AI大模型企业应用实战(21)-RAG的核心-结果召回和重排序
2024/6/24 23:02:37

本文主要是介绍AI大模型企业应用实战(21)-RAG的核心-结果召回和重排序,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
1 完整RAG应用的检索流程

从用户输入Query到最终输出答案的各个步骤。整个流程包括Query预处理、检索召回、排序等关键环节,每个环节都有不同的技术和方法来提升检索效果。
2 Query预处理
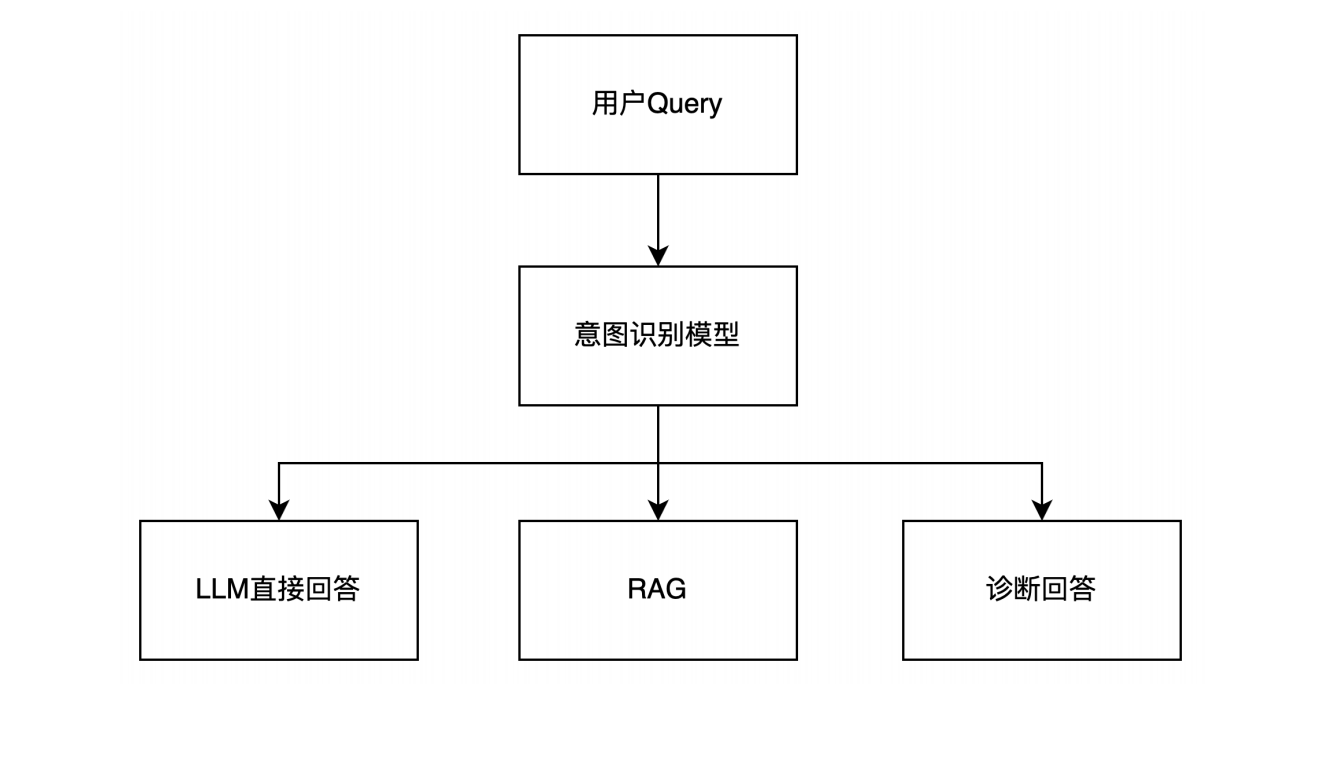
2.1 意图识别
判断query问的是什么类型的问题,从而决定是否走RAG链路。
示例1
- 深圳有啥好玩的? 闲聊问题
- VDB支持哪些检索算法? 产品常见问题
示例2
- 为啥某个MongoDB实例内存占用过高? 检查类问题
- 云Redis咋扩容? 产品常见问题
流程图
2.2 生成同义query
针对query生成同义句,不同问法提高召回,检索结果做合并。
示例1:VDB支持哪些检索算法
- 列举一下VDB所支持的检索算法
- VDB有哪些可用的检索算法
示例2: 腾讯云向量数据库的优势是什么
- 腾讯云向量数据库有哪些主要优点
- 腾讯云向量数据库的核心竞争力是什么
流程图

2.3 query标准化
针对query中的专有名词、简写、英文做标准化处理。
示例1:VDB支持哪些检索算法
腾讯云向量数据库支持哪些检索算法
示例2:COS如何上传对象
腾讯云对象存储如何上传对象
流程图

3 检索召回

每次召回时,如何提升结果的排序效果,使与Query更相关的结果更靠前?
- 使用更有效的索引技术:使用更高级的索引技术如倒排索引、压缩倒排索引等可以加速检索过程并提高结果的相关性。这些技术可以使得相似的文档在索引中更靠近,从而使得相关的结果更容易被召回。
- 优化检索模型:使用适合任务的检索模型如BM25、BERT等,这些模型可以更好地捕捉文档之间的语义和相关性,从而提升召回结果的质量。
- 利用用户反馈:收集用户的点击、浏览、收藏等行为反馈信息,通过机器学习算法不断优化排序模型,使得更符合用户兴趣的结果更容易被召回并排在前面。
- 引入上下文信息:考虑查询的上下文信息,比如用户的地理位置、设备信息、搜索历史等,可以更好地理解用户意图,提升召回结果的相关性。
- 使用深度学习技术:利用深度学习技术如卷积神经网络、循环神经网络等,可以更好地学习文档之间的语义关系,从而提高结果的排序效果。
- 结合多种特征:结合文本特征、结构特征、用户特征等多种特征进行综合排序,可以更全面地考虑到文档与查询之间的相关性。
综合运用以上方法,可以在召回阶段有效提升结果排序效果,使得与Query更相关的结果更靠前。
Query预处理中,做了生成同义Query,最终应该如何合并检索结果?
- 加权融合:给每个查询生成的同义Query分配一个权重,并根据权重对检索结果进行加权融合。权重可以根据同义Query的相似性、生成方法的可靠性等因素来确定。
- 组合排序:将原始查询和同义查询的检索结果分别进行排序,然后将两个排序结果进行组合排序。可以根据不同的排序方法(如TF-IDF、BM25等)来进行组合排序,也可以采用机器学习模型进行组合排序。
- 基于规则的合并:制定一些规则来合并检索结果,例如保留两个查询中都包含的结果、去除重复的结果等。这种方法比较简单直接,但需要根据具体场景制定合适的规则。
- 交叉验证:将生成的同义Query和原始Query分别用于检索,并根据评估指标(如准确率、召回率等)来选择最优的检索结果。可以通过交叉验证或者在线评估来验证合并结果的效果。
- 利用用户反馈:收集用户对不同查询结果的反馈信息,根据反馈信息调整查询结果的排序和合并策略,使得更符合用户需求的结果更容易被展示在前面。
无论采用哪种方法,都需要结合具体的业务需求和数据特点来选择合适的合并检索结果的策略,以确保最终展示给用户的结果具有更高的相关性和质量。
如何在召回阶段,将召回的结果效果做得更优质,减少干扰信息对LLM的影响?
- 使用更精准的召回模型:使用更高效和精准的召回模型,如基于BERT、RoBERTa等预训练语言模型的语义匹配模型,能够更好地捕捉文本之间的语义关系,减少不相关文档的召回。
- 利用领域知识和规则过滤:结合领域知识和规则,对召回结果进行过滤和筛选,去除明显不相关或低质量的文档。例如,可以使用领域词典、实体识别等技术进行过滤。
- 考虑上下文信息:在召回阶段考虑用户的上下文信息,如搜索历史、用户兴趣等,通过个性化的方式调整召回结果,提高相关性。
- 引入负采样:在训练召回模型时引入负采样技术,增加负样本的多样性和难度,使得模型更好地区分干扰信息和相关信息。
- 加入用户反馈机制:收集用户对召回结果的反馈信息,如点击、滑动、停留时间等,根据反馈信息调整召回模型和排序策略,提高用户满意度和相关性。
- 优化评估指标:在评估召回结果时,不仅要关注传统的准确率、召回率等指标,还要考虑到与LLM输入的匹配度、语义相似度等指标,以更全面地评估召回结果的质量。
通过综合利用以上方法,在召回阶段可以更有效地优化召回结果,减少干扰信息对LLM的影响,提高模型的性能和效果。
4 排序
4.1 为啥要排序(Rerank)
Rerank:RAG中百尺竿头更进一步

Embedding模型存在一定的局限性:实际召回结果中,embedding没办法完全反应出语义的相似性,至少这K个文件的排名并不是我们认为的从高分到低分排序的。
排序模型的目的在于对召回内容有一个更合理的排序结果,减少提供给模型的上下文长度,长度越长,对模型来说压力越大。

基于Learning2Rank的思路提升文本语义排序效果:

Listwise的优化

指示函数做近似:

最终loss function:
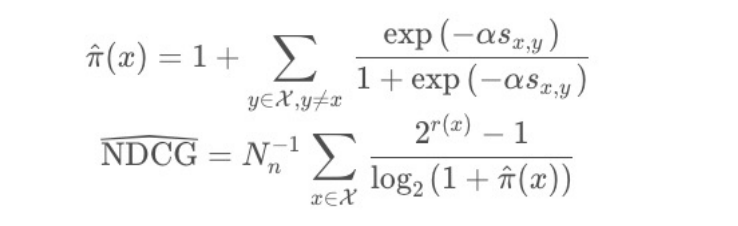

关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM应用开发
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
- 编程严选网
这篇关于AI大模型企业应用实战(21)-RAG的核心-结果召回和重排序的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-25树形模型进阶:从入门到初级应用教程
- 2024-12-25搜索算法进阶:新手入门教程
- 2024-12-25算法高级进阶:新手与初级用户指南
- 2024-12-25随机贪心算法进阶:初学者的详细指南
- 2024-12-25贪心算法进阶:从入门到实践
- 2024-12-25线性模型进阶:初学者的全面指南
- 2024-12-25朴素贪心算法教程:初学者指南
- 2024-12-25树形模型教程:从零开始的图形建模入门指南
- 2024-12-25搜索算法教程:初学者必备指南
- 2024-12-25算法高级教程:入门与初级用户指南



