AutoMQ 对象存储数据高效组织的秘密: Compaction
2024/5/29 21:02:41

本文主要是介绍AutoMQ 对象存储数据高效组织的秘密: Compaction,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
01
前言
AutoMQ 作为一款使用对象存储作为主要存储介质的消息系统,在写入链路,会将所有 Partition 的数据在内存中进行攒批(同时持久化至 EBS),当攒批大小达到一定阈值则将该批次的数据上传至对象存储,通过这种方式,使得对象存储的 API 调用成本和文件数量仅和吞吐相关,且不会随着分区数量的增加而线性增大,如下图:
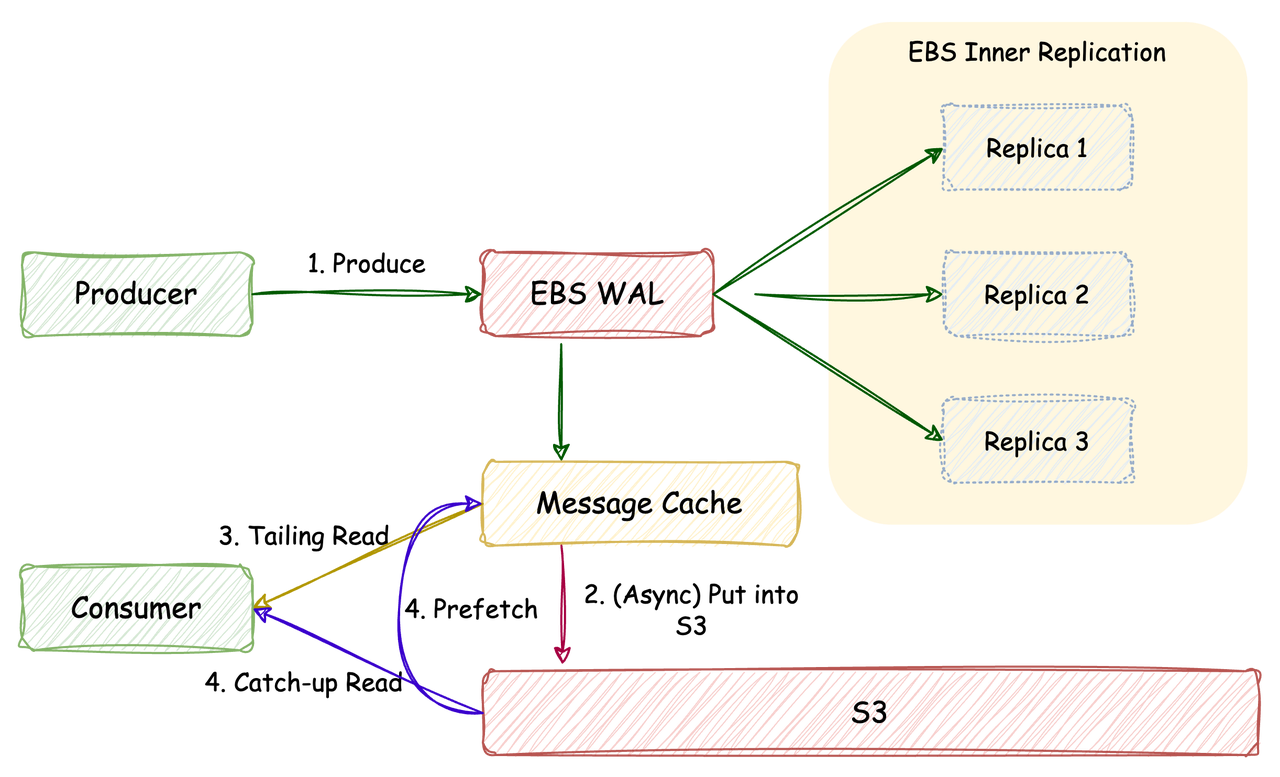
在将攒批数据上传至对象存储的过程中可能产生两类对象(从分区到 Stream 的映射关系可参考「AutoMQ 如何做到 Apache Kafka 100% 协议兼容」[3]),首次了解的读者可以简单理解为一个分区的数据对应着一个 Stream ):
-
Stream Set Object(下简称 SSO):同一个 Object 中包含多个 Stream 的连续数据段
-
Stream Object(下简称 SO):同一个 Object 中只包含一个 Stream 的连续数据段
上传时,会将积攒的数据中同一 Stream 连续数据段长度超过一定阈值的数据直接上传为一个 SO,剩余的多个分区的数据按照 Stream Id 从小到大的顺序写入同一个 SSO 中,如下图:

02
Compaction 的目的
与 LSM-Tree Compaction [4] 机制类似,AutoMQ 的 Compaction 主要用于数据清理、减少元数据量以及增大数据内聚程度以提高读取性能。
-
数据清理:通过 Compaction 来删除已经过期的分区数据
-
减少元数据量:通过将多个小对象 Compact 成大对象,能够有效减少所需维护的元数据量
-
提升读取性能:在 Apache Kafka 的文件结构下,消费一个分区的历史数据仅需要定位到该分区相应的 Segment 文件即可,但由于 AutoMQ 采用了攒批写入的方式,当分区数量较多时,一个 SSO 中可能只包含了一个分区的小部分数据,此时消费该分区的一段历史数据时,需要向多个 SSO 发起 API 调用,在调用成本增加的同时也容易影响冷读吞吐量。通过 Compaction,我们能将同一个分区的数据组织在尽可能少的对象上,从而提升消费性能。
03
Compaction 过程
AutoMQ 实现了两级 Compaction:
-
SSO Compaction:将多个 SSO Compact 成不超过一个 SSO 和多个 SO
-
SO Compaction:将属于同一 Stream 的多个 SO Compact 成更大的 SO
由于篇幅原因,本文将着重介绍 SSO Compaction。
3.1 准备工作
在 SSO Compaction 开始时,会先获取当前节点产生的所有 SSO,并读取各 SSO 的索引文件,解析出各个对象中的 Stream 和对应的数据范围,在这个过程中,各 Stream 过期的数据段将直接被忽略。本文将以下图所示的三个 SSO 的 Compaction 过程为例(需要注意的是,图上的色块长度仅用于表示对应数据段的长度,在这一步中,并未实际读取对应的数据段):

获取到各个 SSO 的索引后,按照 Stream Id 从小到大,同 Stream 数据偏移量从小到大的顺序对索引进行排序:

排序完成后,同一 Stream 的连续数据段大于分裂阈值的需要被分裂成单独的 SO,剩余的数据段将组成新的 SSO:

3.2 生成迭代计划
由于 Compaction 是周期性任务(默认周期为 20 分钟),对于一个大流量的线上集群而言,每次 Compaction 覆盖的 SSO 数据量可能达到上百 GB 甚至更多,想要将这些数据一次性拉取到本地进行 Compact 几乎是不可能实现的,故 AutoMQ 会根据预先配置的 Compaction 任务可使用的最大内存空间来将本次 Compaction 划分为多个迭代,每次迭代完成后,清理内存数据,再开始下一次迭代,从而实现在可控的内存空间下完成大规模数据的 Compaction。依然以上图为例,假设 Compaction 可用内存限制为 150,则本次 Compaction 将分为两个迭代完成:
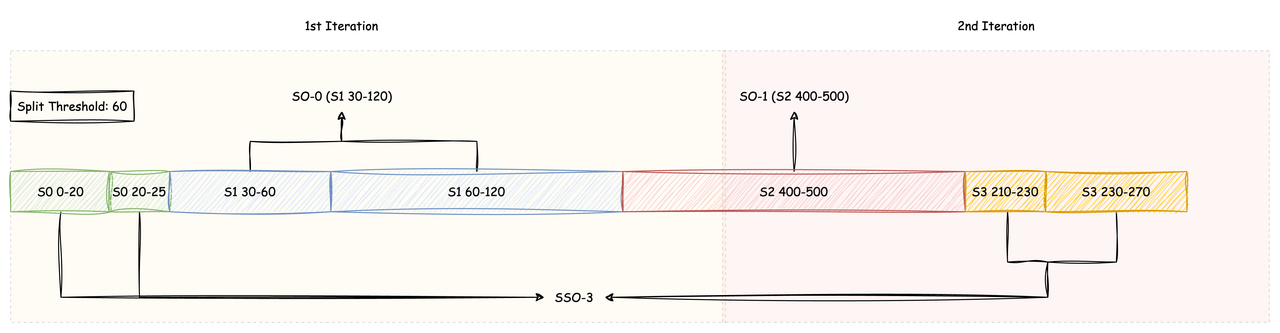
在第一轮迭代中,S0 的两个数据段将作为 SSO-3 的第一个 Part 被上传,S1 的前两个数据段(30-60、60-120)将被合并为一个对象(SO-0)被上传,而 S2 的数据段由于只能部分满足第一轮迭代的内存限制,将被截断成两个 SO,在第一轮迭代中将能够满足内存限制的前一部分(S2 400-435)上传。

在第二轮迭代中,此前被截断的 S2 剩余数据段(435-500)会被单独上传为一个 SO,S2 的剩余数据段会作为 SSO-3 的第二个 Part 被上传。

**3.3 发起读写 **
迭代计划制定完成后,就可以发起实际的读写请求了,为了最小化对象存储的 API 调用成本,在每轮迭代开始前会将本轮迭代需要读取的数据段按照所属的对象进行分组,由于 Compaction 的迭代顺序本身就是按照 Stream Id -> Offset 排序的,所以 SSO 中相邻的数据段可以被合并成一个 API 被读取,当一次迭代中的数据段被读取到本地完成拼装后即可触发上传。每次迭代中所需产生的对象都完成上传后,即可将此次迭代读取到内存中的数据段全部清除,从而为下一次迭代留出空间。以上文提到的两次迭代为例:
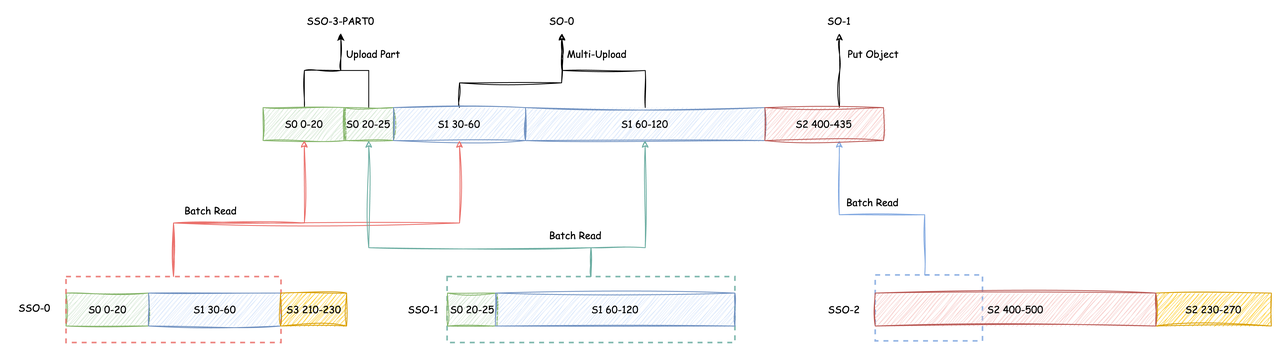
3.3.1 第一次迭代
1. 分别向三个 SSO 发起异步读取:
-
SSO-0 一次 Batch Read 读取 S0 (0-20) 以及 S1 (30-60) 两个数据段
-
SSO-1 一次 Batch Read 读取 S0 (20-25) 以及 S1 (60-120) 两个数据段
-
SSO-2 一次 Batch Read 读取 S2 (400-435) 数据段
- S0 (0-20) 和 S0 (20-25) 读取完成后作为 SSO-3 的第一个 Part 上传3. S1 (30-60) 和 S1 (60-120) 读取完成后通过 Multi-Part Upload 完成 SO-0 的上传4. S2 (400-435) 读取完成后通过 PutObject 完成 SO-1 的上传
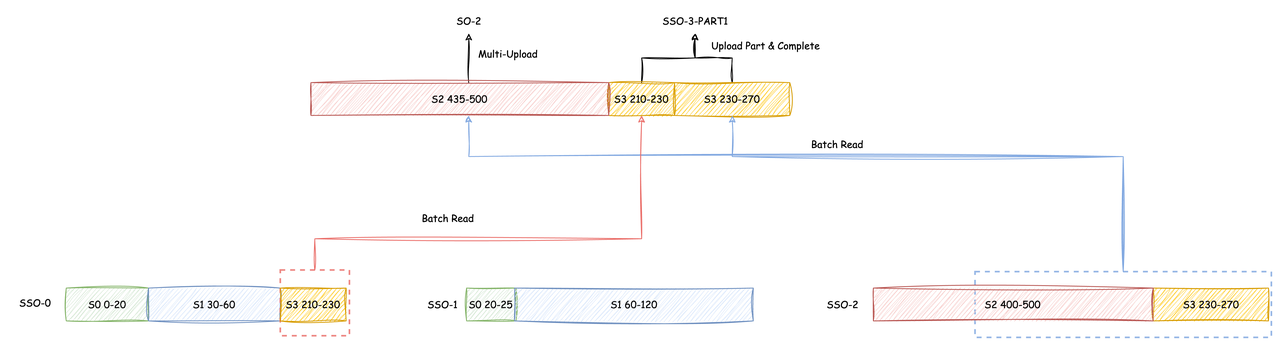
3.3.2 第二次迭代:
- 分别向两个 SSO 发起异步读取:
-
SSO-0 一次 Batch Read 读取 S3 (210-230) 数据段
-
SSO-2 一次 Batch Read 读取 S2 (435-500) 和 S3 (230-270) 两个数据段
- S2 (435-500) 读取完成后通过 Multi-Part Upload 完成 SO-2 的上传3. S3 (210-230) 和 S3 (230-270) 读取完成后作为 SSO-3 的最后一个 Part 上传
3.4 Commit 元数据
当所有的迭代都执行完成后,对象存储中已经生成了本次 Compaction 中产生的所有对象,此时 Broker 节点将向 Controller 发起一次 Commit 请求,将被 Compact 的对象标记为删除,并使用新生成的对象索引对元数据进行替换。若在 Compaction 过程中由于节点下线或其他异常导致了 Compaction 终止,则此次 Compaction 过程中生成的对象将在 Commit 超时时间过后被清理。
04
结语
本文介绍了 AutoMQ 如何在有限的内存下实现大规模 SSO 对象的 Compaction。除本文覆盖的内容外,AutoMQ 还实现了诸如 Force Split、Compaction 分级限流、基于 UploadPartCopy 的 SO Compaction 等一系列特性,受限于篇幅本文不一一展开介绍,感兴趣的同学欢迎深入 AutoMQ 代码仓库进行了解。
参考资料
[1] KIP-405: Kafka Tiered Storage: https://cwiki.apache.org/confluence/display/KAFKA/KIP-405%3A+Kafka+Tiered+Storage
[2] S3Stream: https://github.com/AutoMQ/automq/tree/main/s3stream
[3] AutoMQ 如何做到 Apache Kafka 100% 协议兼容: https://mp.weixin.qq.com/s/ZOTu5fA0FcAJlCrCJFSoaw
[4] Log-structured merge-tree: https://en.wikipedia.org/wiki/Log-structured_merge-tree
[5] AWS S3 UploadPartCopy https://docs.aws.amazon.com/AmazonS3/latest/API/API_UploadPartCopy.html
往期推荐
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ
这篇关于AutoMQ 对象存储数据高效组织的秘密: Compaction的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2025-01-05Easysearch 可搜索快照功能,看这篇就够了
- 2025-01-04BOT+EPC模式在基础设施项目中的应用与优势
- 2025-01-03用LangChain构建会检索和搜索的智能聊天机器人指南
- 2025-01-03图像文字理解,OCR、大模型还是多模态模型?PalliGema2在QLoRA技术上的微调与应用
- 2025-01-03混合搜索:用LanceDB实现语义和关键词结合的搜索技术(应用于实际项目)
- 2025-01-03停止思考数据管道,开始构建数据平台:介绍Analytics Engineering Framework
- 2025-01-03如果 Azure-Samples/aks-store-demo 使用了 Score 会怎样?
- 2025-01-03Apache Flink概述:实时数据处理的利器
- 2025-01-01使用 SVN合并操作时,怎么解决冲突的情况?-icode9专业技术文章分享
- 2025-01-01告别Anaconda?试试这些替代品吧



