Sora从入门到入门-白话版1
2024/5/8 21:03:41

本文主要是介绍Sora从入门到入门-白话版1,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
第一件事:什么是Sora?
Sora 是一个 AI 模型,可以根据文本指令创建现实且富有想象力的场景。
翻译成人话:从文本创建视频的AI工具
官网:
首先,我先更正一个普遍的错误,我看很多人说,
Sora 是一个数据驱动的物理引擎
我只想说,这真是离谱他妈给你离谱开门-离谱到家了。
Sora 到目前为止还不是什么数据驱动的物理引擎
别把他想的太复杂,他就是一个文生视频的模型,完事。
第二个事儿:听说他很NB,为啥?牛13在哪?
很多人说这玩意是颠覆性的,你问他颠覆性在哪?
他说这玩意是颠覆性的。
你问他颠覆性在哪?
他说这玩意是颠覆性的。
……
我想说,颠覆你妹啊。
我还是说下他颠覆性在哪,另外他是咋工作的。
相对来说,比较权威的论文是这个:
这个论文往上一摆,瞬间B格提高两个档次,但是没什么球用。
我还是翻译翻译,翻译翻译,什么他妈的叫惊喜。
我的意思是,Sora他妈说的不对的话,那我也肯定是错的,但是他妈OpenAI说的是对的,那我说的大部分应该是OK的。不墨迹整起。
视频这玩意吧他不像图片,他是动的。我要这么聊天是不是容易没朋友?但是事实就是这样,而且还不是废话(虽然听起来像废话)。但是动起来就麻烦了,一下子复杂很多。
图片好整,无非就是画个图。但是动起来就麻烦在在哪呢?
我给大家举个例子,比如一个人站着,另外一个人从对面走过来,然后从他身边路过,我们就说一个小事儿:
这人的影子怎么跟着身体动,然后他跟站着不动的人的影子咋发生叠加,这就是个复杂的事儿。
那要是双人运动,那更复杂。(我真没开车,你懂的)。
那要是坤坤的运动,那就复杂了。
各种东西动起来,AI数量级也好各种物理知识也好,还有复杂度蹭蹭上涨。
那么问题来了,为啥Sora这么nb,处理的那么好。
显然不是因为它是Sora,而是因为它的模型架构和训练的技术厉害。

第三个事儿:Sora的是咋工作的
原版论文是这么说:
Turning visual data into patches
We take inspiration from large language models which acquire generalist capabilities by training on internet-scale data.13,14 The success of the LLM paradigm is enabled in part by the use of tokens that elegantly unify diverse modalities of text—code, math and various natural languages. In this work, we consider how generative models of visual data can inherit such benefits. Whereas LLMs have text tokens, Sora has visual patches. Patches have previously been shown to be an effective representation for models of visual data.15,16,17,18 We find that patches are a highly-scalable and effective representation for training generative models on diverse types of videos and images.
翻译成中文:
我们从大型语言模型中获得灵感,这些模型通过互联网规模数据的训练来获得通用能力。 13, 14 LLM 范例的成功部分是通过使用标记来实现的,这些标记优雅地统一了文本的不同模式——代码、数学和各种自然语言。在这项工作中,我们考虑视觉数据的生成模型如何继承这些好处。 LLMs 有文本标记,而 Sora 有视觉补丁。此前,补丁已被证明是视觉数据模型的有效表示。 15, 16, 17, 18 我们发现补丁是一种高度可扩展且有效的表示形式,用于在不同类型的视频和视频上训练生成模型图片。
咋说呢?

我给大家翻译翻译,先拿个一张挨千刀的图镇楼:
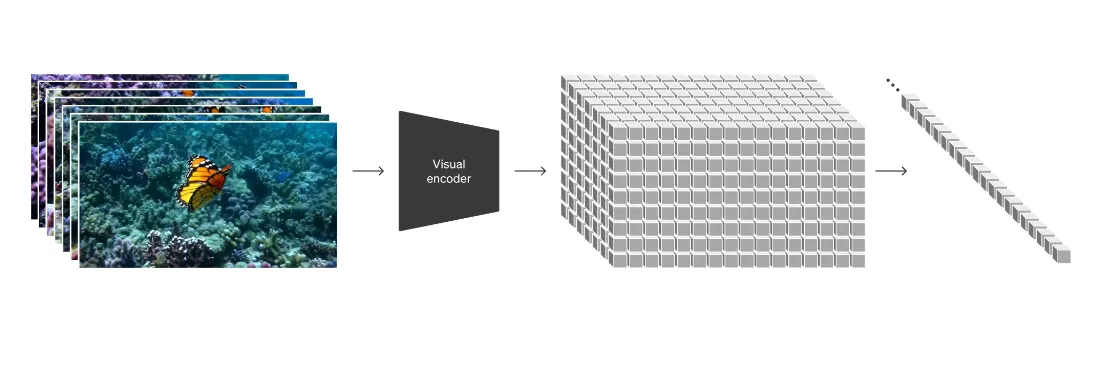
这里呢我说三件事,一件事叫模型架构,一件事叫文本调节,一件事 叫推理过程,
我举个例子,假如你Sora是个警察,你对人竖中指挨揍了。他翻看视频取证他怎么干呢?
首先他关键的地方 一段一段的看发生了什么?
他指着视频监控说,这里你伸手指头,那里他吐你口水了,后面他给你一巴掌,最后你捡砖头了。警官一帧一帧分析的过程就是他办案的思路,也就是我们说的模型架构。换一个警官可能就是你俩复原一下现场。
他说指着视频说你竖中指了,就是文本调节,把文本和视频对应上了。
是因为你竖中指,所以他拿搬砖呼你的,这就是推理过程。
通过调监控这个过程,他跟你都明白了,竖中指容易欠揍。这就是推理过程,这个过程你俩都学会了没事别瞎竖中指。这就是训练或者学习的过程。
当然了,下次有人报警,我挨揍了,警官就出现了你竖中指挨搬砖呼的画面。这也是推理,在脑海里脑补或者生成了,新的视频。
本身AI是不知道 竖中指 和 挨削 之间关联的,也不知道欠揍这个单词生成什么视频。但是看你挨削的监控视频多了,下次人家说我挨揍了,就把你给联系起来了。
上述就是Sora生成视频的过程。
但是这个又不是准确对应的关系,咋说呢。比如说有人报警了,当事人说,他特欠削,但是人家没有抡搬砖,你脑补这个就是无中生有了,添油加醋生成视频的过程了。

那么,到现在为止,大家都在狂吹Sora的优点和颠覆性,我说说它费劲的地方
第四件事:Sora 短板的地方,目前。
其实上面我也说了,
第一个是 它很难想象双人运动的画面。
第二个是 因为很难想象,所以训练成本和功能限制会很多。
为了装一下我的专业性,我喷一段:
Sora 不是通过游戏引擎或“数据驱动的物理引擎”来运行,而是通过变压器架构来运行,该架构以类似于 GPT-4 对文本标记的运行方式对视频“补丁”进行运行。它擅长创建视频,展示对深度、对象持久性和自然动态的理解,但是对复杂的交互进行建模以及在动态场景中保持一致性就废柴了。
最后一件事,Sora的未来:
当然我的推测,
两个方向,
第一个是强化语义理解,这个本来就是GPT和Transform的擅长。
第二点 引入其他模型的思维,甚至直接引入 物理和数学模型,补全短板。
你就说,它就不能引入生物模型来推断 受精卵发育成胚胎的过程吗?
那我说,也不是个办法,甚至再往前的过程也能推断出来。
总之Sora不能只是文科生,要文理兼修。
最最后一件事,跟我有啥关系:
1.谈资装13
2.Sora是快枪手,更新迭代很快,盯着点,很可能突然有一天直接你输入一段话就能生成不可描述的画面了。
我的意思是生成 电影了、广告了、甚至是你的短视频自媒体运营号的视频,还有一个非常非常重要的一点:
Sora+垂直行业 那真是金灿灿的。别乱想,
比如培训行业,我以后就不用讲课了,直接给它这篇文章,数字人的我就能白活出来,而且效果好,还成本低。
未来已来,最后一句:
不要飞机呼啸而过的时候惊呼飞机的速度和壮观。
我们应该成为那个在候机厅等待飞机或者在商务舱中享受旅行的人。
这篇关于Sora从入门到入门-白话版1的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-24酒店香薰厂家:创造独特客户体验
- 2024-12-22程序员出海做 AI 工具:如何用 similarweb 找到最佳流量渠道?
- 2024-12-20自建AI入门:生成模型介绍——GAN和VAE浅析
- 2024-12-20游戏引擎的进化史——从手工编码到超真实画面和人工智能
- 2024-12-20利用大型语言模型构建文本中的知识图谱:从文本到结构化数据的转换指南
- 2024-12-20揭秘百年人工智能:从深度学习到可解释AI
- 2024-12-20复杂RAG(检索增强生成)的入门介绍
- 2024-12-20基于大型语言模型的积木堆叠任务研究
- 2024-12-20从原型到生产:提升大型语言模型准确性的实战经验
- 2024-12-20啥是大模型1



