prometheus学习笔记之PromQL
2024/10/7 23:03:22

本文主要是介绍prometheus学习笔记之PromQL,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
prometheus学习笔记之PromQL
一、PromQL语句简介
官方文档:https://prometheus.io/docs/prometheus/latest/querying/basics/
Prometheus提供⼀个函数式的表达式语⾔PromQL (Prometheus Query Language),可以使⽤户实时
地查找和聚合时间序列数据,表达式计算结果可以在图表中展示,也可以在Prometheus表达式浏览器
中以表格形式展示,或者作为数据源, 以HTTP API的⽅式提供给外部系统使⽤。
二、PromQL 的数据类型

1.即时向量 (vector)
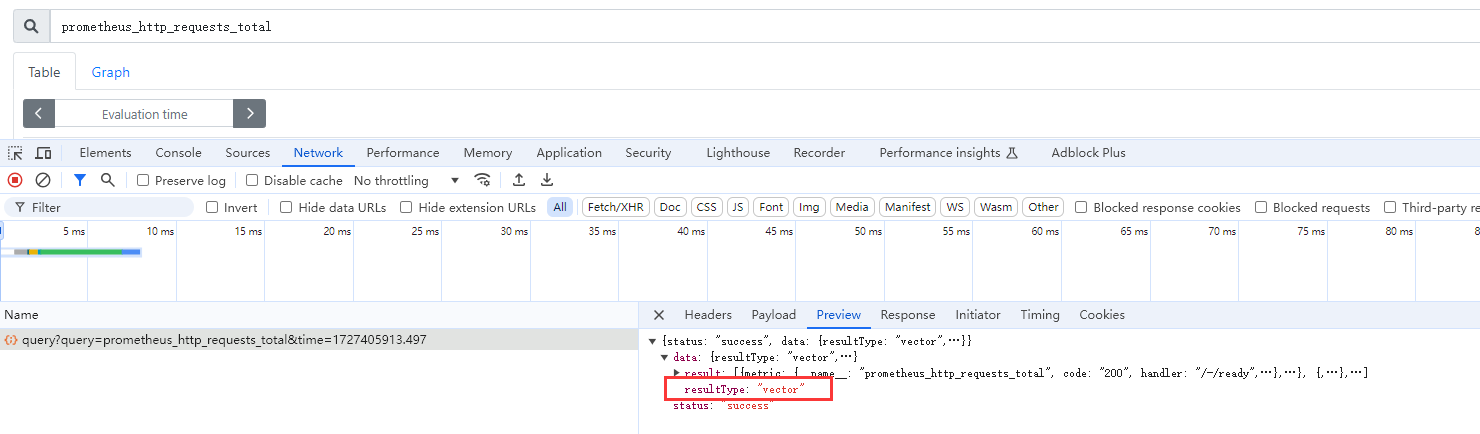
即时向量 (Instant vector): 特定或全部的时间序列集合上,具有相同时间戳的一组样本值,说人话就是一个时间点的结果 ⽐如node_memory_MemFree_bytes查询当前剩余内存就是⼀个瞬时向量,该表达式的返回值中只会包含该时间序列中的最新的⼀个样本值,⽽相应的这样的表达式称之为瞬时向量表达式, 例如:prometheus_http_requests_total

2.区间向量 (matrix)
区间向量 (Range vector): 特定或全部的时间序列集合上,在指定的同一时间范围内的所有样本值 区间向量选择器可以返回 0 个、1 个或多个时间序列上在给定时间范值围内的各自的一组样本。 区间向量选择器的不同之处在于,需要通过在瞬时向量选择器表达式后面添加包含在 [] 里的时长来表达需在时间时序上返回的样本所处的时间范围。 说人话就是一段时间内的结果 时间范围:以当前时间为基准时间点,指向过去一个特定的时间长度;例如,[5m] 是指过去 5 分钟之内。 ◆可用的时间单位有 ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)、w(周)和 y(年) ◆必须使用整数时间,且能够将多个不同级别的单位进行串联组合,以时间单位由大到小为顺序,例如 1h30m,但不能使用 1.5h ⽐如最近⼀天的⽹卡流量趋势图, 例如: prometheus_http_requests_total[5m]
偏移向量选择器
选择器默认都是以当前时间为基准时间,偏移修饰器用来调整基准时间,使其往前偏移一段时间。偏移修饰器紧跟在选择器后面,使用关键字 offset 来指定要偏移的量 例如,prometheus_http_requests_total offset 5m ,表示获取以 prometheus_http_requests_total 为指标名称的所有时间序列在过去 5 分钟之时的即时样本; prometheus_http_requests_total[5m] offset 1d ,表示获取距此刻 1 天时间之前的 5 分钟之内的所有样本偏移向量选择器可以做环比、同比的笔记


3.标量数据 (Scalar)
标量、纯量数据(scalar):是⼀个浮点数类型的数据值,使⽤node_load1获取到时⼀个瞬时向量,但是可⽤使⽤内置函数scalar()将瞬时向量转换为标量,例如: scalar(sum(node_load1))

4.字符串(string)
字符串(string):简单的字符串类型的数据,⽬前未使⽤,(a simple string value; currentlyunused)
三、指标类型
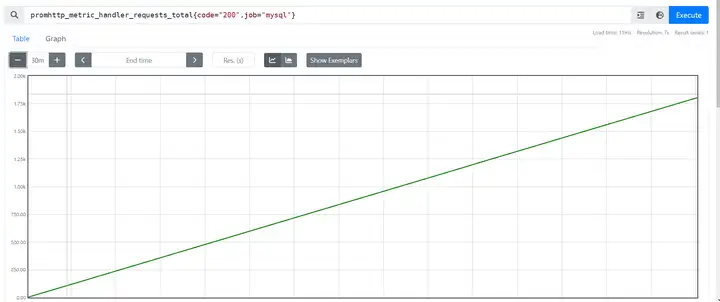
1.Counter
Counter:计数器,Counter类型代表⼀个累积的指标数据,在没有被重置的前提下只增不减,⽐如磁盘I/O总数、 nginx的请求总数、⽹卡流经的报⽂总数等。如下图
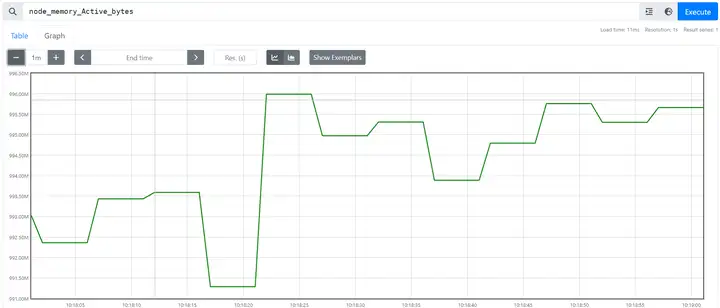
2.Gauge
Gauge类型代表⼀个可以任意变化的指标数据,值可以随时增⾼或减少,如带宽速录、CPU负载、内存利⽤率、 nginx 活动连接数等。如下图
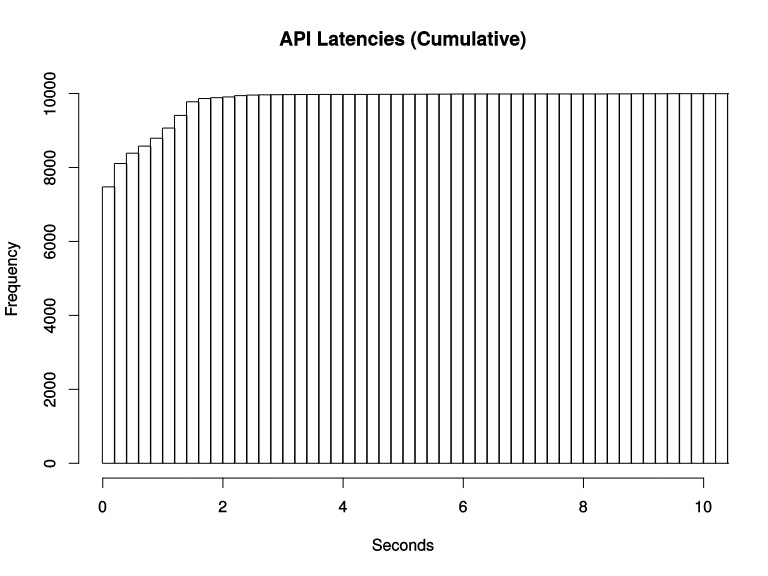
3.Histogram
累积直⽅图, Histogram会在⼀段时间范围内对数据进⾏采样(通常是请求持续时间或响应⼤⼩等),假如每分钟产⽣⼀个当前的活跃连接数,那么⼀天就会产⽣1440个数据,查看数据的每间隔的绘图跨 度为2⼩时,那么2点的柱状图(bucket)会包含0点到2点即两个⼩时的数据,⽽4点的柱状图(bucket)则会包含0点到4点的数据,⽽6点的柱状图(bucket)则会包含0点到6点的数据。
4.Summary
Summary 是一种类似于 Histogram 的指标类型,但它在客户端于一段时间内(默认为 10 分钟)的每个采样点进行统计,计算并存储了分位数数值,Server 端直接抓取相应值即可。
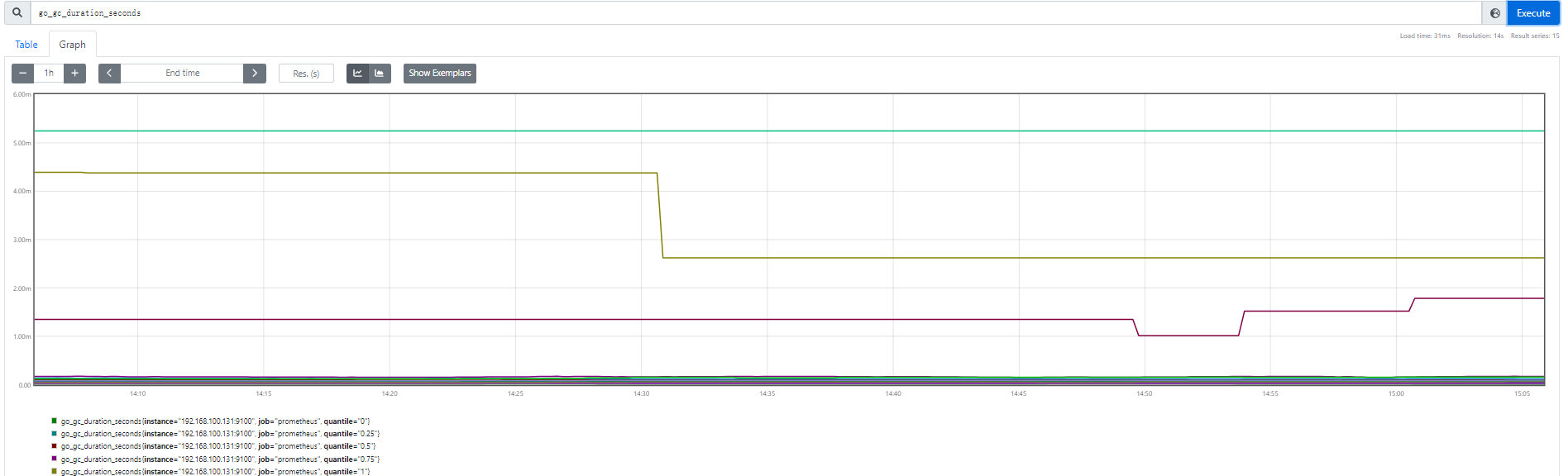
5.学习参考
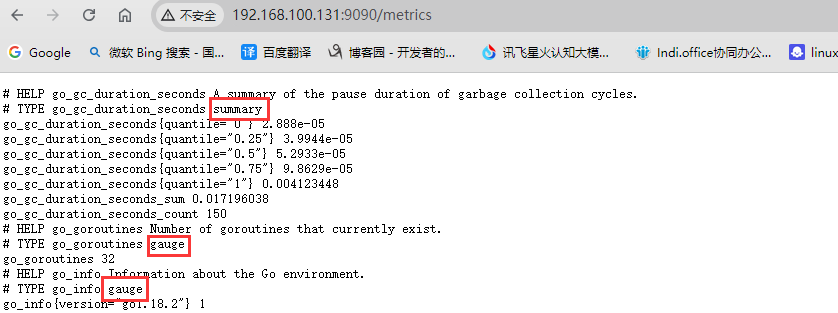
访问prometheus的/metrics接口,通过注释确认数据的类型
四、PromQL-常见指标数据
CPU相关指标:
node_cpu_seconds_total{mode="idle"}:CPU空闲时间(秒)的总和。这是评估CPU使用率的重要指标之一。
node_cpu_seconds_total{mode="system"}、node_cpu_seconds_total{mode="user"}等:分别表示CPU在内核态和用户态的运行时间。
内存相关指标:
node_memory_MemTotal_bytes:内存总量(以字节为单位)。
node_memory_MemFree_bytes:空闲内存大小(以字节为单位)。
node_memory_Buffers_bytes和node_memory_Cached_bytes:分别表示被内核用作缓冲和缓存的内存大小。
node_memory_SwapTotal_bytes和node_memory_SwapFree_bytes:分别表示交换空间的总大小和空闲大小。
磁盘相关指标:
node_filesystem_size_bytes:文件系统的大小(以字节为单位)。
node_filesystem_free_bytes和node_filesystem_avail_bytes:分别表示文件系统的空闲空间和非root用户可用的空间大小。
node_disk_io_now、node_disk_io_time_seconds_total等:与磁盘I/O操作相关的指标,如当前正在进行的I/O操作数以及花费在I/O操作上的总时间。
网络相关指标:
node_network_receive_bytes_total和node_network_transmit_bytes_total:分别表示网络接口接收和发送的总字节数。这些指标对于评估网络流量和带宽使用情况非常重要。
系统负载相关指标:
node_load1、node_load5、node_load15:分别表示系统在过去1分钟、5分钟和15分钟的平均负载。这些指标有助于了解系统的整体忙碌程度和性能表现。
要获取完整的指标列表,可以访问 exporter 的 metrics 端点(通常是 /metrics)
五、PromQL-匹配器
#标签选择器用于定义标签过滤条件,目前支持如下4种匹配操作符:
= :完全相等
!= : 不相等
=~ : 正则表达式匹配
!~ : 正则表达式不匹配
#查询格式<metric name>{<label name>=<label value>, ...}
node_load1{instance="172.31.7.111:9100"}
node_load1{job="promethues-node"}
node_load1{job="promethues-node",instance="172.31.7.111:9100"} #精确匹配
node_load1{job="promethues-node",instance!="172.31.7.111:9100"} #取反
node_load1{instance=~"172.31.7.11.*:9100$"} #包含正则且匹配
node_load1{instance!~"172.31.7.111:9100"} #包含正则且取反
注意事项:
1.匹配到空标签值的标签选择器时,所有未定义该标签的时间序列同样符合条件。例如
prometheus_http_requests_total{handler= ""},则该指标名称上所有未使用该标签(handler)的时间序列也符合条件
2.正则表达式将执行完全锚定机制,它需要匹配指定的标签的整个值
3.向量选择器至少要包含一个指标名称,或者至少有一个不会匹配到空字符串的标签选择器,例如
{ job=""} 为非法的向量选择器
4.使用 __name__ 做为标签名称,还能够对指标名称进行过滤。例如
{__name__=~".*http_requests_total"} 能够匹配所有以 http_requests_total 为后缀的所有指标
六、PromQL-时间范围
s - 秒
m - 分钟
h - ⼩时
d - 天
w - 周
y - 年
#瞬时向量表达式,选择当前最新的数据
node_memory_MemTotal_bytes{}
#区间向量表达式,选择以当前时间为基准,查询所有节点node_memory_MemTotal_bytes指标5分钟内
的数据
node_memory_MemTotal_bytes{}[5m]
#区间向量表达式,选择以当前时间为基准,查询指定节点node_memory_MemTotal_bytes指标5分钟内
的数据
node_memory_MemTotal_bytes{instance="172.31.7.111:9100"}[5m]
七、PromQL-运算符
+ 加法
- 减法
* 乘法
/ 除法
% 模
^ 幂等
node_memory_MemFree_bytes/1024/1024 #将内存进⾏单位从字节转⾏为兆
node_disk_read_bytes_total{device="sda"} +
node_disk_written_bytes_total{device="sda"} #计算磁盘读写数据量
八、PromQL-聚合运算符
#Prometheus 内置提供如下聚合函数,也称为聚合运算符:
●sum():对样本值求和
●min() :求取样本值中的最小者
●max() :求取样本值中的最大者
●avg() :对样本值求平均值
●count() :对分组内的时间序列进行数量统计
●stddev() :对样本值求标准差,以帮助用户了解数据的波动大小(或称之为波动程度),如CPU、内存、流量波动
●stdvar() :对样本值求方差,它是求取标准差过程中的中间状态
●topk() :逆序返回分组内的样本值最大的前 k 个时间序列及其值,即最大的 k 个样本值
●bottomk() :顺序返回分组内的样本值最小的前 k 个时间序列及其值,即最小的 k 个样本值
●quantile() :分位数,用于评估数据的分布状态,该函数会返回分组内指定的分位数的值,即数值落在小于等于指定的分位区间的比例
●count_values() :对分组内的时间序列的样本值进行数量统计,即等于某值的样本个数
●rate():函数是专⻔搭配counter数据类型使⽤函数,功能是取counter数据类型在这个时间段中平均每秒的增量平均数,适合⽤于计算数据相对平稳的数据
●irate ():专⻔搭配counter数据类型使⽤函数, irate获取的是指定时间范围内最近的两个数据来计算数据的速率,适合计算数据变化⽐较⼤的数据,显示的数据相对⽐较准确
●abs():返回指标数据的值
●absent():如果监指标有数据就返回空,如果监控项没有数据就返回1
计算每个节点的最⼤的流量值: max(node_network_receive_bytes_total) by (instance) 计算每个节点最近五分钟每个device的最⼤流量 max(rate(node_network_receive_bytes_total[5m])) by (device) 最近总共请求数 sum(prometheus_http_requests_total) 统计返回值的条数 count(node_os_version)取从⼤到⼩的前6个 topk(6, prometheus_http_requests_total) 样本值排名最⼩的N个数据 bottomk(6, prometheus_http_requests_total) rate(prometheus_http_requests_total[5m]) rate(node_network_receive_bytes_total[5m]) irate(prometheus_http_requests_total[5m]) irate(node_network_receive_bytes_total[5m])
abs(sum(prometheus_http_requests_total{handler="/metrics"}))
absent(sum(prometheus_http_requests_total{handler="/metrics"})) 如果有值则返回空,否则1
九、PromQL-聚合表达式
PromQL 中的聚合操作语法格式可采用如下面两种格式之一:
<聚合函数>(向量表达式) by|without (标签) <聚合函数> by|without (标签) (向量表达式) by :仅使用by子句中指定的标签进行聚合,结果向量中出现但未被 by 指定的标签则会被忽略;为了保留上下文信息,使用 by 子句时需要显式指定其结果中原本出现的 job、instance 等一类的标签。 without:从结果向量中删除由 without 指定的标签,未指定的那部分标签则用作分组标准示例:
(1)每台主机 CPU 在最近 5 分钟内的平均使用率
(1 - avg(rate(node_cpu_seconds_total{mode=“idle”}[5m])) by (instance)) * 100
(2)查询 1 分钟的 load average 的时间序列是否超过主机 CPU 数量 2 倍
node_load1 > on (instance) 2 * count (node_cpu_seconds_total{mode=“idle”}) by (instance)
(3)计算主机内存使用率
可用内存空间:空闲内存、buffer、cache 指标之和
node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes
已用内存空间:总内存空间减去可用空间
node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)
使用率:已用空间除以总空间
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100
(4)计算所有 node 节点所有容器总计内存:
sum by (instance) (container_memory_usage_bytes{instance=~“node*”})/1024/1024/1024
(5)计算 node01 节点最近 1m 所有容器 cpu 使用率:
sum (rate(container_cpu_usage_seconds_total{instance=“node01”}[1m])) / sum (machine_cpu_cores{instance=“node01”}) * 100
#container_cpu_usage_seconds_total 代表容器占用CPU的时间总和
(6)计算最近 5m 每个容器 cpu 使用情况变化率
sum (rate(container_cpu_usage_seconds_total[5m])) by (container_name)
(7)查询 K8S 集群中最近 1m 每个 Pod 的 CPU 使用情况变化率
sum (rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m])) by (pod_name)
#由于查询到的数据都是容器相关的,所以最好按照 Pod 分组聚合
(8)查询10分钟内每个api接口的状态个数
sum without(job,instance) (rate(prometheus_http_requests_total[10m])) #等同于 sun by(code,handler)
参考文档:https://prometheus.io/docs/prometheus/latest/querying/basics/
十、时间聚合函数
avg_over_time(range-vector):指定区间内所有点的平均值。 min_over_time(range-vector):指定区间内所有点的最小值。 max_over_time(range-vector):指定区间内所有点的最大值。 sum_over_time(range-vector):指定区间内所有值的总和。sum_over_time(prometheus_http_requests_total[5m]) #每个接口5分钟内请求的总和 count_over_time(range-vector):指定区间内所有值的计数。 quantile_over_time(scalar, range-vector):指定区间内的值的 φ 分位数(0 ≤ φ ≤ 1)。 stddev_over_time(range-vector):指定区间内值的总体标准差。 stdvar_over_time(range-vector):指定区间内值的总体标准方差。 last_over_time(range-vector):指定间隔内最近的点值。 present_over_time(range-vector):指定间隔内任意系列的值 1。
参考文档:https://prometheus.io/docs/prometheus/latest/querying/functions/
写在最后
编程精选网(www.codehuber.com),程序员的终身学习网站已上线!
如果这篇【文章】有帮助到你,希望可以给【JavaGPT】点个赞👍,创作不易,如果有对【后端技术】、【前端领域】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【JavaGPT】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💝💝💝!
本文由博客一文多发平台 OpenWrite 发布!
这篇关于prometheus学习笔记之PromQL的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-21MQ-2烟雾传感器详解
- 2024-12-09Kafka消息丢失资料:新手入门指南
- 2024-12-07Kafka消息队列入门:轻松掌握Kafka消息队列
- 2024-12-07Kafka消息队列入门:轻松掌握消息队列基础知识
- 2024-12-07Kafka重复消费入门:轻松掌握Kafka消费的注意事项与实践
- 2024-12-07Kafka重复消费入门教程
- 2024-12-07RabbitMQ入门详解:新手必看的简单教程
- 2024-12-07RabbitMQ入门:新手必读教程
- 2024-12-06Kafka解耦学习入门教程
- 2024-12-06Kafka入门教程:快速上手指南



