AI 大模型企业应用实战(13)-Lostinthemiddle长上下文精度处理
2024/6/23 23:02:38

本文主要是介绍AI 大模型企业应用实战(13)-Lostinthemiddle长上下文精度处理,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
1 长文本切分信息丢失处理方案
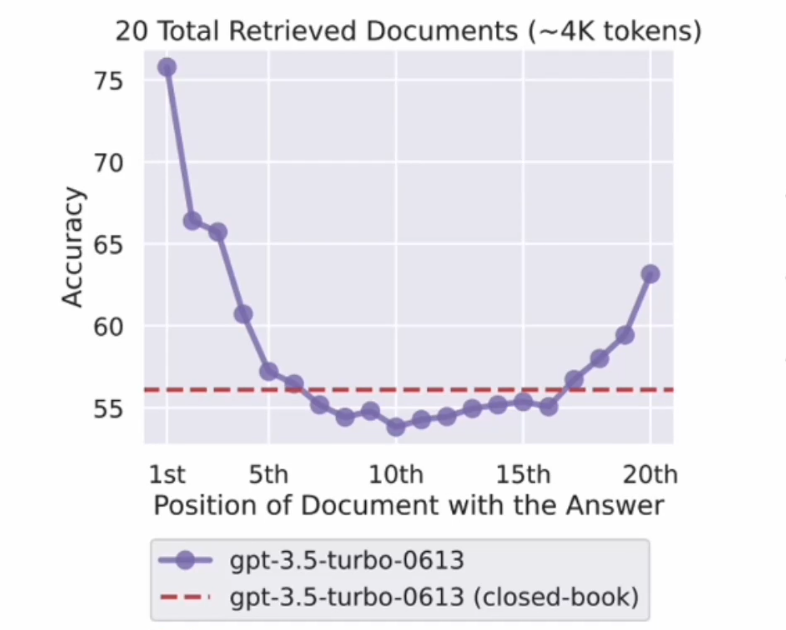
- 10+检索时性能大幅下降
- 相关信息在头尾性能最高
- 检索 ->> 排序 ->使用
实战
安装依赖:
! pip install sentence-transformers
演示如何使用 Langchain 库中的组件来处理长文本和检索相关信息。
- 导入所需的库
- 使用指定的预训练模型(MiniLM-L6-v2)创建嵌入对象
- 定义一系列与用户兴趣相关的文本
- 使用 Chroma 类从文本和嵌入中创建一个检索器,并设置搜索参数为返回前10个最相关的文档
- 定义一个查询语句,用于从检索到的文档中筛选相关信息
- 使用检索器根据查询语句获取相关文档
- 打印检索到的相关文档
# 导入所需的库
from langchain.chains import LLMChain, StuffDocumentsChain
from langchain.document_transformers import LongContextReorder
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.vectorstores import Chroma
# 使用Hugging Face托管的开源LLM来进行嵌入,这里选择MiniLM-L6-v2作为较小的LLM模型
# 向量维度为384维,支持多种语言。
embeddings = HuggingFaceBgeEmbeddings(model_name="all-MiniLM-L6-v2")
# 模拟一段长文本,这里是一系列与用户兴趣相关的句子
text = [
"篮球是一项伟大的运动。",
"带我飞往月球是我最喜欢的歌曲之一。",
"凯尔特人队是我最喜欢的球队。",
"这是一篇关于波士顿凯尔特人的文件。",
"我非常喜欢去看电影。",
"波士顿凯尔特人队以20分的优势赢得了比赛。",
"这只是一段随机的文字。",
"《艾尔登之环》是过去15年最好的游戏之一。",
"L.科内特是凯尔特人队最好的球员之一。",
"拉里.伯德是一位标志性的NBA球员。"
]
# 使用Chroma从文本和嵌入中创建一个检索器,并设置搜索参数为返回前10个最相关的文档
retrieval = Chroma.from_texts(text, embeddings).as_retriever(
search_kwargs={"k": 10}
)
# 定义查询语句
query = "关于我的喜好都知道什么?"
# 根据相关性从检索器中获取相关文档
docs = retrieval.get_relevant_documents(query)
# 打印结果
docs
HuggingFaceBgeEmbeddings V.S HuggingFaceEmbeddings
都是基于 Hugging Face Transformers 库的嵌入类,用于将文本转换为向量表示。它们之间的主要区别在于使用的预训练模型和数据集不同。
HuggingFaceEmbeddings 是基于 BERT(Bidirectional Encoder Representations from Transformers)模型的嵌入类,它使用了英文预训练模型。BERT 是一种基于 Transformer 结构的深度学习模型,通过在大规模语料库上进行预训练,学习到了丰富的语言表示能力。HuggingFaceEmbeddings 支持多种语言,包括中文,但默认情况下使用的是英文预训练模型。
HuggingFaceBgeEmbeddings 是针对中文场景特别优化的嵌入类,它使用了中文预训练模型。这些模型在大量的中文文本数据上进行预训练,能够更好地捕捉中文的语言特征和语义信息。HuggingFaceBgeEmbeddings 只支持中文,不支持其他语言。
因此,如需要处理英文文本,可以选择使用 HuggingFaceEmbeddings。如果您需要处理中文文本,建议使用 HuggingFaceBgeEmbeddings。
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM应用开发
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
- 编程严选网
这篇关于AI 大模型企业应用实战(13)-Lostinthemiddle长上下文精度处理的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-25树形模型进阶:从入门到初级应用教程
- 2024-12-25搜索算法进阶:新手入门教程
- 2024-12-25算法高级进阶:新手与初级用户指南
- 2024-12-25随机贪心算法进阶:初学者的详细指南
- 2024-12-25贪心算法进阶:从入门到实践
- 2024-12-25线性模型进阶:初学者的全面指南
- 2024-12-25朴素贪心算法教程:初学者指南
- 2024-12-25树形模型教程:从零开始的图形建模入门指南
- 2024-12-25搜索算法教程:初学者必备指南
- 2024-12-25算法高级教程:入门与初级用户指南



