一文看懂AI的 Transformer 架构!
2024/7/22 23:32:41

本文主要是介绍一文看懂AI的 Transformer 架构!,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
1 AI的转换器是啥?
转换器,一种将输入序列转换或更改为输出序列的神经网络架构。它们通过学习上下文和跟踪序列组件之间的关系来做到这一点。例如,请考虑以下输入序列:“天空是什么颜色的?” 转换器模型会使用内部数学表示法来识别颜色、天空和蓝色这三个词之间的相关性和关系。利用这些知识,它会生成输出:“天空是蓝色的。”
组织可以使用转换器模型进行所有类型的序列转换,包括语音识别、机器翻译以及蛋白质序列分析。
神经网络
AI
2 为啥转换器重要?
早期深度学习模型主要侧重自然语言处理(NLP)任务,旨在让计算机理解和响应自然人类语言。它们根据前一个单词按顺序猜出下一个单词。
为更好理解,考虑手机中的自动完成功能。根据键入单词对的频率提出建议。如经常键入“我很好”,在键入很之后,手机会自动提示好。
早期机器学习(ML)模型在更广泛的范围内应用类似技术。它们绘制训练数据集中不同单词对或单词组之间的关系频率,并试图猜出下一个单词。然而,早期技术无法保留超过一定输入长度上下文。如早期的 ML 模型无法生成有意义段落,因为它无法保留段落中第一句话和最后一句话之间的上下文。要生成诸如“我来自意大利。我喜欢骑马。我会说意大利语。”等输出,模型需记住意大利和意大利语之间联系,而早期神经网络根本做不到。
转换器模型从根本改变 NLP 技术,使模型能处理文本中的这种长期依赖关系。
转换器的更多好处。
2.1 启用大规模模型
转换器通过并行计算处理整个长序列,这大大减少了训练和处理时间。这使得训练可以学习复杂语言表示的超大型语言模型(LLM)(例如 GPT 和 BERT)成为可能。它们拥有数十亿个参数,可以捕获各种人类语言和知识,并且它们正在推动研究朝着更具通用性的 AI 系统发展。
大型语言模型
GPT
2.2 实现更快的自定义
使用转换器模型,可用RAG技术。这些技术支持为行业组织特定的应用程序自定义现有模型。模型可在大型数据集上进行预训练,然后在较小的特定于任务的数据集上进行微调。这种方法使复杂模型的使用大众化,并消除了从头开始训练大型模型时的资源限制。模型可以在多个领域和不同使用案例的任务中表现良好。
2.3 促进多模态 AI 系统
借助转换器,可将 AI 用于组合复杂数据集的任务。如DALL-E这样的模型表明,转换器可结合 NLP 和计算机视觉,根据文本描述生成图像。借助转换器,可创建集成不同信息类型并更紧密地模仿人类的理解和创造力的 AI 应用程序。
计算机视觉
2.4 人工智能研究和行业创新
转换器创造新一代 AI 技术和 AI 研究,突破 ML 可能性的界限。它们的成功激发了解决创新问题的新架构和应用程序。它们使机器能够理解和生成人类语言,从而开发出增强客户体验和创造新商机的应用程序。
3 转换器使用案例?
可用任何顺序数据(例如人类语言、音乐创作、编程语言等)训练大型转换器模型。
3.1 自然语言处理
转换器使机器能够以比以往任何时候都更准确的方式理解、解释和生成人类语言。它们可以总结大型文档,并为各种使用案例生成连贯且与上下文相关的文本。像 Alexa 这样的虚拟助手使用转换器技术来理解和响应语音命令。
3.2 机器翻译
翻译应用程序使用转换器在不同语言之间提供实时、准确的翻译。与以前的技术相比,转换器极大地提高了翻译的流畅性和准确性。
机器翻译
3.3 DNA 序列分析
通过将 DNA 片段视为类似于语言的序列,转换器可以预测基因突变的影响,了解遗传模式,并帮助识别导致某些疾病的 DNA 区域。这种能力对于个性化医学至关重要,在个性化医学中,了解个体的基因组成可以带来更有效的治疗。
3.4 蛋白质结构分析
转换器模型可处理顺序数据,这使其非常适合对折叠成复杂蛋白质结构的长链氨基酸进行建模。了解蛋白质结构对于药物发现和理解生物过程至关重要。您还可以在基于氨基酸序列预测蛋白质三维结构的应用程序中使用转换器。
4 转换器的工作原理
自 21 世纪初,神经网络一直是各种人工智能任务(如图像识别和 NLP)的主导方法。它们由层互连的计算节点或神经元组成,这些节点或神经元模仿人脑并协同工作以解决复杂的问题。
处理数据序列的传统神经网络通常使用编码器/解码器架构模式:
- 编码器读取和处理整个输入数据序列,如英语句子,并将其转换为紧凑的数学表示形式。这种表示形式是捕获输入本质的摘要
- 然后,解码器获取此摘要并逐步生成输出序列,该序列可以是翻译成法语的相同句子
这过程是按序进行,即它必须一个接一个地处理每个单词或数据的一部分。这个过程很慢,在很长的距离上可能会丢失一些更精细的细节。
4.1 自注意力机制
转换器模型通过整合所谓的自注意力机制来修改这一过程。该机制不是按顺序处理数据,而是使模型能同时查看序列的不同部分,并确定哪些部分最重要。
想象在一个繁忙嘈杂房间,试图听清别人说话。大脑会自动专注于他们声音,同时抑制不太重要噪音。自注意力使模型能够做类似的事情:它更关注相关信息位,并将它们结合起来,做出更好的输出预测。这种机制提高了转换器的效率,使它们能够在更大的数据集上接受训练。它也更有效,尤其是在处理长文本片段时,很久以前的上下文可能会影响接下来的内容的含义。
5 转换器架构由哪些组件组成?
转换器神经网络架构具有多个软件层,协同工作以生成最终输出。转换体系结构的组件:
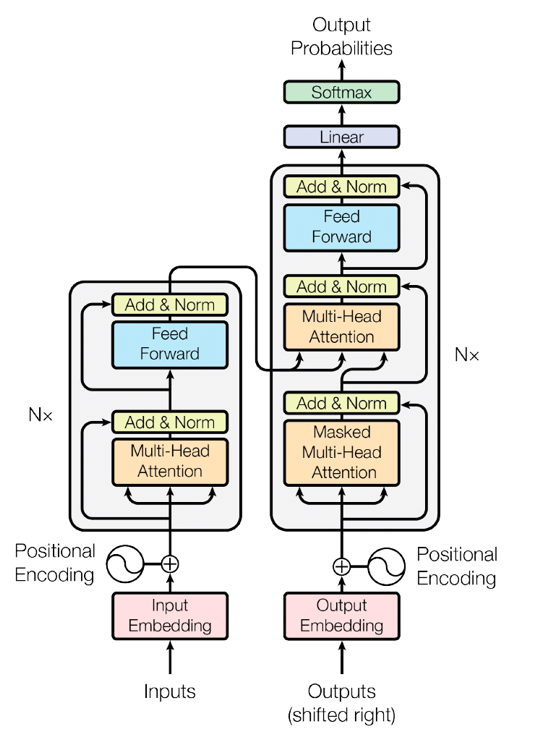
编码器(左边)和解码器(右边):
编码器(Encoder)
-
输入嵌入(Input Embedding):将输入的词嵌到一个高维向量空间中,这样每个词都表示为一个向量
-
位置编码(Positional Encoding):由于Transformer模型没有像RNN那样的时间序列信息,需要加入位置编码来提供词语在句子中的位置信息。位置编码和输入嵌入相加后作为编码器的输入。
-
多头自注意力机制(Multi-Head Self-Attention):
- 自注意力机制(Self-Attention):计算输入序列中每个词与其他词之间的注意力得分。通过注意力得分,模型可捕捉到词与词之间的依赖关系
- 多头机制(Multi-Head):通过多个注意力头(Head)来捕捉不同的注意力模式。每个头独立计算注意力,最后将它们的输出拼接
-
加和规范化(Add & Norm):每个多头自注意力和前馈神经网络的输出都会和输入进行相加,然后进行层规范化(Layer Normalization)
-
前馈神经网络(Feed Forward):一个包含两个线性变换和一个激活函数的全连接层。这个层对每个位置的输入独立进行处理
解码器(Decoder)
-
输出嵌入(Output Embedding):将目标序列的词嵌入到一个高维向量空间中
-
位置编码(Positional Encoding):与编码器的相同,将位置编码和输出嵌入相加后作为解码器的输入
-
遮掩多头自注意力机制(Masked Multi-Head Self-Attention):在解码器中,对自注意力机制进行遮掩处理,以确保预测下一个词时不能看到未来的词。这是通过遮掩矩阵实现的
-
多头注意力机制(Multi-Head Attention):解码器的每个层还有一个额外的多头注意力层,它对编码器的输出进行注意力计算。这允许解码器在生成词语时参考输入序列的信息
-
加和规范化(Add & Norm):与编码器的相同
-
前馈神经网络(Feed Forward):与编码器的相同
最终输出
-
线性层(Linear):将解码器的输出映射到词汇表大小的向量
-
Softmax:将线性层的输出通过Softmax变换为概率分布,表示生成每个词的概率
总结
Transformer模型通过多层堆叠的编码器和解码器结构实现了高效的序列到序列的转换。在编码器中,通过多头自注意力机制捕捉输入序列中词与词之间的关系;在解码器中,通过遮掩多头自注意力机制和多头注意力机制实现生成目标序列时的依赖关系。最终通过线性层和Softmax层生成词的概率分布。
这个架构的优点在于它可以并行处理输入数据,避免了RNN中序列处理的时间复杂度,同时通过多头注意力机制捕捉了丰富的上下文信息。
5.1 输入嵌入
此阶段将输入序列转换为软件算法可以理解的数学域:
- 首先,输入序列分解为一系列标记或单个序列组件。如输入是个句子,则标记就是单词
- 然后,嵌入将标记序列转换为数学向量序列。向量携带语义和语法信息,以数字表示,其属性是在训练过程中学习的
可将向量可视化为 n 维空间中的一系列坐标。如一个二维图表,其中 x 代表单词第一个字母的字母数字值,y 代表它们的类别。香蕉一词的值为 (2,2),因为它以字母 b 开头,属于水果类别。芒果一词的值为 (13,2),因为它以字母 m 开头,也属于水果类别*。这样,向量 (x, y) 告诉神经网络,香蕉和芒果*这两个词属于同一类别。
想象一个 n 维空间,其中包含数千个属性,这些属性涉及映射到一系列数字的句子中的任何单词的语法、含义和用法。软件可以使用这些数字来计算数学术语中单词之间的关系,并理解人类语言模型。嵌入提供了一种将离散标记表示为连续向量的方法,模型可以处理和学习这些向量。
5.2 位置编码
模型本身并不按顺序处理顺序数据。转换器要一种方法来考虑输入序列中标记的顺序。
位置编码向每个标记的嵌入中添加信息,以指示其在序列中的位置。这通常是通过使用一组函数来完成的,这些函数生成一个唯一的位置信号,并将其添加到每个标记的嵌入中。通过位置编码,模型可以保留标记的顺序并理解序列上下文。
5.3 转换器数据块
典型的转换器模型将多个转换器数据块堆叠在一起。每个转换器模块都有两个主要组件:多头自注意力机制和位置前馈神经网络。自注意力机制使模型能够权衡序列中不同标记的重要性。在进行预测时,它侧重于输入的相关部分。
如以“不要说谎”和“他躺下”这两句话为例。**“在这两句话中,如果不看旁边的单词,就无法理解躺这个词的含义。“说”和“下”这两个词对于理解正确的含义至关重要。自注意力可以根据上下文对相关标记进行分组。
前馈层具有其他组件,可帮助转换器模型更有效地训练和运行。例如,每个转换器模块包括:
- 围绕两个主要组件的连接,就像快捷方式。它们使信息能够从网络的一部分流向另一部分,从而跳过两者之间的某些操作
- 层归一化将数字(特别是网络中不同层的输出)保持在一定范围内,以便模型平稳训练
- 线性变换函数使模型能够调整值,以更好地执行正在训练的任务,例如文档摘要,而不是翻译
5.4 线性数据块和 Softmax 数据块
最终,模型需要做出具体预测,如选择序列中的下一个单词。这就是线性数据块的用处。它是最后阶段之前的另一个全连接层,也称为密集层。它执行从向量空间到原始输入域的学习线性映射。在这个关键层,模型的决策部分采用复杂的内部表示形式,然后将其转化为可以解释和使用的特定预测。该层的输出是每个可能的标记的一组分数(通常称为对数)。
Softmax 函数是获取对数分数并将其归一化为概率分布的最后阶段。Softmax 输出的每个元素都表示模型对特定类或标记的置信度。
6 转换器与其他神经网络架构有何不同?
循环神经网络 (RNN) 和卷积神经网络 (CNN) 是机器学习和深度学习任务中经常使用的其他神经网络。以下内容探讨了它们与转换器的关系。
6.1 转换器与RNN
转换器模型和 RNN 都是用于处理顺序数据的架构。
RNN 在循环迭代中一次处理一个元素的数据序列。该过程从输入层接收序列的第一个元素开始。然后将信息传递到隐藏层,该隐藏层处理输入并将输出传递到下一个时间步骤。此输出与序列的下一个元素相结合,将反馈到隐藏层。该循环对序列中的每个元素重复执行,RNN 保持一个隐藏的状态向量,该向量会在每个时间步骤进行更新。此过程有效地使 RNN 能够记住过去输入的信息。
相比之下,转换器同时处理整个序列。与 RNN 相比,这种并行化可以缩短训练时间,并且能够处理更长的序列。转换器中的自注意力机制还使模型能够同时考虑整个数据序列。这样就无需复发或隐藏向量。相反,位置编码会维护有关序列中每个元素位置的信息。
许多应用中尤其NLP任务,转换器很大程度取代 RNN,因为它们可更有效处理长期依赖关系。还具有比 RNN 更高的可扩展性和效率。RNN 在某些情况下仍然有用,尤其是在模型大小和计算效率比捕获长距离交互更重要的情况下。
6.2 转换器与CNN
CNN 专为网格类数据(例如图像)而设计,其中空间层次结构和位置是关键。它们使用卷积层对输入应用筛选条件,通过这些筛选后的视图捕获局部图案。例如,在图像处理中,初始层可以检测边缘或纹理,而更深层可以识别更复杂的结构,例如形状或对象。
转换器主要设计用于处理顺序数据,无法处理图像。视觉转换器模型现在正在通过将图像转换为顺序格式来处理图像。但对许多实际的计算机视觉应用,CNN 仍是有效和高效选择。
7 转换器模型有哪些不同类型?
转换器已经发展成为一个多样化的架构系列。
一些类型的转换器模型。
7.1 双向转换器
基于转换器的双向编码器表示形式(BERT)修改了基本架构,以处理与句子中所有其他单词相关的单词,而不是孤立地处理单词。从技术上讲,它采用了一种称为双向掩码语言模型(MLM)的机制。在预训练期间,BERT 会随机屏蔽一定比例的输入标记,并根据其上下文预测这些被屏蔽的标记。双向方面源于这样一个事实,即 BERT 同时考虑了两层中从左到右和从右到左的标记序列,以便更好地理解。
7.2 生成式预训练转换器
GPT 模型使用堆叠转换器解码器,这些解码器使用语言建模目标在大型文本语料库上进行预训练。它们是自回归的,即它们会根据所有先前的值回归或预测序列中的下一个值。
通过超过 1750 亿个参数,GPT 模型可生成根据风格和语气进行调整的文本序列。GPT 模型引发了人工智能对实现通用人工智能的研究。这意味着组织可以在重塑其应用程序和客户体验的同时达到新的生产力水平。
7.3 双向和自回归转换器
双向和自回归转换器 (BART) 是一种结合了双向和自回归属性的变压器模型。它就像是 BERT 的双向编码器和 GPT 的自回归解码器的混合体。它一次读取整个输入序列,并且像 BERT 一样是双向的。但是,它每次生成一个标记的输出序列,以先前生成的标记和编码器提供的输入为条件。
7.4 用于多模态任务的转换器
ViLBERT 和 VisualBERT 等多模态转换器模型旨在处理多种类型的输入数据,通常是文本和图像。它们通过使用双流网络来扩展转换器架构,这些网络在融合信息之前分别处理视觉和文本输入。这种设计使模型能够学习跨模态表示。例如,ViLBERT 使用协同注意力转换器层来实现单独的流交互。这对于理解文本和图像之间的关系至关重要,例如视觉问答任务。
7.5 视觉转换器
视觉变换器 (ViT) 将变换器结构重新用于图像分类任务。它们不是将图像处理为像素网格,而是将图像数据视为一系列固定大小的补丁,类似于句子中单词的处理方式。每个补丁都经过展平、线性嵌入,然后由标准转换器编码器按顺序处理。添加位置嵌入是为了维护空间信息。这种全局自注意力的使用使模型能够捕获任何一对补丁之间的关系,无论它们的位置如何。
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM Agent应用开发
- 区块链应用开发
目前主攻市级软件项目设计、构建服务全社会的应用系统。
参考:
- 编程严选网
这篇关于一文看懂AI的 Transformer 架构!的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-25探索随机贪心算法:从入门到初级应用
- 2024-12-25树形模型进阶:从入门到初级应用教程
- 2024-12-25搜索算法进阶:新手入门教程
- 2024-12-25算法高级进阶:新手与初级用户指南
- 2024-12-25随机贪心算法进阶:初学者的详细指南
- 2024-12-25贪心算法进阶:从入门到实践
- 2024-12-25线性模型进阶:初学者的全面指南
- 2024-12-25朴素贪心算法教程:初学者指南
- 2024-12-25树形模型教程:从零开始的图形建模入门指南
- 2024-12-25搜索算法教程:初学者必备指南



