用SWIRL打造自己的开源AI搜索引擎,就像Perplexity一样
2024/10/25 21:03:20

本文主要是介绍用SWIRL打造自己的开源AI搜索引擎,就像Perplexity一样,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
Perplexity AI 是一个利用搜索引擎和人工智能模型相结合的方式,来提供搜索查询的答案,因此获得了广泛关注。这是一个基于人工智能的搜索引擎。
不同于像必应、谷歌和雅虎这样的传统搜索引擎,Perplexity 则使用大型语言模型来解析和回应查询,提供不仅仅是关键词匹配,而是上下文相关的答案。
构建困惑
我们可以从上述段落中得出三个因素。
- 理解用户自然语言的查询,这要归功于大型语言模型(LLM)和一些提示工程。
- 具备从不同来源搜索和获取答案的能力。
- 将所有结果汇总在一起,生成一个引用来源的AI答案。
- (可选)重新排序结果,使结果更贴合用户的需求。
所以,为了让你的数据和数据源得到有效处理,我们需要一个解决方案来连接数据源、应用程序和数据库以获取数据。需要一个搜索基础设施,然后并集成到AI模型,例如摘要、重新排序等功能。
对于这部分,我们将使用SWIRL将应用和AI模型集成在一起。至于搜索,我们将使用SWIRL的Docker容器中内置的默认Google搜索引擎插件。你可以添加更多的应用来搜索,但这部分内容将在未来的教程中介绍。 😁
SWIRL 项目在 GitHub 上
安装SWIRL要使用GitHub指南在Docker中尝试SWIRL软件,请按以下步骤操作:
还有一个简短的YouTube教程,您可以观看一下……
前提条件
- 确保您的系统(MacOS、Linux 或 Windows)已安装并运行 Docker。如果是 Windows 用户,可能还需要安装和配置 WSL 2(WSL 2) 或 Hyper-V(Hyper-V)。
- Windows 用户可能还需要安装和配置 WSL 2 或 Hyper-V。
在 Docker 中安装和配置 SWIRL 的步骤 🐋
下载 Docker 的 YAML 文件:
- 打开一个终端并运行命令
``` curl https://raw.githubusercontent.com/swirlai/swirl-search/main/docker-compose.yaml -o docker-compose.yaml
此命令用于从GitHub获取docker-compose.yaml文件。 2. **在 Docker 中启动 SWIRL**: * 对于 **MacOS 或 Linux 用户**,可以运行: 在终端中输入以下命令:
docker-compose pull && docker-compose up
对于 **Windows** 系统,在 PowerShell 中运行:
docker compose up
启动 Docker Compose 服务 1. **开启实时的RAG(检索增强)**: * 设置环境变量值:
export MSAL_CB_PORT=8000 # 设置MSAL端口为8000 export MSAL_HOST=localhost # 设置MSAL主机为本地主机 export OPENAI_API_KEY='your-OpenAI-API-key' # 设置你的OpenAI API密钥
重启 Docker,以激活 RAG 特性。 1. **访问SWIRL页面**: * 在浏览器中输入 `http://localhost:8000`。 * 用管理员身份登录(用户名是 `admin`,默认密码也是 `password`)。 * 输入搜索词并点击“搜索”按钮查看结果。 如果您需要更多帮助,可以在这里查看详细说明[这里](https://github.com/swirlai/swirl-search)。 ## 让我们开始吧,开始搜索并让AI生成摘要 🔍 一旦SWIRL系统运行起来,我们就可以开始搜索各种查询并自动生成AI总结了。最棒的是,它还能对搜索结果进行重新排序。 **搜索“最好的开源搜索引擎”** [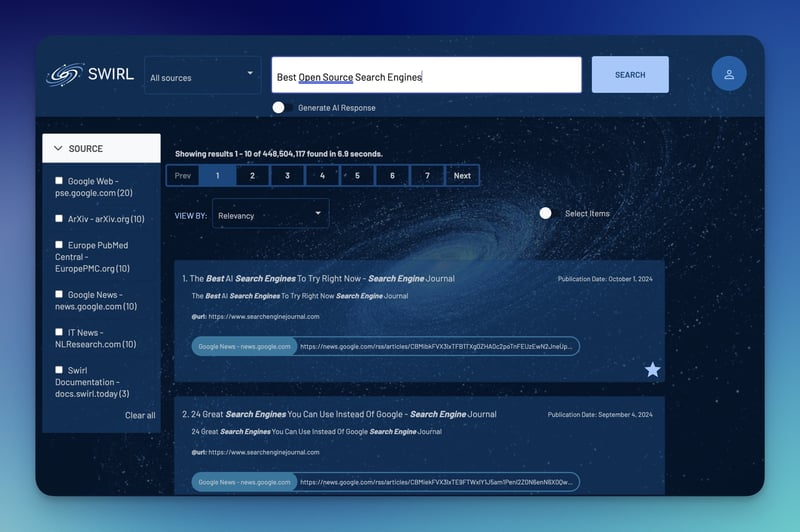](https://imgapi.imooc.com/671af82008f2ee2708000532.jpg) **搜索“注意力全靠它”** 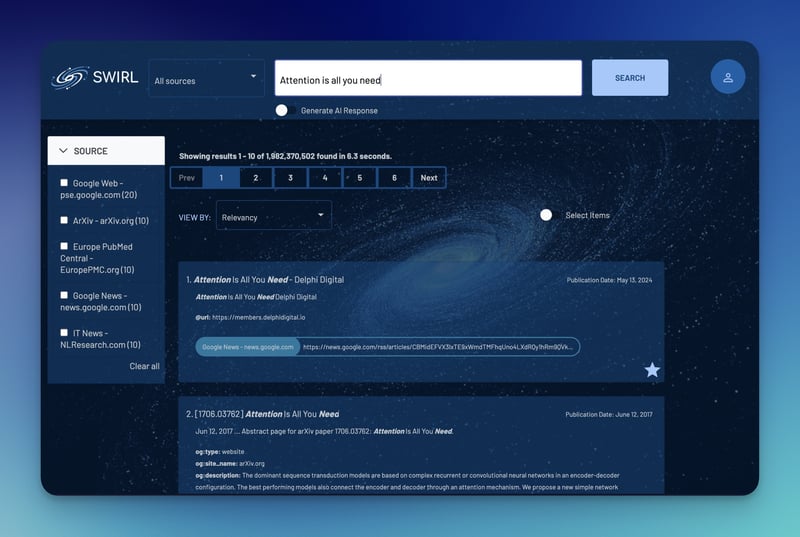 **全靠注意力机制的AI总结** 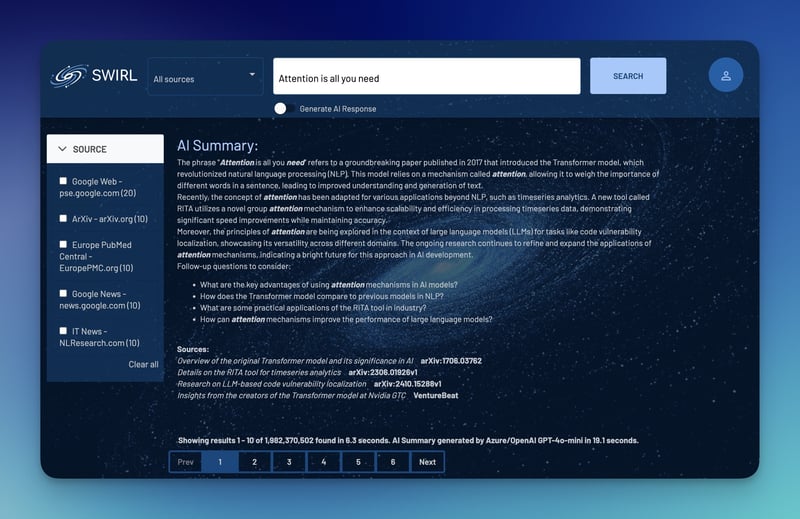 目前,它与Google PSE这样的工具配合得很好,你也可以搜索特定的网站,如左边所示。此外,添加连接器也很简单,只需一个PR即可。 ## 添加更多应用并自定义搜索体验 使用 Google 搜索结果进行搜索和检索增强生成(RAG)是一个很好的开始,但真正的优势在于将 SWIRL 与各种应用连接起来。这使得可以从工作场所的数据中进行更全面的搜索并直接生成 AI 摘要,从而使信息的发现更快、更有效。 要开始,请访问管理面板并输入你想要连接的应用的bearer令牌(bearer token)。有一个[详细的视频教程](https://www.youtube.com/watch?v=WCYqx0mOXeI)可以引导你完成与OpenSearch集成的步骤,还有关于支持的连接器的文档。这使得配置SWIRL,并最大限度地提高其在连接数据源中的搜索能力变得非常简单。 ### 加入我们的 SWIRL 社区吧 [](https://imgapi.imooc.com/671af823090e687008000323.jpg) SWIRL 是一个开源项目,遵循 Apache 2.0 许可证。我们非常欢迎你在 GitHub 上查看 SWIRL 并给它一个 Star 支持,这是支持我们的好方法。 在 GitHub 上给我们一个 ⭐。 要是你有兴趣添加新的网站或app作为可搜索的连接,我们欢迎你的加入。 [来加入我们的Slack吧!](https://join.slack.com/t/swirlmetasearch/shared_invite/zt-2sfwvhwwg-mMn9tcKhAbqXbrV~9~Y1eA)
这篇关于用SWIRL打造自己的开源AI搜索引擎,就像Perplexity一样的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-22程序员出海做 AI 工具:如何用 similarweb 找到最佳流量渠道?
- 2024-12-20自建AI入门:生成模型介绍——GAN和VAE浅析
- 2024-12-20游戏引擎的进化史——从手工编码到超真实画面和人工智能
- 2024-12-20利用大型语言模型构建文本中的知识图谱:从文本到结构化数据的转换指南
- 2024-12-20揭秘百年人工智能:从深度学习到可解释AI
- 2024-12-20复杂RAG(检索增强生成)的入门介绍
- 2024-12-20基于大型语言模型的积木堆叠任务研究
- 2024-12-20从原型到生产:提升大型语言模型准确性的实战经验
- 2024-12-20啥是大模型1
- 2024-12-20英特尔的 Lunar Lake 计划:一场未竟的承诺



