GPT-SoVITS:一种用于语音合成的模型,支持零次学习和可定制的微调。
2024/10/12 21:02:52

本文主要是介绍GPT-SoVITS:一种用于语音合成的模型,支持零次学习和可定制的微调。,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
这是「GPT-SoVITS」的入门,这是一款可以与ailia SDK一起使用的机器学习模型。你可以轻松使用此模型通过ailia SDK以及其他现成的ailia MODELS来开发AI应用。
概览
GPT-SoVITS 是一个于2024年2月18日发布的语音合成模型,它支持使用参考音频进行无需训练的语音合成,并可以通过调整来提升性能。

GPT-SoVITS : 项目地址为 https://github.com/RVC-Boss/GPT-SoVITS,点此链接。
GitHub — RVC-Boss/GPT-SoVITS: 仅需1分钟的声音数据就能训练出一个好的TTS模型!(少样本声音克隆技术) — RVC-Boss/GPT-SoVITS只需输入5秒的音频样本,快速生成语音。
用仅1分钟的训练数据来优化模型,让声音更相似和更逼真。
目前支持在训练数据的不同语言上进行推理,包括英语、日语和中文。
提供了一体化的工具用于语音和伴奏分离、自动分割训练数据、中文自动语音识别(ASR)以及文本注释,支持创建训练数据集和构建_GPT/SoVITS_模型。
GPT-SoVITS, 是基于最新的语音合成和变声器模型的研究。
VITS 是一个端到端的语音合成模型,于2021年1月发布。传统的端到端语音合成模型的性能通常低于将文本转换为中间表示的两阶段TTS系统。VITS 通过引入Flow模型(流模型),采用归一化流去除说话人特征,并使用对抗训练过程来提高语音合成的效果。

来源链接:https://arxiv.org/abs/2106.06103
VITS2 是在 2023 年 7 月发布的端到端语音合成模型,其中一位开发人员 Jungil Kong 是模型的第二作者。VITS2 用 Transformer Flow 替代了 VITS 中的 Flow 模型。传统的端到端语音合成模型面临着自然度、计算效率和对音素转换的依赖等问题。VITS2 在 VITS 的基础上改进了架构和训练机制,减少了对音素转换的依赖。
Bert-VITS2 是一个端到端语音合成模型,于2023年9月发布,它用多语言BERT替换了VITS2的文本编码器部分。

来源: https://github.com/fishaudio/Bert-VITS2
SoVITS (SoftVC VITS) 是2023年7月发布的一个模型,它用来自 SoftVC 的 Content Encoder 替换了 VITS 的 Text Encoder,从而实现了类似 RVC 的语音到语音合成,而不是文本到语音的转换。

网址是 https://github.com/svc-develop-team/so-vits-svc 来自 https://github.com/svc-develop-team/so-vits-svc
_GPT-SoVITS_ 是基于一系列改进,将 VITS 的高质量语音合成与 SoVITS 的零样本语音适配能力结合。
GPT-SoVITS 是一个现代基于标记的语音合成模型。它先生成声学标记,再把它们变回波形,从而得到合成的语音波形。
GPT-SoVITS 包含了以下模型:
- cnhubert :将输入波形转换为特征向量。
- t2s_encoder :从输入文本和参考文本生成声学令牌,同时利用特征向量。
- t2s_decoder :将生成的声学令牌转化为波形。
- vits :把声学令牌转换成声音。
GPT-SoVITS的输入如下所示:
- text_seq : 需要被合成语音的文本。
- ref_seq : 参考音频里的文本。
- ref_audio : 参考音频的波形。
将 text_seq 和 ref_seq 使用 g2p 转换为音素后,会在 symbols.py 中被转换为 token 序列。对于日语,g2p 转换不使用音调标记。对于中文,除了使用 g2p 转换外,还会使用 BERT 嵌入(ref_bert 和 text_bert)。而对于日语和英语,这些 BERT 嵌入不会使用,会被填充为零。
ref_audio 在末尾加上了 0.3 秒的静音,然后被转换成称为 ssl_content 的特征向量使用 cnhubert。
The t2s_encoder 接受 ref_seq 、text_seq 和 ssl_content 作为主要输入,并生成声学 tokens。
The t2s_decoder 将这些声学令牌作为输入,并使用序列到序列模型输出后续的声学令牌。此输出对应于合成的文本的声学令牌。共有 1025 种标记类型,其中 1024 代表 EOS(序列结束)。采用 top-k 和 top-p 采样方法逐个输出标记,直到遇到 EOS 令牌时为止。
最后,这些声学令牌(acoustic tokens)被输入到 vits,生成语音的波形。
在GPT-SoVITS中,日文文本使用pyopenjtalk中的g2p转换成音位,英文文本则使用g2p_en进行转换。
对于日语,文本ax株式会社ではAIの実用化のための技術を開発しています。对应的音素是e i e klu k u s u k a b u sh i k i g a i s h a d e w a e e a i no j i ts u y o o k a no t a m e no g i j u ts u o k a i h a t s u sh i t e i m a s u.,与通常的g2p不同,这里的标点符号也被保留了下来。
对于英语,输入 “Hello world. We are testing speech synthesis.” 会生成音素 “HH AH0 L OW1 W ER1 L D . W IY1 AA1 R T EH1 S T IH0 NG S P IY1 CH S IH1 N TH AH0 S AH0 S .” 在 g2p_en 中,单词会先使用 cmudict 字典转换为音素的过程,对于不在字典中的单词,则通过神经网络来进行音素转换。
要进行零样本推理,请在WebUI中选择1-GPT-SoVITS-TTS,进入1C-inference标签页。勾选打开TTS推理WEBUI,稍等片刻,一个新的窗口就会自动打开。

输入参考音频文件、参考音频文本和推理文本,然后点击或按下 “开始生成”。在零样本模式中,推理文本的合成的声音将使用参考音频的声音特质。

如果声音具有明显的特征,即使在零样本推理的情况下,也能得到相当不错的语音效果。要得到更高的准确度,则需要进行微调。
首先,准备一个数据集。在预处理部分的“0-获取数据集”工具中,指定音频文件的路径,然后分割音频。

首先,使用ASR工具进行语音识别,生成参考文本。如果你选择Faster Whisper,也就是可以指定语音识别的语言。

输出列表文件的格式如下:
TTS标注文件.list文件格式:
vocal_path|speaker_name|language|text
语言字典: - 'zh': 中文 - 'ja': 日语 - 'en': 英语 示例:
D:\GPT-SoVITS\xxx/xxx.wav|xxx|en|我喜欢玩原神。
在创建数据集之后,在标签页 `1-GPT-SOVITS-TTS`,子标签页 `1A-数据集格式化` 中格式化训练数据为。指定文本注释文件的位置和训练数据音频文件的目录,然后点击 `“一键格式化开始”` 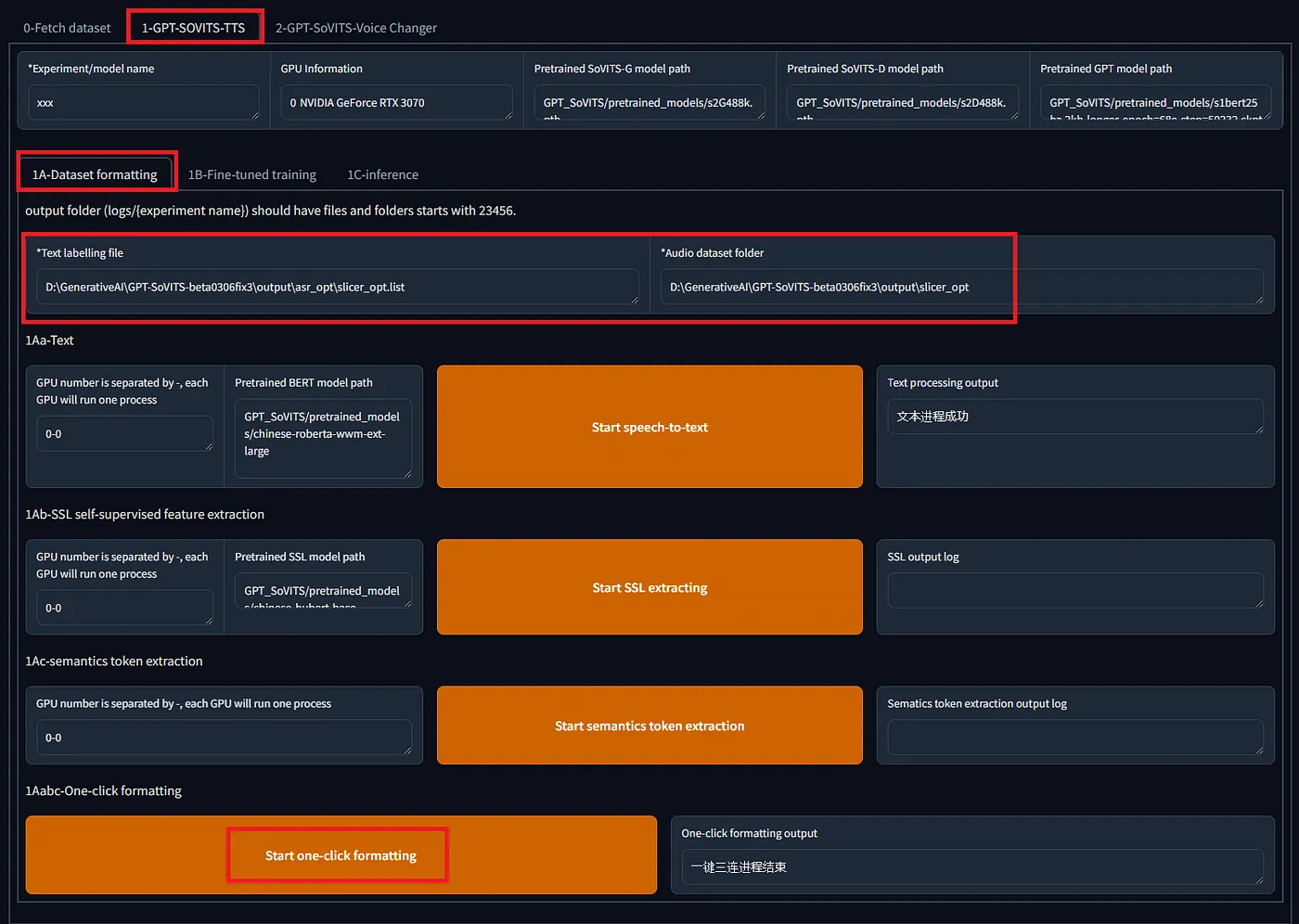 在下一个标签页 `1B-Fine-tuned training` 中,训练 SoVITS 和 GPT 两个模型。 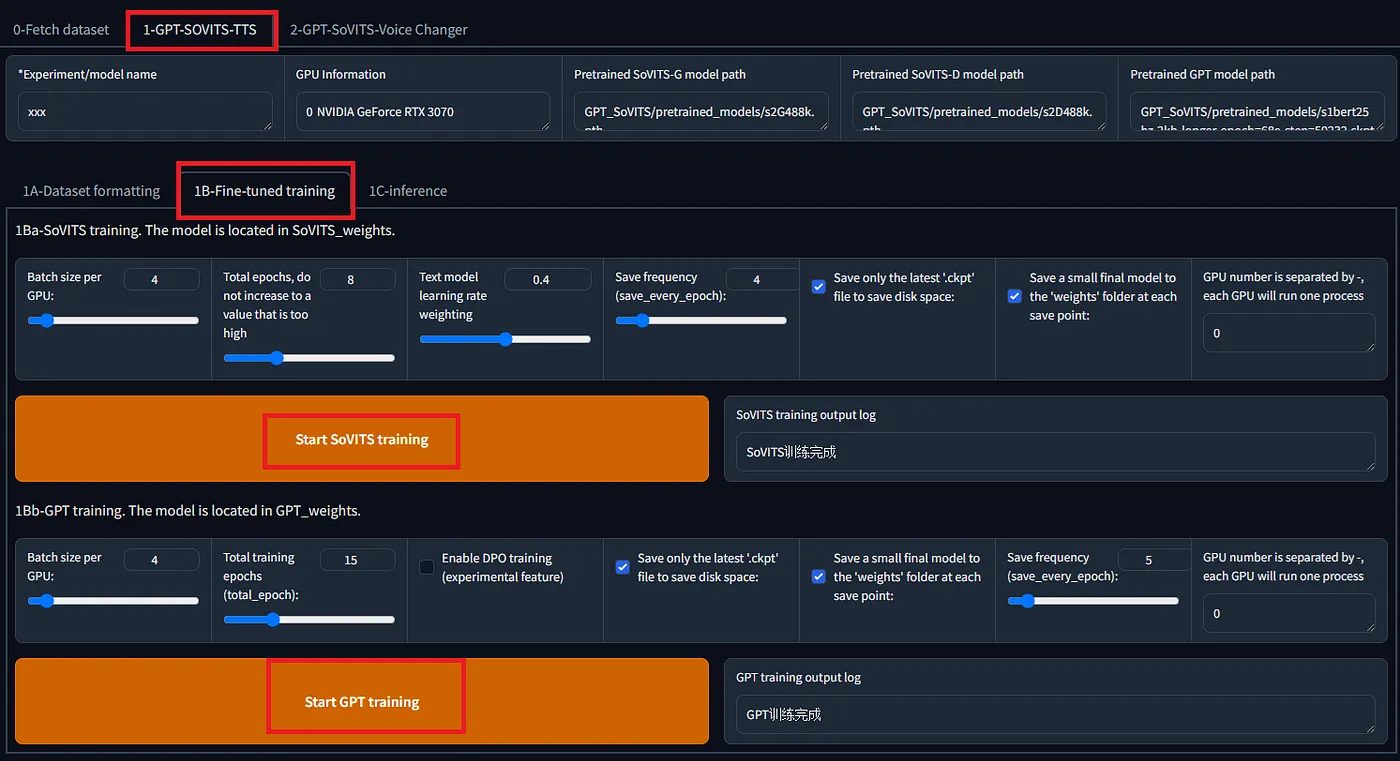 使用 RTX 3080 训练大约 1 分钟的音频,SoVITS 在 8 轮次时大约 78 秒,而 GPT 在 15 轮次时大约 60 秒。这些训练完成的模型的大小分别为 GPT 151,453 KB 和 SoVITS 82,942 KB。 训练完成后,像之前那样打开WebUI推理界面,选择我们刚刚训练的新模型,进行语音合成操作。默认温度设置为1.0,但将其调整到大约0.5似乎能提供更多的稳定性,从而获得更佳的合成效果。 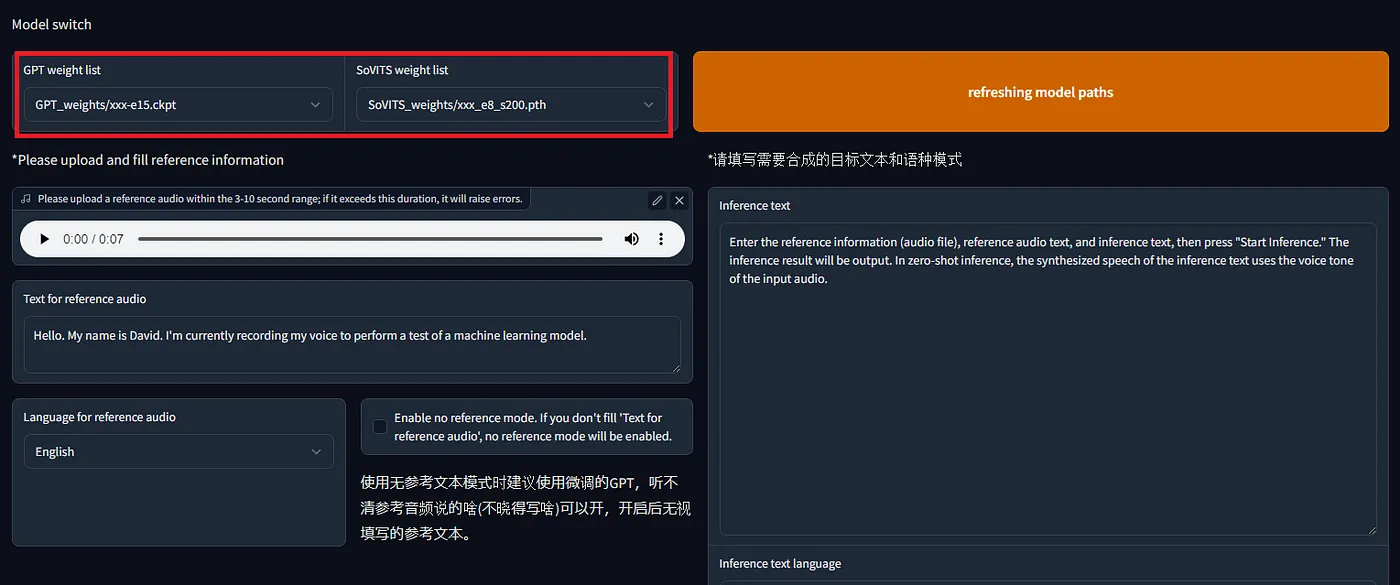 # 转成ONNX(注意:ONNX是指一种模型格式) 导出到ONNX的代码已经包含在官方仓库内。然而,此代码不包括导出到**cnhubert**和推理部分的代码,因此需要进行实现。 ## [GPT-SoVITS/GPT_SoVITS/onnx_export.py 在 main 分支页面 · RVC-Boss/GPT-SoVITS 1分钟的语音数据也可以用来训练一个好的TTS模型!(少量样本语音克隆模型)…github.com](https://github.com/RVC-Boss/GPT-SoVITS/blob/main/GPT_SoVITS/onnx_export.py?source=post_page-----e4c72cd75d87--------------------------------) 此外,与torch版本相比,ONNX版本的输出音频的准确度较低。经过调查发现,以下差异需要实现: 1. 将 `exp` 参数引入 `multinomial_sample_one_no_sync` 函数的采样过程中。 2. 修正 `SinePositionalEmbedding` 中的 `pe` 参数。 3. 在 `vq_decode` 中增加 `noise_scale` 参数。 4. 移除 `first_stage_decode` 中的 EOS 标记。 另外,由于topK和topP内嵌在模型里且无法从外部控制,因此将它们加入输入会很方便。 该包含这些修改的仓库可在下方链接访问。 ## [GitHub — axinc-ai/GPT-SoVITS: 即使只有1分钟的语音资料,也可以训练出一个很好的TTS模型!(仅需少量语音即可完成克隆) — https://github.com/axinc-ai/GPT-SoVITS?source=post_page-----e4c72cd75d87--------------------------------](https://github.com/axinc-ai/GPT-SoVITS?source=post_page-----e4c72cd75d87--------------------------------) 另外,这是链接到官方仓库的拉取请求。 ## [kyakuno 提交了改进ONNX和torch之间一致性的请求 · Pull Request #835 · RVC-Boss/GPT-SoVITS 在使用包含的脚本过程中……github.com](https://github.com/RVC-Boss/GPT-SoVITS/pull/835?source=post_page-----e4c72cd75d87--------------------------------) # 日语中的声调(音高变化) 目前,日语中使用的是不带声调标记的g2p(音素到音高转换),这有时会让日语听起来有点奇怪的音调。正在考虑在以后引入声调标记,因此未来可能会有所改善。 ## [建议增加对日语韵律音高的支持以提高语音合成质量 · Issue #326 · RVC-Boss/GPT-SoVITS 当前项目的日语语音合成前端部分直接使用pyopenjtalk的g2p函数来获取分词结果,然后将其直接输入模型。更让人惊讶的是,当前的GPT模型在没有音高标注的情况下,依靠自身学习能力,已经实现了对音高的建模,并已经取得了不错的韵律效果。…github.com](https://github.com/RVC-Boss/GPT-SoVITS/issues/326?source=post_page-----e4c72cd75d87--------------------------------) # 在alia SDK中的使用方法 _GPT-SoVITS_ 可以与 ailia SDK 1.4.0 或更高版本配合使用。以下命令会基于 `reference_audio_captured_by_ax.wav` 进行语音合成。
python3 gpt-sovits.py -i "正在对语音合成进行测试。" --ref_audio reference_audio_captured_by_ax.wav --ref_text "我们不得不从马来西亚进口水。"
## [ailia-models/音频处理/gpt-sovits at master · axinc-ai/ailia-models - 预训练、最先进的AI模型集合(专为ailia SDK开发)](https://github.com/axinc-ai/ailia-models/tree/master/audio_processing/gpt-sovits?source=post_page-----e4c72cd75d87--------------------------------) 在主分支 GitHub 你也可以在 Google Colab 中,把这段代码跑起来。 ## [Hello GPT-SoVITS — Google Colab](https://colab.research.google.com/github/axinc-ai/ailia-models/blob/master/audio_processing/gpt-sovits/colab.ipynb?source=post_page-----e4c72cd75d87--------------------------------) # 最后 通过使用GPT-SoVITS,我们确认其合成的日语语音质量高于我们在此文(https://medium.com/axinc-ai/vall-e-x-zero-shot-text-to-speech-cross-lingual-model-9686ada19131)中提到的VALLE-X。微调所需时间比预期短,使其具有实用性。此外,推断速度快,甚至可以在CPU上运行,因此,预计它将在未来得到广泛应用。 # 故障排除 如果您在获取语义令牌时遇到错误提示 `SystemError: 初始化过程 of _internal failed without raising an exception`,请更新 Numba。 请确保您已经安装了Python和pip,在命令行中运行以下命令来更新或安装numba:
pip install -U numba
## 如何解决“SystemError: _internal 初始化失败而没有引发异常”的问题?我在尝试导入 Top2Vec 包进行 NLP 主题模型分析,但是即使升级了 pip 和 numpy,仍然出现该问题。...[Stack Overflow](https://stackoverflow.com/questions/74947992/how-to-remove-the-error-systemerror-initialization-of-internal-failed-without?source=post_page-----e4c72cd75d87--------------------------------) [`ax Inc.`](https://axinc.jp/en/) 推出了 [`ailia SDK`](https://ailia.jp/en/),这是一款基于 GPU 的跨平台快速推断 SDK。 ax Inc. (ax Inc. 提供咨询、模型创建、AI 应用程序开发和 SDK 开发服务。) 提供多种服务,包括咨询、模型创建、AI 应用程序开发以及软件开发工具包 (SDK) 开发。如有任何查询,欢迎随时联系我们 [联系我们](https://axinc.jp/en/)。
这篇关于GPT-SoVITS:一种用于语音合成的模型,支持零次学习和可定制的微调。的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-22程序员出海做 AI 工具:如何用 similarweb 找到最佳流量渠道?
- 2024-12-20自建AI入门:生成模型介绍——GAN和VAE浅析
- 2024-12-20游戏引擎的进化史——从手工编码到超真实画面和人工智能
- 2024-12-20利用大型语言模型构建文本中的知识图谱:从文本到结构化数据的转换指南
- 2024-12-20揭秘百年人工智能:从深度学习到可解释AI
- 2024-12-20复杂RAG(检索增强生成)的入门介绍
- 2024-12-20基于大型语言模型的积木堆叠任务研究
- 2024-12-20从原型到生产:提升大型语言模型准确性的实战经验
- 2024-12-20啥是大模型1
- 2024-12-20英特尔的 Lunar Lake 计划:一场未竟的承诺



