Kafka事务实现原理
2024/9/1 23:02:46

本文主要是介绍Kafka事务实现原理,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
1 Kafka的事务 V.S RocketMQ
RocketMQ事务主要解决问题:确保执行本地事务和发消息这俩操作都成功/失败。RocketMQ还有事务反查机制兜底,更提高事务执行的成功率和数据一致性。
而Kafka事务,是为确保在一个事务中发送的多条消息,要么都成功,要么都失败。
这里的多条消息不一定在同一个topic和partition,可以是发往多个topic和partition的消息。当然,你可在Kafka事务执行过程中,加入本地事务,来实现和RocketMQ事务类似效果,但Kafka没有事务反查机制。
Kafka这种事务机制,单独使用场景不多。更多是配合Kafka幂等机制,实现Kafka的Exactly Once语义。这里Exactly Once和一般MQ服务水平的Exactly Once不同!
1.1 Exactly Once
一般MQ服务水平中的,指消息从Pro发送到Broker,Con再从Broker拉消息消费。这过程中,确保每条消息恰好传输一次,不重复、不丢弃。
1.2 At Least Once
包括Kafka在内的几个常见MQ,都只能做到At Least Once(至少一次),即保证消息不丢,但可能重复,达不到Exactly Once。
2 Kafka的Exactly Once
使用场景:解决流计算中,用Kafka作数据源,并将计算结果保存到Kafka。数据从Kafka的某topic中消费,在计算集群中计算,再把计算结果保存在Kafka的其他topic。
这样的过程中,保证每条消息都被恰好计算一次,确保计算结果正确。
2.1 案例
将所有订单消息保存在Kafka主题Order,在Flink集群中运行一个计算任务,统计每分钟的订单收入,然后把结果保存在另一个Kafka主题Income。
要保证计算结果准确,就要确保无论Kafka集群 or Flink集群中任何节点故障,每条消息都只能被计算一次,不能重复计算,否则计算结果就错。很重要的限制条件:数据须来自Kafka且计算结果都保存到Kafka,才可应用到Kafka的Excactly Once机制。
所以Kafka的Exactly Once是为解决在“读数据-计算-保存结果”的计算过程中,数据不重也不丢,并非一般MQ消息生产消费过程中的Exactly Once。
3 Kafka的事务实现
实现原理和RocketMQ事务差不多,都基于两阶段提交。为解决分布式事务,Kafka引入
3.1 事务协调者
在服务端协调整个事务。非独立进程,而是Broker进程的一部分,协调者和分区一样通过选举保证HA。
类似RocketMQ,Kafka集群也有一个特殊的用于记录事务日志的topic,该事务日志topic的实现和普通topic一样,里面记录数据类似“开启事务”“提交事务”这样的事务日志。日志topic同样也包含很多分区。
Kafka集群中,可存在多个协调者,每个协调者负责管理和使用事务日志中的几个分区。就是为能并行执行多个事务,提升性能。
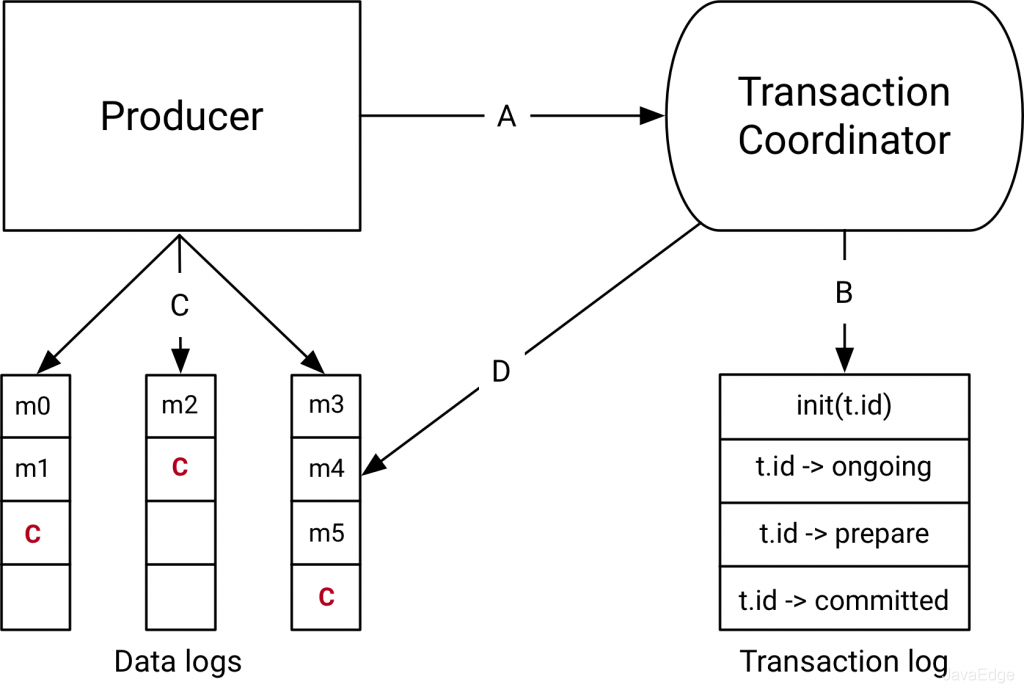
3.2 Kafka事务实现流程
开启事务时,pro给协调者发请求开启事务,协调者在事务日志中记录下事务ID。
然后,pro发消息前,还要给协调者发请求,告知发送的消息属于哪个主题和分区,这个信息也会被协调者记录在事务日志。
接下来,pro就可像发送普通消息一样发事务消息,和RocketMQ不同在于:
- RocketMQ把未提交的事务消息保存在特殊queue
- 而Kafka在处理未提交的事务消息时,和普通消息一样,直接发给Broker,保存在这些消息对应的分区中,Kafka会在客户端的Con中,暂时过滤未提交的事务消息
消息发送完成后,pro给协调者发送提交或回滚事务的请求,由协调者来开始两阶段提交,完成事务:
- 第一阶段,协调者把事务的状态设置为“预提交”,并写入事务日志。至此,事务实际上已经成功,无论接下来发生什么,事务最终都会被提交
- 第二阶段,协调者在事务相关的所有分区中,都会写一条“事务结束”的特殊消息,当Kafka的消费者,也就是client,读到该事务结束的特殊消息后,就可把之前暂时过滤的那些未提交的事务消息,放行给业务代码消费
- 最后,协调者记录最后一条事务日志,标识该事务已结束
3.3 事务执行时序图
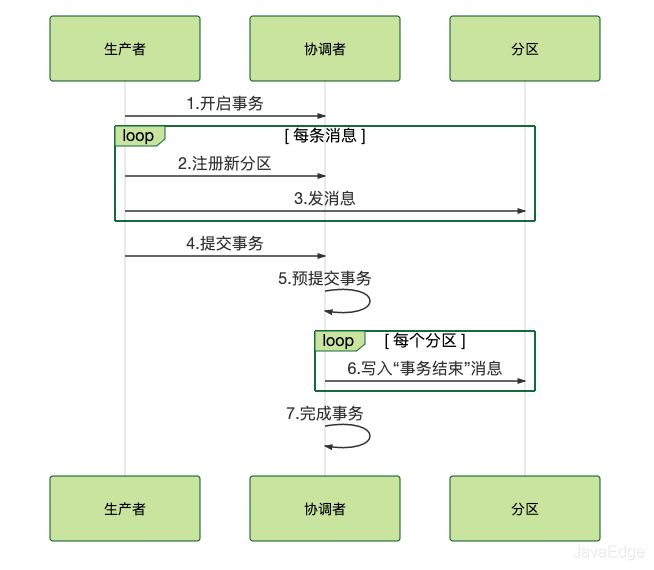
3.4 准备阶段
生产者发消息给协调者开启事务,然后消息发送到每个分区上
3.5 提交阶段
生产者发消息给协调者提交事务,协调者给每个分区发一条“事务结束”的消息,完成分布式事务提交。
4 总结
Kafka基于两阶段提交来实现事务,利用特殊的主题中的队列和分区来记录事务日志。Kafka直接把消息放到对应业务分区中,配合客户端过滤,暂时屏蔽进行中的事务消息。
Kafka的事务则是用于实现它的Exactly Once机制,应用于实时计算的场景中。
参考
- https://www.confluent.io/blog/transactions-apache-kafka/
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM Agent应用开发
- 区块链应用开发
- 大数据开发挖掘经验
- 推荐系统项目
目前主攻市级软件项目设计、构建服务全社会的应用系统。
参考:
- 编程严选网
这篇关于Kafka事务实现原理的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-21MQ-2烟雾传感器详解
- 2024-12-09Kafka消息丢失资料:新手入门指南
- 2024-12-07Kafka消息队列入门:轻松掌握Kafka消息队列
- 2024-12-07Kafka消息队列入门:轻松掌握消息队列基础知识
- 2024-12-07Kafka重复消费入门:轻松掌握Kafka消费的注意事项与实践
- 2024-12-07Kafka重复消费入门教程
- 2024-12-07RabbitMQ入门详解:新手必看的简单教程
- 2024-12-07RabbitMQ入门:新手必读教程
- 2024-12-06Kafka解耦学习入门教程
- 2024-12-06Kafka入门教程:快速上手指南



