Databricks与Snowflake:数据处理实力大比拼
2024/11/5 21:03:26

本文主要是介绍Databricks与Snowflake:数据处理实力大比拼,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
By [罗伯特·汤普森](https://www.linkedin.com/in/rdt000/)(作者的领英个人主页)
街上的说法是,AI和ML是未来的趋势。让数据高效且低成本地变得可访问和可发现,这已成为许多企业的首要任务。在这个领域中,Snowflake和Databricks是热门选择。现在有很多工具可以帮忙处理这些工作,并且它们都声称与这些候选者兼容。让我们来比较一下这两款产品,看看能否找到一个性价比高的选择。
AI/ML任务所使用的数据平台需要具备成本效益、高性能和可靠性的特点才能成功。我们的平台还有一个移动性特点,也就是说,我们的数据不应该被隔离。
这是对前几个支柱进行的可重复测试。这些测试将对成本和性能指标进行可重复测量,并以文档形式记录下来。
Snowflake 是一个云端托管的数据仓库服务。Snowflake 的数据存储格式是专有的,这意味着加载到 Snowflake 中的数据只能使用 Snowflake 计算服务进行查询。Snowflake 支持写入 Iceberg,但这个功能从 2022 年开始一直处在预览阶段,直到 2024 年 3 月,人们不禁会怀疑它是否会真正发布。由于该功能尚未正式发布,也不适合用于生产环境,这些测试都没有使用 Iceberg 进行。(注:2024 年 6 月 10 日,Snowflake 中的 Iceberg 表正式上线)
Snowflake可以通过JDBC连接器进行查询,因此非常方便,并且有许多软件与Snowflake集成。Snowflake在计算和存储上都可以实现线性扩展,并且在Snowflake的一个实例中,数据库之间的数据共享非常容易。由于Snowflake内部易于共享数据且易于扩展,因此它是一个优秀的企业数据仓库选择。可以在Snowflake的数据集上进行一些优化设置,但其他OLAP解决方案中的许多优化措施,如识别聚簇键等,已被Snowflake自动化处理。与Snowflake架构类似的系统有AWS Redshift和Google BigQuery。
Databricks 是一家提供托管 Spark 实例的云端服务商。Spark 是当前最先进的 ETL 工具套件。Databricks 在其托管的 Spark 平台上构建了多个服务,包括 Unity Catalog,它可以轻松地在企业内部实现数据治理和数据共享,以及 Databricks SQL,它则利用无服务器 Spark 实例来执行针对数据湖中数据的数据仓库风格查询。Databricks 能够查询几乎任何类型的数据源,但一种常见的架构被称为“Delta Lake”。一个“Delta Lake”是一个主要使用“Delta Table”格式的“Lakehouse”。一个“Lakehouse”则是将数据仓库技术应用于数据湖中的开源数据集的地方。使用开源格式使得多种计算资源可以免费访问 Lakehouse 中的数据,同时数据存储在数据湖中也便于企业内部共享。像 Snowflake 一样,Databricks 可以线性扩展计算和存储。加载到 Databricks 首选格式中的数据可以轻松优化,但要最大化优化效果,需要理解查询模式。
无论工作负载或工具如何,从雪flake表中获取数据都必须使用Snowflake计算。SageMaker可以连接到Snowflake,并从大型表中以多种视角读取数据。在每个视角中,都需要使用Snowflake和SageMaker的计算能力。在这种情况下,您需要为SageMaker和Snowflake的计算付费。SageMaker可能会分析数据集,认为需要从数据中获取871个不同的视角。这可能意味着需要向Snowflake发送871个不同的查询以填充该模型。
Databricks的开源格式“Delta”就没有这个问题,Databricks也不会重复计算费用。
一个公开的数据集已经被放入了ADLS容器中。这个数据集是通过收集纽约市黄色出租车的信息而获得的,通常用于数据工程技术领域的概念验证(POC)和测试目的。数据集的一些细节如下:
· 包含157亿条记录
· 存储在 499 个 parquet 文件中(而不是 delta 表)
文件大小是 52.86 GB,位于 ADLS 里。
人们经常要求比较的一个共同点是“开始查询数据集有多简单”,其中一个场景是一堆文件直接被丢进一个数据仓库中。为了模拟这一场景,我们直接在原生的 parquet 格式数据集上运行查询。由于 Snowflake 主要设计用于查询已加载到其管理表中的数据,我们将数据加载到每个系统的管理表中,并重复了这些查询。
查询被分为简单、中等复杂、复杂和荒诞这四种类型。
请:按取车时间排序,显示最近1000次行程
选择性查询:运行一个非常具体的查询,该查询需要扫描,而不是聚合数据,并只返回少量的数据行
显示在数据集中每个月和每一年最贵的出行。
计算数据集中不同行的数目
注:这两个系统的具体价格可能比较难准确确定。这里的价格是根据每个系统中的审计数据大致估算的。
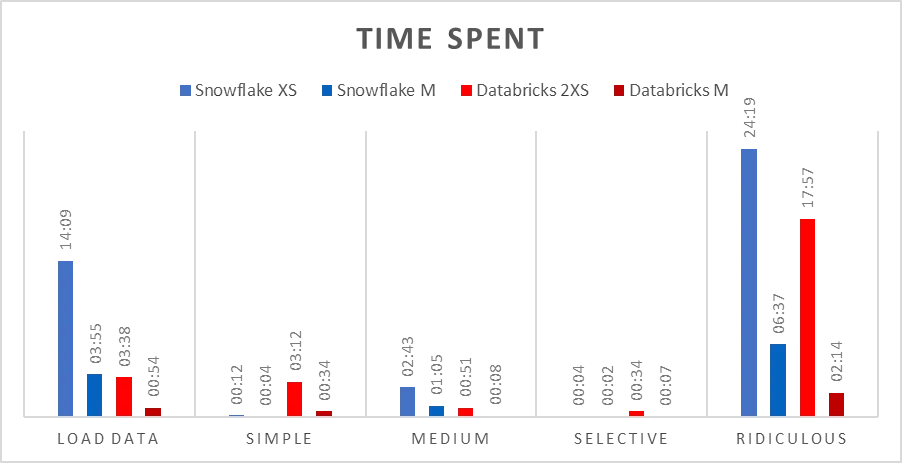
· Databricks 在读取数据湖中的文件时比 Snowflake 快很多,通常快一倍左右。
· 当数据加载到 Snowflake 后,某些查询在 Snowflake 中的执行表现优于 Databricks,但这似乎取决于查询模式的不同。特别是,窗口功能 在 Databricks 中表现更好。这一点对于找到每个月最大的操作量来说非常重要。
· 在两个平台上正确调整计算资源至关重要——对于给定的数据集,如果使用的计算资源过小,那么在处理过程中数据将不得不从内存写入磁盘,这会显著影响性能。
这个比较是在考虑是否需要数据移动的情况下进行的。
(注:在某些上下文中,“Snowflake”可能指的是过于敏感的人。)
- 创建集成任务
- 创建步骤
- 创建外部表(确保启用自动刷新功能)
- 运行查询
创建或替换外部表 NYCTLCYELLOW (
"endLon" FLOAT AS (value:endLon::FLOAT),
"endLat" FLOAT AS (value:endLat::FLOAT),
"passengerCount" NUMBER(38,0) AS (value:passengerCount::NUMBER),
"tripDistance" FLOAT AS (value:tripDistance::FLOAT),
"puLocationId" VARCHAR(16777216) AS (value:puLocationId::VARCHAR),
"doLocationId" VARCHAR(16777216) AS (value:doLocationId::VARCHAR),
"startLon" FLOAT AS (value:startLon::FLOAT),
"startLat" FLOAT AS (value:startLat::FLOAT),
"totalAmount" FLOAT AS (value:totalAmount::FLOAT),
"puYear" NUMBER(38,0) AS (value:puYear::NUMBER),
"puMonth" NUMBER(38,0) AS (value:puMonth::NUMBER),
"fareAmount" FLOAT AS (value:fareAmount::FLOAT),
"extra" FLOAT AS (value:extra::FLOAT),
"mtaTax" FLOAT AS (value:mtaTax::FLOAT),
"improvementSurcharge" VARCHAR(16777216) AS (value:improvementSurcharge::VARCHAR),
"tipAmount" FLOAT AS (value:tipAmount::FLOAT),
"tollsAmount" FLOAT AS (value:tollsAmount::FLOAT),
"vendorID" VARCHAR(16777216) AS (value:vendorID::VARCHAR),
"tpepPickupDateTime" TIMESTAMP_NTZ(9) AS (value:tpepPickupDateTime::TIMESTAMP_NTZ),
"tpepDropoffDateTime" TIMESTAMP_NTZ(9) AS (value:tpepDropoffDateTime::TIMESTAMP_NTZ),
"rateCodeId" NUMBER(38,0) AS (value:rateCodeId::NUMBER),
"storeAndFwdFlag" VARCHAR(16777216) AS (value:storeAndFwdFlag::VARCHAR),
"paymentType" VARCHAR(16777216) AS (value:paymentType::VARCHAR)
)
位置=@YOURSTORAGE_UDP_GEO_STAGE/NycTlcYellow/ 自动刷新=true 模式='.+.parquet
## **Databricks(一家数据分析公司)**
1. 创建外部位置或定义访问凭证。
2. 运行查询。
select count(*) FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet`
## **结果**  ## 简单的 Parquet 查询 典型的分析师会运行类似这样的查询来查找数据的结构和形态。可以说这是开始回答日常问题的一个起点。 ## **雪花 (一词)** 注:在英文中,“Snowflake”一词有时用于指代被认为过于敏感的人。此处直接翻译为“雪花”,指的是自然界的雪花。若此处涉及特定文化语境,建议使用“雪花 (一词)”来加以说明。 这其实是个坑,如果你运行时不带 EXCLUDE 参数或者不知道需要加上 EXCLUDE 参数的话,在 Snowflake 上性能会非常糟糕。只是想说,Snowflake 的查询对于日常分析人员来说可能不太直观。但这不是说查询不行,只是运行它会更费钱。
SELECT * EXCLUDE (value) FROM nyctlcyellow -- 从 'nyctlcyellow' 表中选择所有数据,除了 'value' 列 ORDER BY "tpepPickupDateTime" DESC -- 按 'tpepPickupDateTime' 列降序排列 LIMIT 1000 -- 并限制结果为 1000 条记录
## **Databricks**
SELECT
FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/.parquet`
ORDER BY tpepPickupDateTime DESC
LIMIT 1000
## **研究结果**  ## Parquet 中等复杂度查询 这是一条模拟财务分析师可能从领导层那里得到的查询问题:“每年或每月哪些游乐设施最贵?” ## **玻璃心的人** ## **雪花** (Note: Given the context provided by the expert suggestions, "玻璃心的人" (bōli xīn de rén) is used to reflect the metaphorical or potentially pejorative usage of "Snowflake" in English. However, if "Snowflake" is being used as a literal term or if the context is specifically about snowflakes, "雪花" (xuěhuā) is also provided to cover both interpretations. If there's a specific context that's not mentioned, please provide more details to choose the most appropriate translation.) Given the instructions to output only the translation: ## **玻璃心的人**
/* 选择每个 "puYear" 和 "puMonth" 组合中总金额最高的记录 */
SELECT "puYear", "puMonth", "totalAmount"
FROM (
/* 计算每个 "puYear" 和 "puMonth" 组合中的总金额排名 */
SELECT "puYear", "puMonth", "totalAmount", ROW_NUMBER() OVER (partition by "puYear", "puMonth" order by "totalAmount") as rn
FROM nyctlcyellow
) ranked
/* 只取排名为1的数据 */
WHERE ranked.rn = 1
/* 注意: "nyctlcyellow" 是一个特定的数据库表名,它在这里表示黄色出租车的计费数据。*/ ## **Databricks**
SELECT puYear, puMonth, totalAmount
FROM (
SELECT puYear, puMonth, totalAmount, ROW_NUMBER() OVER (partition by puYear, puMonth
order by totalAmount) as rn
FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet`
) ranked
WHERE ranked.rn = 1
## **结果如下**  ## Parquet 选择性查询 这是一次模拟回答特定问题的查询。这里的谓词下推(即过滤条件)非常重要。这可以减少查询引擎需要读取的数据量,从而返回所需的行。 ## **雪flake** 这里的坑又来了。别忘了EXCLUDE哦,否则雪flake的股价会涨,而你公司的股价就跌了!
SELECT * EXCEPT (value)
FROM nyctlcyellow
WHERE "startLon" BETWEEN -73.97 AND -73.93
AND "startLat" BETWEEN 40.75 AND 40.79
AND "vendorID" = 'CMT'
AND "tpepPickupDateTime" BETWEEN '2014-04-30 23:55:04.000' AND '2014-06-30 23:55:04.000'
AND "paymentType" != '现金'
AND "totalAmount" < 4.00
AND "endLon" < -74
## **Databricks**
SELECT * FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet` WHERE startLon BETWEEN '-73.97' AND '-73.93' AND startLat BETWEEN '40.75' AND '40.79' AND vendorID = 'CMT' AND tpepPickupDateTime BETWEEN '2014-04-30 23:55:04.000' and '2014-06-30 23:55:04.000' AND paymentType != 'CSH' AND totalAmount < '4.00' AND endLon < '-74'
## **来看看结果** ## **结果如下**  ## 荒唐的 Parquet 查询 > 万物皆有其限度——铁矿是不能变成黄金的。——马克·吐温(Mark Twain) 让我们统计样本数据集中最大表的不同行数。 ## **小雪花** 这个坑又来了。别忘了EXCLUDE这个选项,否则Snowflake的股价会上涨,而你公司的股价会跌。
SELECT count(*) FROM ( SELECT * EXCLUDE (value) FROM nyctlcyellow GROUP BY ALL ) a
注释:此SQL查询用于从`nyctlcyellow`表中排除`value`列后,对所有其他列进行分组,并计算分组后的行数。 ## **Databricks**
SELECT count(*) FROM ( SELECT * FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet` GROUP BY ALL ) a
这段SQL代码用于从指定的Parquet文件中查询数据总数。首先,它从文件中选择所有数据,并按所有列进行分组,然后计算总行数。 ## **结果如下**  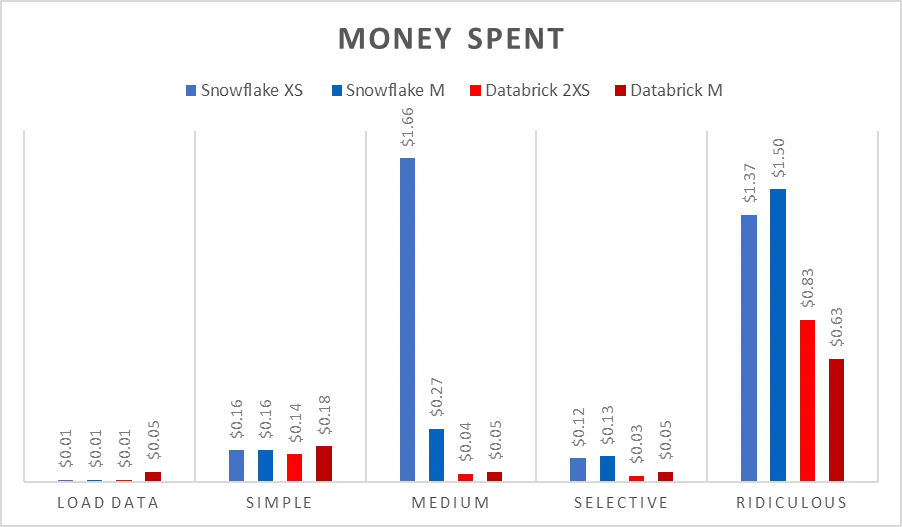  # 查询 Snowflake 的隔离架构和 Databricks 的开源管理表 ## **雪花(人)** 这个坑又出现了。我试了几种不同的方法,发现这种方法最快最便宜。别忘了EXCLUDE,否则雪flake的股价会涨,而你公司股价会跌!
CREATE OR REPLACE TABLE nyctlcyellow_schema AS SELECT * EXCLUDE (value) FROM NYCTLCYELLOW; -- 使用 `INSERT INTO` 的另一种方法 CREATE OR REPLACE TABLE nyctlcyellow_insert AS SELECT * EXCLUDE (value) FROM nyctlcyellow WHERE 1 = 2; -- (创建一个空表的技巧) INSERT INTO nyctlcyellow_insert SELECT * EXCLUDE (value) FROM nyctlcyellow; -- (排除 value 列)
## **Databricks**
创建或替换表 yourcatalog.demo.nyctlcyellow 语句 作为 WITH SELECT * 从 parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet` (注意:`yourcatalog.demo.nyctlcyellow` 是占位符,实际的目录和表名请替换为具体值)
(注意:`NycTlcYellow` 和 `yourstorage` 是查询上下文中的特定术语,具体含义请根据实际情况解释。) ## **结果**  ## 简单的查询管理表 — (Snowflake 仓库/Databricks 开源) ## **雪flake**
SELECT *
FROM nyctlcyellow_schema
ORDER BY "tpepPickupDateTime" DESC
LIMIT 1000
## **Databricks** 以下是从 `yourcatalog.demo.nyctlcyellow` 表中获取最新数据的 SQL 语句。
SELECT * FROM yourcatalog.demo.nyctlcyellow ORDER BY tpepPickupDateTime DESC LIMIT 1000;
按 `tpepPickupDateTime` 降序排列并限制结果为 1000 条记录。 ## **结果如下**  ## 中等复杂度查询管理表格 — (雪flake 隔离层/Databricks 开源项目) ## **雪片(气象现象)/雪flake公司(公司名称)**
-- 找到每年和每月最昂贵的乘车费用,按年/月管理的表
SELECT "puYear", "puMonth", "totalAmount"
FROM (
SELECT "puYear", "puMonth", "totalAmount", ROW_NUMBER() OVER (PARTITION BY "puYear", "puMonth" ORDER BY "totalAmount" DESC) AS rn
FROM nyctlcyellow_schema
) ranked
WHERE 排名为 1
## **Databricks**
-- 查找每年每月最昂贵的查询记录
SELECT puYear, puMonth, totalAmount
FROM (
SELECT puYear, puMonth, totalAmount, ROW_NUMBER() OVER (PARTITION BY puYear, puMonth ORDER BY totalAmount) AS rn
FROM yourcatalog.demo.nyctlcyellow
) ranked
WHERE ranked.rn = 1
## **结果就是**  ## 选择性查询管理表(SQMT) — (Snowflake 隔离/Databricks 开源) ## **雪flake**
SELECT * FROM nyctlcyellow_schema WHERE "startLon" BETWEEN -73.97 AND -73.93 AND "startLat" BETWEEN 40.75 AND 40.79 AND "vendorID" = 'CMT' AND "tpepPickupDateTime" BETWEEN '2014-04-30 23:55:04.000' and '2014-06-30 23:55:04.000' AND "paymentType" != 'CSH' AND "totalAmount" < 4.00 AND "endLon" < -74
## **Databricks**
SELECT 所有字段
FROM yourcatalog.demo.nyctlcyellow
WHERE startLon BETWEEN '-73.97' AND '-73.93'
AND startLat BETWEEN '40.75' AND '40.79'
AND vendorID = 'CMT'
AND tpepPickupDateTime BETWEEN '2014-04-30 23:55:04.000' AND '2014-06-30 23:55:04.000'
AND paymentType != 'CSH'
AND 总金额 < '4.00'
AND 结束经度 < '-74'
## **研究结果**  ## 奇怪的查询管理表 — (Snowflake 存储/Databricks 开源) ## **Snowflake** 从包含所有行的表中选择所有数据,然后按所有列分组。接着,从分组后的结果集中计算行数。 ## **Databricks**
SELECT COUNT()
FROM (
SELECT
FROM dsnadev.demo.nyctlcyellow
GROUP BY ALL
) a
## 以下是我们得到的结果


# 结论部分
在查看某个产品时,你必须考虑长期成本。你的工作负载是怎样的?Snowflake似乎让你很容易就花掉钱。当然,设置一个实例并开始使用可能更容易,但是如果没有一个节俭的用户,它很快就会变得非常昂贵。你的查询方式如果不对,可能会让你的花费飙升。Databricks Serverless SQL 是一个相对较新的产品,但从这个有限的测试来看,它似乎已经赢得了数据爱好者们到处都是它的粉丝。
文件格式=(类型=parquet NULL_IF=()) ;
SELECT COUNT(*) FROM nyctlcyellow
-
Create external location OR define access credentials
- Run your query
select count(*) FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet`

The typical analyst runs something like this query on tables to find structure and shape of the data. One might say this is the entry point of trying to find an answer to everyday questions.
This was a gotcha here if you run this without the EXCLUDE or didn’t know you should include the EXCLUDE the performance was extremely bad in snowflake. Just a little learning that the snowflake queries are not intuitive for your everyday analysts. That is not to say the query didn’t work it is just that it cost more money to run it.
SELECT * EXCLUDE (value)
FROM nyctlcyellow
ORDER BY "tpepPickupDateTime" DESC
LIMIT 1000
SELECT *
FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet`
ORDER BY tpepPickupDateTime DESC
limit 1000

This is a query that is going to simulate answering a question of a finance analyst might get from leadership. “What are the most expensive rides per year/month?”
SELECT "puYear", "puMonth", "totalAmount"
FROM (
SELECT "puYear", "puMonth", "totalAmount", ROW_NUMBER() OVER (partition by "puYear", "puMonth" order by "totalAmount") as rn
FROM nyctlcyellow
) ranked
WHERE ranked.rn = 1
SELECT puYear, puMonth, totalAmount
FROM (
SELECT puYear, puMonth, totalAmount, ROW_NUMBER() OVER (partition by puYear, puMonth
order by totalAmount) as rn
FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet`
) ranked
WHERE ranked.rn = 1

This is a query to simulate answering a specific question. Predicate push down(filter criteria) here is important. This should limit the amount of data the query engine needs to read to return the rows that were requested.
The gotcha here showed up again. Don’t forget the EXCLUDE or the stock price of snowflake goes up and your company stock goes down!
SELECT * EXCLUDE (value)
FROM nyctlcyellow
WHERE "startLon" BETWEEN -73.97 AND -73.93
AND "startLat" BETWEEN 40.75 AND 40.79
AND "vendorID" = 'CMT'
AND "tpepPickupDateTime" BETWEEN '2014-04-30 23:55:04.000' and '2014-06-30 23:55:04.000'
and "paymentType" != 'CSH'
AND "totalAmount" < 4.00
AND "endLon" < -74
SELECT *
FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet`
WHERE startLon BETWEEN '-73.97' AND '-73.93'
AND startLat BETWEEN '40.75' AND '40.79'
AND vendorID = 'CMT'
AND tpepPickupDateTime BETWEEN '2014-04-30 23:55:04.000' and '2014-06-30 23:55:04.000'
and paymentType != 'CSH'
AND totalAmount < '4.00'
AND endLon < '-74'

Everything has its limit — iron ore cannot be educated into gold. -Mark Twain
Let’s find a count of distinct rows from the largest table in our sample dataset.
The gotcha here showed up again. Don’t forget the EXCLUDE or the stock price of snowflake goes up and your company stock goes down!
SELECT count(*)
FROM (
SELECT * EXCLUDE (value)
FROM nyctlcyellow
group by all
) a
SELECT
count(*)
FROM
( SELECT *
FROM
parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet`
GROUP BY ALL
) a



The gotcha here showed up again. Tried this a few different ways and found this method to be the fastest/cheapest. Don’t forget the EXCLUDE or the stock price of snowflake goes up and your company stock goes down!
CREATE OR REPLACE TABLE nyctlcyellow_schema
AS
SELECT * EXCLUDE (value)
FROM NYCTLCYELLOW;
-- alternate method that uses INSERT INTO
CREATE OR REPLACE TABLE nyctlcyellow_insert
AS SELECT * EXCLUDE (value) FROM nyctlcyellow WHERE 1 = 2;
INSERT INTO nyctlcyellow_insert
SELECT * EXCLUDE (value) FROM nyctlcyellow
CREATE OR REPLACE TABLE yourcatalog.demo.nyctlcyellow
AS
SELECT *
FROM parquet.`abfss://sample-data@yourstorage.dfs.core.windows.net/NycTlcYellow/*.parquet`

SELECT *
FROM nyctlcyellow_schema
ORDER BY "tpepPickupDateTime" DESC
LIMIT 1000
SELECT *
FROM yourcatalog.demo.nyctlcyellow
ORDER BY tpepPickupDateTime DESC
LIMIT 1000;

-- find the most expensive rides by year/month managed table
SELECT "puYear", "puMonth", "totalAmount"
FROM (
SELECT "puYear", "puMonth", "totalAmount", ROW_NUMBER() OVER (partition by "puYear", "puMonth" order by "totalAmount") as rn
FROM nyctlcyellow_schema
) ranked
WHERE ranked.rn = 1
-- find the most expensive queries by year/month
SELECT puYear, puMonth, totalAmount
FROM (
SELECT puYear, puMonth, totalAmount, ROW_NUMBER() OVER (partition by puYear, puMonth order by totalAmount) as rn
FROM yourcatalog.demo.nyctlcyellow
) ranked
WHERE ranked.rn = 1

SELECT *
FROM nyctlcyellow_schema
WHERE "startLon" BETWEEN -73.97 AND -73.93
AND "startLat" BETWEEN 40.75 AND 40.79
AND "vendorID" = 'CMT'
AND "tpepPickupDateTime" BETWEEN '2014–04–30 23:55:04.000' and '2014–06–30 23:55:04.000'
AND "paymentType" != 'CSH'
AND "totalAmount" < 4.00
AND "endLon" < -74
SELECT *
FROM yourcatalog.demo.nyctlcyellow
WHERE startLon BETWEEN '-73.97' AND '-73.93'
AND startLat BETWEEN '40.75' AND '40.79'
AND vendorID = 'CMT'
AND tpepPickupDateTime BETWEEN '2014–04–30 23:55:04.000' and '2014–06–30 23:55:04.000'
AND paymentType != 'CSH'
AND totalAmount < '4.00'
AND endLon < '-74'

SELECT count(*)
FROM (
SELECT *
FROM nyctlcyellow_schema
GROUP BY ALL
) a ;
SELECT count(*)
FROM (
SELECT *
FROM dsnadev.demo.nyctlcyellow
GROUP BY ALL
) a



When looking at a product you must account for long term cost. What do your workloads look like? Snowflake seems to make things easy to spend money. Sure, it might be easier to setup an instance and get started using, but if not used by someone that is frugal it will get expensive easily. The wrong way you query something can exponentially move your query cost up the chart. Databricks Serverless SQL is a relatively new product, but from this limited test it seems to be making fans out of data minded people all over.
这篇关于Databricks与Snowflake:数据处理实力大比拼的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-23DevExpress 怎么实现右键菜单(Context Menu)显示中文?-icode9专业技术文章分享
- 2024-12-22怎么通过控制台去看我的页面渲染的内容在哪个文件中呢-icode9专业技术文章分享
- 2024-12-22el-tabs 组件只被引用了一次,但有时会渲染两次是什么原因?-icode9专业技术文章分享
- 2024-12-22wordpress有哪些好的安全插件?-icode9专业技术文章分享
- 2024-12-22wordpress如何查看系统有哪些cron任务?-icode9专业技术文章分享
- 2024-12-21Svg Sprite Icon教程:轻松入门与应用指南
- 2024-12-20Excel数据导出实战:新手必学的简单教程
- 2024-12-20RBAC的权限实战:新手入门教程
- 2024-12-20Svg Sprite Icon实战:从入门到上手的全面指南
- 2024-12-20LCD1602显示模块详解



