在您的Mac上运行本地语言模型的最详尽指南
2024/10/21 21:03:31

本文主要是介绍在您的Mac上运行本地语言模型的最详尽指南,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
大家好!想在你的Mac上运行LLM(大型语言模型)吗?这里有份指南!我们将介绍三个强大的工具,在你的Mac上运行LLM,不需要依赖云服务或昂贵的订阅。
无论你是编程新手还是有经验的开发者,你都能很快上手。这是评估不同开源模型,或者在自己的机器上搭建环境编写AI应用程序的好方法。
我们将从易于使用的过渡到需要编程的解决方案。
我们正在使用的一些产品:- LM Studio:人人皆宜的用户友好型AI平台
- Ollama:高效且开发友好型
- Hugging Face Transformers:高级模型库
如果你想看这个教程的视频版本,就在这里!
那咱们就开始吧。
1. LM工作室:人人都能用的友好型AI这里有一张图片的链接:图片链接
LM Studio 是初学者和专家的理想起点。它提供了一个非常直观的界面,用于探索和使用各种AI模型,非常方便。
开始使用LM Studio之旅
- 访问lmstudio.ai并下载适用于您 Mac 的版本。
- 将下载的文件拖拽到您的 Applications 文件夹中,以此来安装 LM Studio。
- 启动 LM Studio 并根据提示进行安全设置。
 描述图片内容或添加说明。
描述图片内容或添加说明。
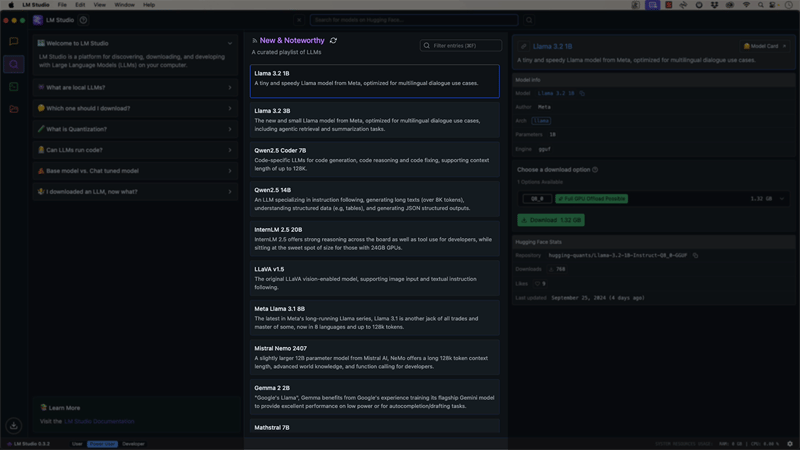
探索模型
在主页中,点击“加载一个模型”或从“新亮点”列表中选择模型。
](https://imgapi.imooc.com/6715b12e09ad8e8e08000450.jpg "在您的Mac上运行本地语言模型的最详尽指南_")
- 我们将在本教程中使用 "llama2 3B" 模型。点击以下载它。
- 下载后,点击 "加载模型" 来激活它。

如下图所示:这是一张示例图片。
使用聊天界面功能
- 加载好模型后,你就可以在聊天界面开始与它互动了。
- 试着问个问题,比如“告诉我一个关于Python的搞笑笑话。”

- 注意模型的反应和性能指标(如每秒token数和上下文使用情况)。
这是一张图片,点击这里查看: 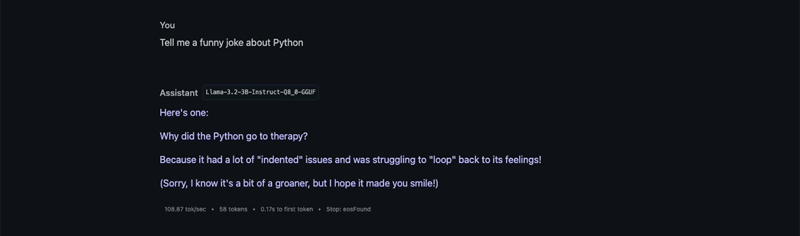](https://imgapi.imooc.com/6715b1300932036e08000236.jpg "在您的Mac上运行本地语言模型的最详尽指南_")
利用API服务器
LM Studio 还提供了一个兼容 OpenAI 的 API 服务器,便于与您的应用程序集成。
- 点击左侧边栏中的服务器图标。
-
点击“启动服务器程序”按钮启动服务器程序。

复制提供的服务器地址(通常为
http://localhost:1234)。

你可以看到一系列可用的端点:
GET http://localhost:1234/v1/models
POST http://localhost:1234/v1/chat/completions
POST http://localhost:1234/v1/completions
POST http://localhost:1234/v1/embeddings
切换到全屏 / 退出全屏
你现在可以使用这个地址,通过Postman这样的工具或你自己的代码向模型发送请求。这里有一个使用Postman的简单示例:
- 发起一个新的POST请求到
http://localhost:1234/v1/chat/completions。 - 将请求体设置为如下JSON格式:
{
// 内容根据具体需求定义
}
{
"model": "lmstudio-community/Qwen2.5-14B-Instruct-GGUF/Qwen2.5-14B-Instruct-Q4_K_M.gguf",
"messages": [
{
"role": "system",
"content": "你是一个乐于助人的搞笑高手,对Python非常了解"
},
{
"role": "user",
"content": "给我讲一个关于Python的搞笑笑话。"
}
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "joke_response",
"strict": "true",
"schema": {
"type": "object",
"properties": {
"joke": {
"type": "string"
}
},
"required": [
"joke"
]
}
}
},
"temperature": 0.7,
"max_tokens": 50,
"stream": false
}
全屏显示,退出全屏
发送请求,然后观察模型的回复。
LM Studio非常适合快速测试各种模型,并以最少的设置将它们集成到您的项目中。
2. Ollama:既高效又便于开发者使用:Ollama(奥拉马)是一个轻便且功能强大的工具,非常适合喜欢通过命令行操作的开发者,用于部署大语言模型 (LLM)。
安装OLLAMA:

- 访问Ollama网站,然后下载Mac版。
- 将下载的文件拖放到您的 Applications 文件夹中以安装 Ollama。
- 启动 Ollama 并按提示处理安全问题。
从终端使用 Ollama
- 打开终端窗口,例如使用快捷键Ctrl+Alt+T。
- 运行
Ollama list来查看可用的模型。
点击此处查看图片
-
要下载并运行模型程序,可以使用:
Ollama run <model-name>
比如:Ollama run qwen2.5-14b,其中<model-name>是模型的具体名称,如qwen2.5-14b。模型加载完成后,你就可以直接在终端里和它互动。
查看图片:点击这里
奥拉命令和功能介绍
- 你可以使用
/?查看当前模型会话中的可用命令。 - 你可以使用
/bye结束模型会话。 - 你可以使用
--verbose选项来详细运行模型。
用Ollama的API
Ollama 还提供了一个 API,以便与您的应用程序集成:
- 确保 Ollama 正在运行(您会在菜单栏中看到它的图标)。
- 向
http://localhost:11434/api/generate发送 POST 请求到。
比如使用 Postman 的时候,可以这样做:
{
"model": "qwen2.5:14b",
"prompt": "讲一个关于Python编程语言的搞笑笑话给我听",
"stream": false
}
全屏;退出全屏
点击图片查看详细信息
Ollama Python库

对于Python开发者来说,Ollama提供了一个方便的库。
- 安装库包:
pip install ollama - 在你的Python脚本中使用它,例如:
import ollama
response = ollama.chat(model='qwen2.5:14b', messages=[
{
'role': '身份', # 身份更符合此处的语境,而不是“角色”
'content': '给我讲一个关于Golang的搞笑笑话!', # 更自然地表达“Tell me a funny joke about Golang!”
},
])
print(response['message']['content'])
点击全屏按钮进入全屏模式,点击退出按钮退出全屏模式
如图所示

Ollama 在易用性和灵活性之间取得了很好的平衡,因此非常适合开发者用来构建 AI 驱动的应用程序。
3. Hugging Face Transformers,高级模型使用
Hugging Face Transformers 提供了一个强大的库,提供了许多模型的访问权限,并且让你对这些模型的使用有更多的掌控。
设置Hugging Face的Transformers
首先,创建一个新的Python虚拟环境:
运行命令 `python -m venv env` 创建一个名为env的虚拟环境。 运行命令 `source env/bin/activate` 激活这个虚拟环境。
全屏 退出全屏
- 安装需要用到的库:
pip install: torch transformers accelerate
# 安装这些包,它们是用于深度学习和自然语言处理的工具。
全屏 退出全屏
安装Hugging Face的命令行工具(CLI)。
请确保您已安装pip并具有Python环境。运行以下命令来升级安装Hugging Face Hub的命令行界面插件:
pip install -U huggingface_hub[cli]
进入全屏,退出全屏
进入Hugging Face,
请在命令行中输入以下内容来登录Hugging Face:
huggingface-cli login
然后按照提示完成登录过程。
进入全屏,退出全屏
(您需要在Hugging Face网站上获取一个user access token)
使用基于Transformers的模型
以下是一个简单的例子:使用3.2版本的3B规模的LLaMA模型。
import torch
from transformers import pipeline
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "你是一个海盗聊天机器人,总是用海盗腔调回复!"},
{"role": "user", "content": "你是谁?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["生成文本"][-1])
切换到全屏 退出全屏

Hugging Face Transformers 的优势
- 访问一个庞大的模型库
- 对模型参数的细致控制
- 针对特定任务进行模型微调
- 与流行的深度学习框架无缝集成
虽然Hugging Face Transformers需要更多的编码知识,但它提供了无与伦比的灵活性,并且可以访问最新的AI模型。
总结。这是一张图片链接,点击可以查看图片。

我们已经发现了三个强大的工具,这些工具可以在您的 Mac 上本地运行 AI 模型的应用。
- LM Studio:非常适合初学者和快速实验
- Ollama:更适合喜欢命令行界面和简单API集成的开发者
- Hugging Face Transformers:最适合需要访问多种模型并进行精细控制的高级用户
每个工具都有其强项,选择应根据您的具体需求和专业技能。通过在本地运行这些模型,这样您可以更好地掌控自己的AI应用,同时保护您的数据隐私,同时避免云服务的费用。
在使用较大模型时,请先考虑您的 Mac 配置,因为这些模型可能需要较多资源。可以从较小的模型开始,随着您逐渐熟悉工具和硬件性能,再逐步尝试更大模型。
祝你编程愉快,享受探索 Mac 上的本地 AI 的世界!
如有任何问题或意见,欢迎随时联系或留言。
这篇关于在您的Mac上运行本地语言模型的最详尽指南的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-29uni-app 中使用 Vant Weapp,怎么安装和配置npm ?-icode9专业技术文章分享
- 2024-12-27Nacos多环境配置学习入门
- 2024-12-27Nacos快速入门学习入门
- 2024-12-27Nacos快速入门学习入门
- 2024-12-27Nacos配置中心学习入门指南
- 2024-12-27Nacos配置中心学习入门
- 2024-12-27Nacos做项目隔离学习入门
- 2024-12-27Nacos做项目隔离学习入门
- 2024-12-27Nacos初识学习入门:轻松掌握服务发现与配置管理
- 2024-12-27Nacos初识学习入门:轻松掌握Nacos基础操作



