AutoMQ 生态集成 Kafdrop-ui
2024/7/15 21:03:01

本文主要是介绍AutoMQ 生态集成 Kafdrop-ui,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
Kafdrop [1] 是一个为 Kafka 设计的简洁、直观且功能强大的Web UI 工具。它允许开发者和管理员轻松地查看和管理 Kafka 集群的关键元数据,包括主题、分区、消费者组以及他们的偏移量等。通过提供一个用户友好的界面,Kafdrop 大大简化了 Kafka 集群的监控和管理过程,使得用户无需依赖复杂的命令行工具就能快速获取集群的状态信息。得益于 AutoMQ 对 Kafka 的完全兼容,因此可以无缝与 Kafdrop 进行集成。通过利用Kafdrop,AutoMQ 用户也可以享受到直观的用户界面,实时监控Kafka集群状态,包括主题、分区、消费者组及其偏移量等关键元数据。这种监控能力不仅提高了问题诊断的效率,还有助于优化集群性能和资源利用率。这篇教程会教你如何启动 Kafdrop 服务,并将其与 AutoMQ 集群搭配起来使用,实现集群状态的监控和管理。
Kafdrop界面
01
前置条件
-
Kafdrop 的环境:AutoMQ 集群以及 JDK17,Maven 3.6.3 以上。
-
Kafdrop 可以通过 JAR 包运行,Docker 部署 以及 protobuf 方式部署。可参考 官方文档 [3] 。
-
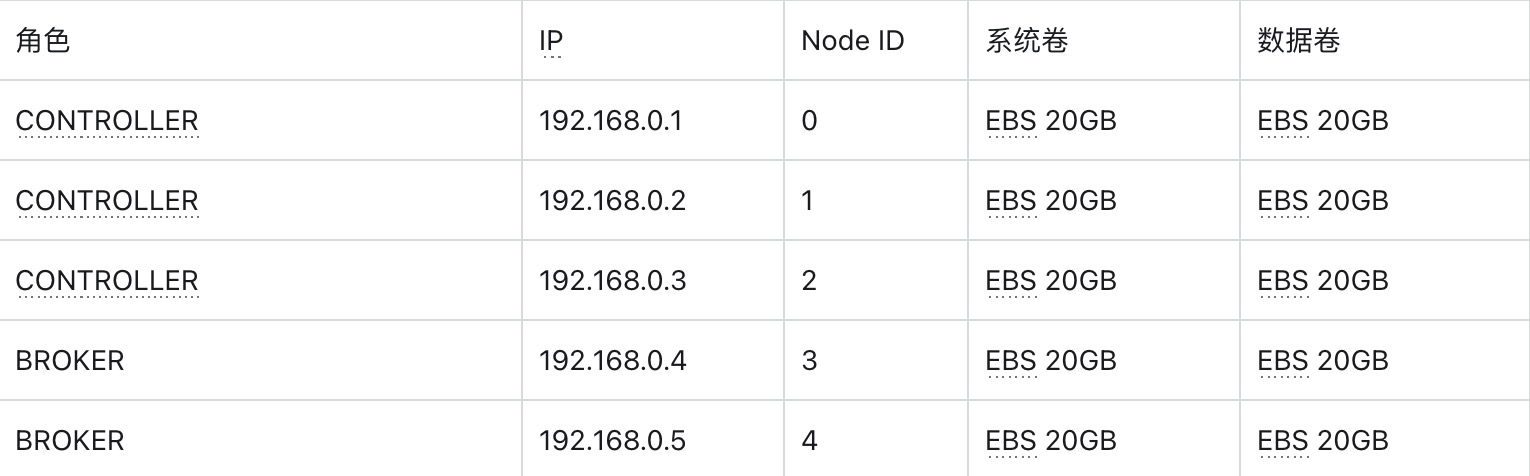
准备 5 台主机用于部署 AutoMQ 集群。建议选择 2 核 16GB 内存的 Linux amd64 主机,并准备两个虚拟存储卷。示例如下:
Tips:
-
请确保这些机器处于相同的网段,可以互相通信
-
非生产环境也可以只部署 1 台 Controller,默认情况下该 Controller 也同时作为 broker 角色
-
从 AutoMQ Github Releases 下载最新的正式二进制安装包,用于安装 AutoMQ。
下面我将先搭建 AutoMQ 集群,再启动 Kafdrop。
02
安装并启动 AutoMQ 集群
配置S3 URL
第一步:生成 S3 URL
AutoMQ 提供了 automq-kafka-admin.sh 工具,用于快速启动 AutoMQ。只需提供包含所需 S3 接入点和身份认证信息的 S3 URL,即可一键启动 AutoMQ,无需手动生成集群 ID 或进行存储格式化等操作。
### 命令行使用示例 bin/automq-kafka-admin.sh generate-s3-url \ --s3-access-key=xxx \ --s3-secret-key=yyy \ --s3-region=cn-northwest-1 \ --s3-endpoint=s3.cn-northwest-1.amazonaws.com.cn \ --s3-data-bucket=automq-data \ --s3-ops-bucket=automq-ops
注意:需要提前配置好 aws 的 s3 bucket ,如果遇到报错,请注意验证参数正确性以及格式。
输出结果
执行该命令后,将自动按以下阶段进行:
-
根据提供的 accessKey 和 secret Key 对 S3 基本功能进行探测,以验证 AutoMQ 和 S3 的兼容性。
-
根据身份信息,接入点信息生成 s3url。
-
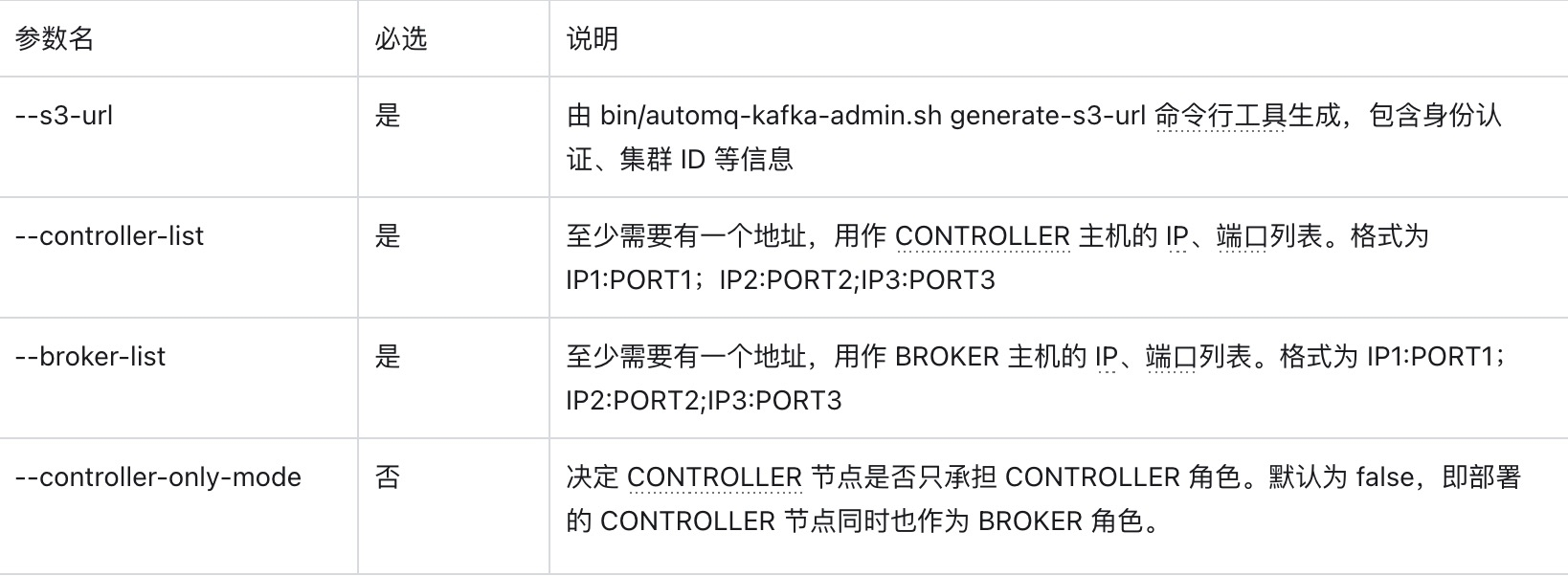
根据 s3url 获取启动 AutoMQ 的命令示例。在命令中,将 --controller-list 和 --broker-list 替换为实际需要部署的 CONTROLLER 和 BROKER。
执行结果示例如下:
############ Ping s3 ######################## [ OK ] Write s3 object [ OK ] Read s3 object [ OK ] Delete s3 object [ OK ] Write s3 object [ OK ] Upload s3 multipart object [ OK ] Read s3 multipart object [ OK ] Delete s3 object ############ String of s3url ################ Your s3url is: s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=xxx&s3-secret-key=yyy&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA ############ Usage of s3url ################ To start AutoMQ, generate the start commandline using s3url. bin/automq-kafka-admin.sh generate-start-command \ --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" \ --controller-list="192.168.0.1:9093;192.168.0.2:9093;192.168.0.3:9093" \ --broker-list="192.168.0.4:9092;192.168.0.5:9092" TIPS: Please replace the controller-list and broker-list with your actual IP addresses.
第 2 步:生成启动命令列表
将上一步生成的命令中的 --controller-list 和 --broker-list 替换为你的主机信息,具体来说,将它们替换为环境准备中提到的 3 台 CONTROLLER 和 2 台 BROKER 的 IP 地址,并且使用默认的 9092 和 9093 端口。
bin/automq-kafka-admin.sh generate-start-command --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --controller-list="192.168.0.1:9093;192.168.0.2:9093;192.168.0.3:9093" --broker-list="192.168.0.4:9092;192.168.0.5:9092"
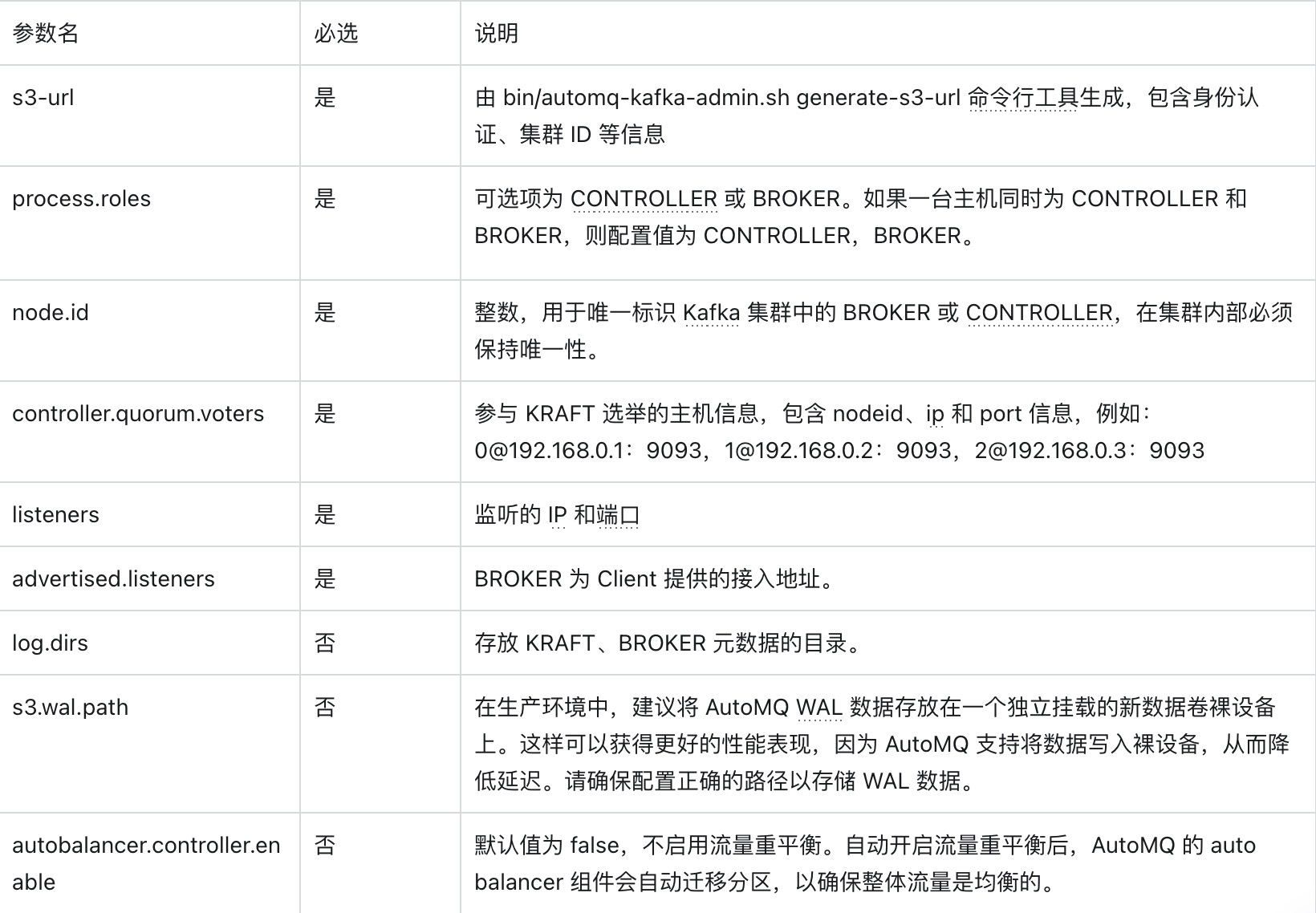
参数说明
输出结果
执行命令后,会生成用于启动 AutoMQ 的命令。
############ Start Commandline ############## To start an AutoMQ Kafka server, please navigate to the directory where your AutoMQ tgz file is located and run the following command. Before running the command, make sure that Java 17 is installed on your host. You can verify the Java version by executing 'java -version'. bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker,controller --override node.id=0 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.1:9092,CONTROLLER://192.168.0.1:9093 --override advertised.listeners=PLAINTEXT://192.168.0.1:9092 bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker,controller --override node.id=1 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.2:9092,CONTROLLER://192.168.0.2:9093 --override advertised.listeners=PLAINTEXT://192.168.0.2:9092 bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker,controller --override node.id=2 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.3:9092,CONTROLLER://192.168.0.3:9093 --override advertised.listeners=PLAINTEXT://192.168.0.3:9092 bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker --override node.id=3 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.4:9092 --override advertised.listeners=PLAINTEXT://192.168.0.4:9092 bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker --override node.id=4 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.5:9092 --override advertised.listeners=PLAINTEXT://192.168.0.5:9092 TIPS: Start controllers first and then the brokers.
注意:node.id 默认从 0 开始自动生成。
第 3 步:启动 AutoMQ
参数说明
使用启动命令时,未指定的参数将采用 Apache Kafka 的默认配置。对于 AutoMQ 新增的参数,将使用 AutoMQ 提供的默认值。要覆盖默认配置,可以在命令末尾添加额外的 --override key=value 参数来覆盖默认值。
Tips:
- 若需启用持续流量重平衡或运行 Example: Self-Balancing When Cluster Nodes Change,建议在启动时为 Controller 明确指定参数 --override autobalancer.controller.enable=true。
03
启动 Kafdrop 服务
上述过程中,我们已经搭建了 AutoMQ 集群,并知道了所有的 broker 节点监听的地址和端口。接下来我们将着手启动 Kafdrop 的服务。
注意:要保证 Kafdrop 的服务所在地址是能够访问到 AutoMQ 集群的,否则会导致连接超时等问题。
本例我采用 JAR 包的方式启动 Kafdrop 的服务。步骤如下:
- 拉取 Kafdrop 仓库源码:Kafdrop github [4]
git clone https://github.com/obsidiandynamics/kafdrop.git
- 使用 Maven 在本地编译打包 Kafdrop,以生成 JAR 文件。在根目录下执行
mvn clean compile package
- 启动服务,需要指定 AutoMQ 集群 brokers 的地址和端口:
java --add-opens=java.base/sun.nio.ch=ALL-UNNAMED -jar target/kafdrop-<version>.jar --kafka.brokerConnect=<host:port,host:port>,...
-
kafdrop-.jar需要替换为具体版本,如kafdrop-4.0.2-SNAPSHOT.jar。
-
–kafka.brokerConnect=需要指定 host 和 port 为具体的集群 broker 节点。
控制台启动效果如下:
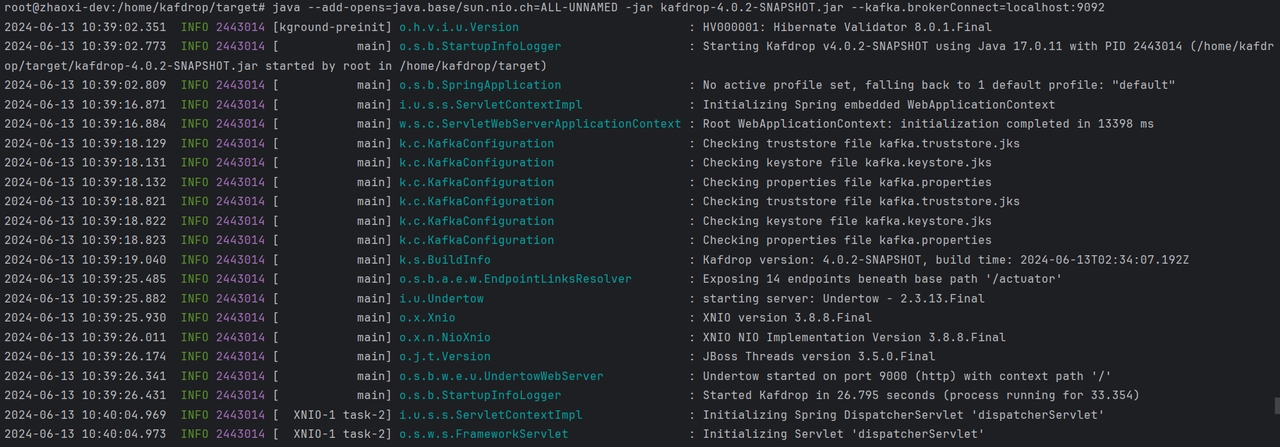
如果未指定,则kafka.brokerConnect默认为localhost:9092。注意:从 Kafdrop 3.10.0 开始,不再需要 ZooKeeper 连接。所有必要的集群信息都通过 Kafka 管理 API 检索。打开浏览器并导航到 http://localhost:9000。可以通过添加以下配置来覆盖端口:
--server.port=<port> --management.server.port=<port>
04
最终效果
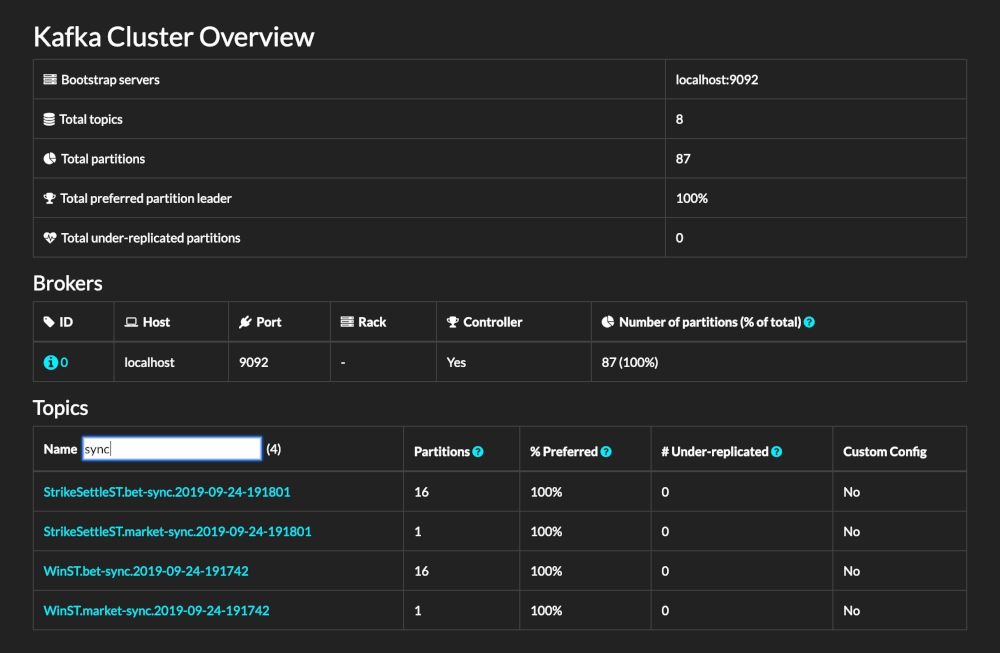
- 完整界面
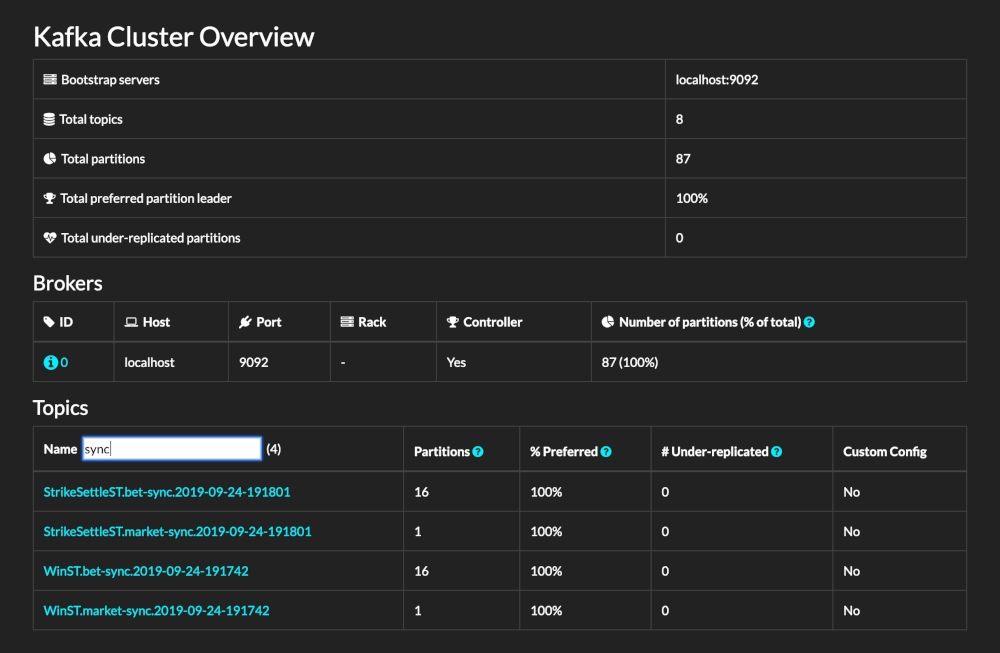
展示了分区数,Topics 数以及其他集群状态信息。
2.新建 Topic 功能
3. broker 节点详细信息
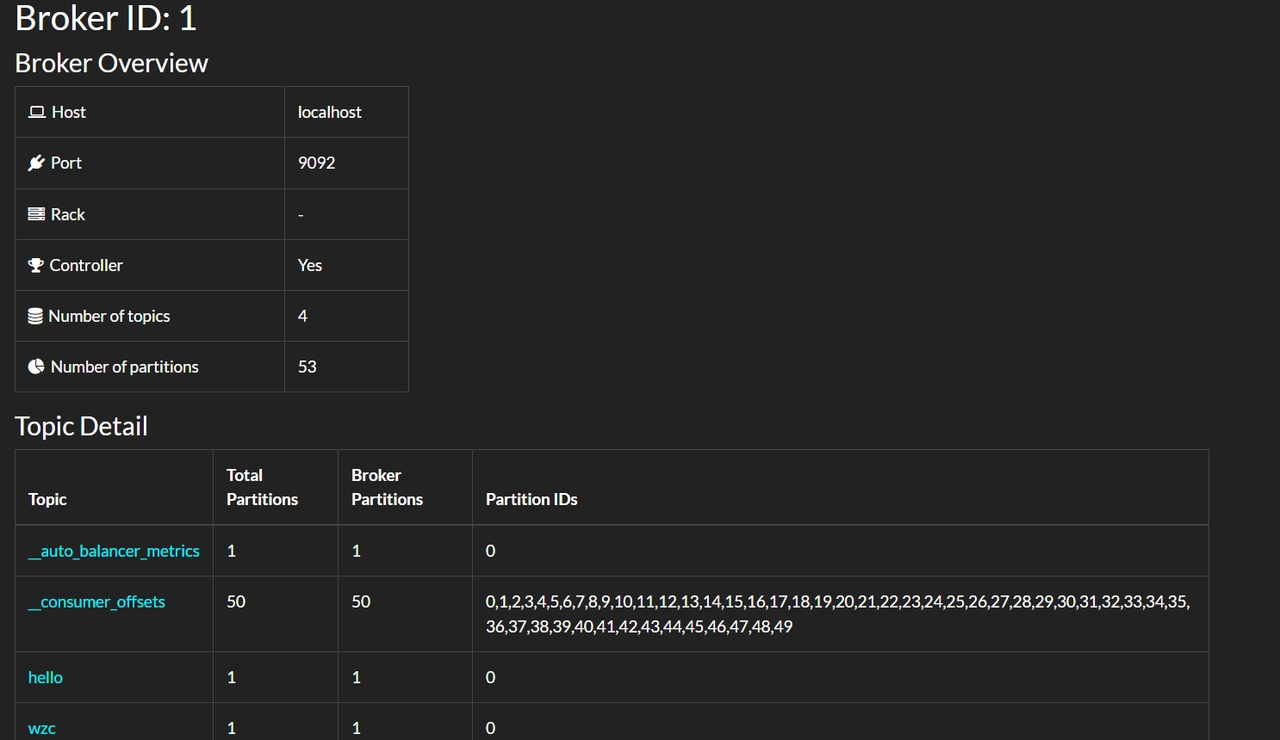
4.Topic 详细信息
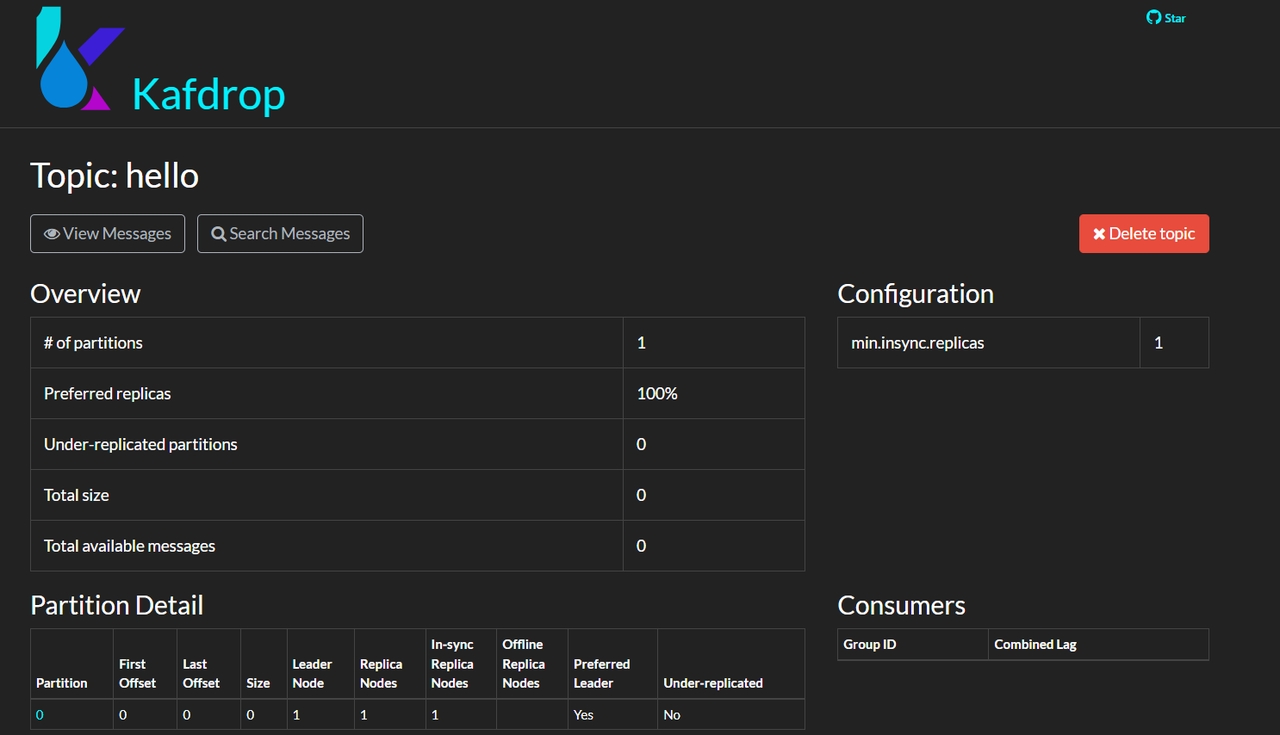
5.Topic 下的消息信息
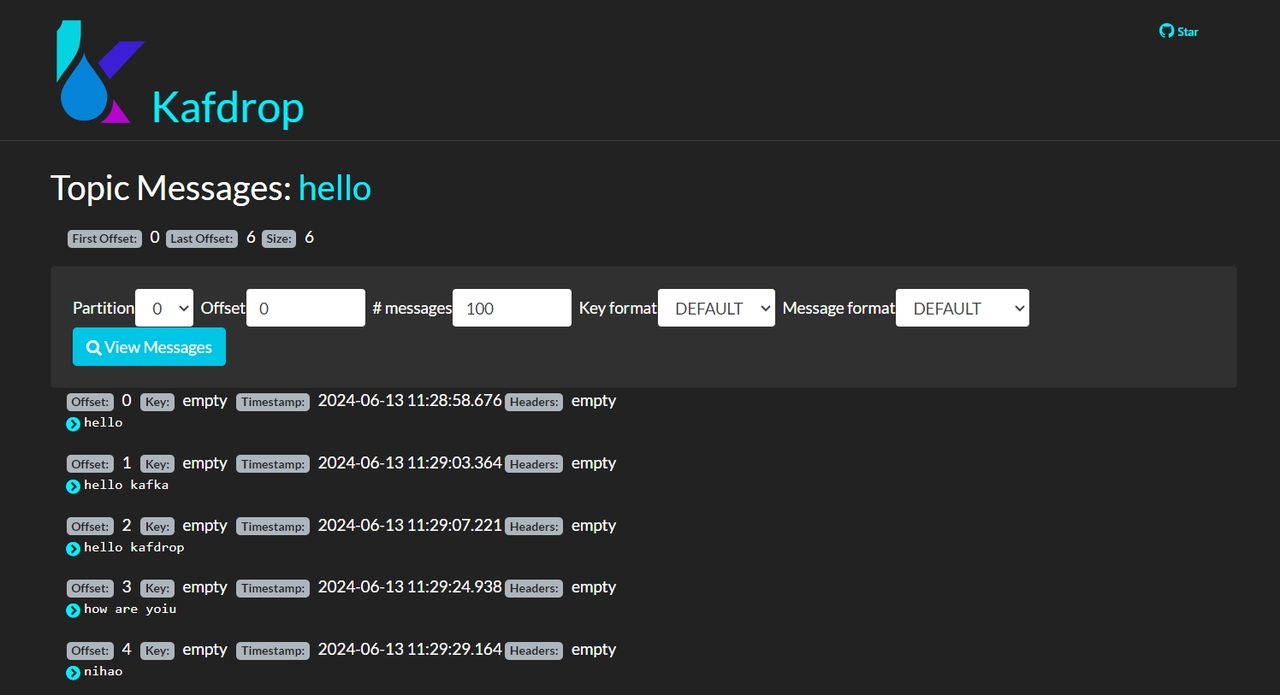
05
总结
通过本教程,我们探索了 Kafdrop 的关键特性、功能以及与 AutoMQ 集群集成的方法,展示了如何轻松地监控和管理 AutoMQ 集群。Kafdrop 的使用不仅能够帮助团队更好地理解和控制他们的数据流,还能够提升开发和运维效率,确保数据处理流程的高效稳定。希望本教程能够为你在使用 Kafdrop 与 AutoMQ 集群时提供有价值的见解和帮助。
参考资料
[1] Kafdrop:https://github.com/obsidiandynamics/kafdrop
[2] AutoMQ:https://www.automq.com/zh
[3] Kafdrop 部署方式:https://github.com/obsidiandynamics/kafdrop/blob/master/README.md#getting-started
[4] Kafdrop 项目仓库:https://github.com/obsidiandynamics/kafdrop
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
这篇关于AutoMQ 生态集成 Kafdrop-ui的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-21MQ-2烟雾传感器详解
- 2024-12-09Kafka消息丢失资料:新手入门指南
- 2024-12-07Kafka消息队列入门:轻松掌握Kafka消息队列
- 2024-12-07Kafka消息队列入门:轻松掌握消息队列基础知识
- 2024-12-07Kafka重复消费入门:轻松掌握Kafka消费的注意事项与实践
- 2024-12-07Kafka重复消费入门教程
- 2024-12-07RabbitMQ入门详解:新手必看的简单教程
- 2024-12-07RabbitMQ入门:新手必读教程
- 2024-12-06Kafka解耦学习入门教程
- 2024-12-06Kafka入门教程:快速上手指南



