员认证)速查表
- 2024-12-08.NET Aspire应用部署到Azure和Kubernetes实战指南
- 2024-12-07云原生周报:K8s未来三大发展方向不容错过



