知乎启用AutoMQ替换Kafka,开辟成本优化与运维提效新纪元
2024/12/2 21:03:02

本文主要是介绍知乎启用AutoMQ替换Kafka,开辟成本优化与运维提效新纪元,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!

作者:知乎在线架构组 王金龙
关于知乎
知乎公司,成立于 2010 年 8 月 10 日,于 2011 年 1 月 26 日正式上线,是中文互联网的高质量问答社区和创作者聚集的原创内容平台。
知乎起步于问答,而超越了问答。知乎以「生态第一」为战略,「专业讨论」为核心定位,构建起富有包容性和生命力的社区生态,覆盖热榜、知乎直答、想法、盐言故事、知乎知学堂、内容商业化解决方案等多种产品和功能,为用户、创作者和商业合作伙伴提供多样化的丰富体验。
立足于应用层和数据层的丰厚积累,知乎一直奋进于技术创新前沿,在 NLP、人工智能、中文语言大模型领域形成研发和应用优势,先后推出「智能社区」、「知海图 AI」大模型、知乎直答等技术战略和产品,为社区生态和用户体验持续赋能。
知乎在大规模运维 Kafka 集群时遇到的问题
存储服务的静态资源池不够灵活
我们原来基于云厂商的裸金属机器划分了消息队列的资源池。在业务流量上涨的场景下,负责热点流量的 Kafka 节点会导致存储节点磁盘空间快速到达水位线。这时需要对存储资源池进行扩容。
在扩容的过程中产生了两个问题:
-
存储资源池需要进行数据均衡:在此期间有大量的数据需要在资源池内进行数据搬迁,耗时很长,产生了很大的运维成本。数据搬迁期间会触发大量的数据冷读,由于 Kafka 原生存储模型限制,单个分区数据只能保存在一块磁盘上,在数据迁移期间占用了非常多的磁盘带宽,新写入的消息因为无法使用足够多的磁盘带宽,导致迁移期间写入延迟达到了 10 秒级以上。同时大规模读取历史数据导致 Page Cache 频繁 Miss,线上正常业务读取的流量也会频繁读取磁盘,进一步争抢磁盘带宽,导致大规模消费堆积。数据搬迁操作给集群读写延迟和整体稳定性带来了非常大的影响。
-
存储资源池计算资源闲置:Kafka 是 IO 密集型的存储中间件,计算资源不会首先成为资源池瓶颈。资源池的隔离划分虽然增强了服务稳定性,但是同时也让如何充分利用剩余的计算资源变成了新的难点。
大规模突发流量快速扩缩容问题
面对大规模突发流量时,作为服务维护方需要保证稳定服务稳定性。为此有一般两种方式:
方式 1 :一种是尽快进行资源扩容,并将热点分区打散到新的机器上。
方式 2 :通过预先分配额外资源保证集群在业务流量高峰时容量充足。
每种选择同样也产生了新的问题:
-
方式 1 在 Kafka 原生架构模型下,扩容节点同样需要数据搬迁,很可能搬迁完成后已经错过了突发流量的时间窗口。不能很好的提供更稳定的消息队列服务。
-
方式 2 通过资源池预留更多额外资源,可以保证业务的稳定性,但是会导致资源池的利用率偏低,增加企业技术成本。
知乎对消息中间件选型的要求
- 低资源成本&低运维成本&高资源利用率:
存算分离,可以灵活按需配置计算资源和存储资源。最好可以像无状态服务一样可以利用公司统一资源池,不用再单独维护存储资源池。降低整体资源池冗余程度,提高资源池利用率。最好可以避免数据迁移引入的运维成本。
- 弹性服务能力:
热点流量下可以快速扩容服务,对外提供更多的服务容量,流量峰值经过后可以释放对应资源,进一步压缩成本。同时扩容时间尽可能短,避免之前因为数据搬迁过慢导致错过流量洪峰的问题。
- 低迁移成本&高稳定性&高兼容性:
公司整体依赖 Kafka API 进行异步链路通信,在线业务解耦,推荐埋点效果日志,推荐数据样本拼接等大量场景均基于 Kafka API。选用其他消息中间件需要更换 SDK 接口,会在迁移的过程中增加极大的人力成本负担。我们期望业务方无需改造代码即可迁移。
AutoMQ 如何解决知乎遇到的问题
AutoMQ 充分利用云厂商提供的存储基础设施,对原生的 Kafka 进行了存算分离改造,极大降低了 Kafka 资源成本和运维成本。AutoMQ 基于 EBS 云盘和对象存储提供的服务能力,呈现了一款可以对外提供低延迟高吞吐海量数据存储的次世代消息中间件。
-
存算分离带来的极大资源成本优势:
-
上层应用不再强绑定存储资源机器,无需进行存储节点数据搬迁等运维动作,极大程度减少集群运维成本。
-
原有资源池可以配置计算型机器,依靠云厂商提供稳定的存储服务,无需额外配置存储资源,显著降低消息队列资源池的成本。
-
充分利用对象存储,可以提供更高规模的存储带宽和相比自建更低的存储成本。
-
-
赋能存储服务更灵活的弹性能力:
-
云原生兼容:将 Kafka 转变为近似无状态服务,可以充分利用现有 K8s 基础设施提供的标准能力,显著减少运维成本。
-
集群秒级扩缩容:AutoMQ 的创新架构将 Kafka 的分区的数据主节点的职责能力进行了拆分,数据读写等计算层逻辑保留,存储层逻辑下沉到自研的 S3Stream[1] 架构,将底层数据灵活的分散到 EBS 云盘和对象存储中。扩缩容动作无需进行数据搬迁,在集群 Meta 节点触发迁移分区到新扩容节点即可完成热点分区打散动作。迁移过程中流量无损对业务透明无影响。
-
-
100% 兼容标准 Kafka API:
-
业务无需改造现有代码,服务维护方无需维护 Kafka API 兼容层,省去服务迁移导致不必要的人力开销。
-
原生 Kafka 生态无缝兼容,可以直接复用公司原有的 Kafka 周边基础设施,避免重复建设。
-
AutoMQ 在知乎落地后的效果
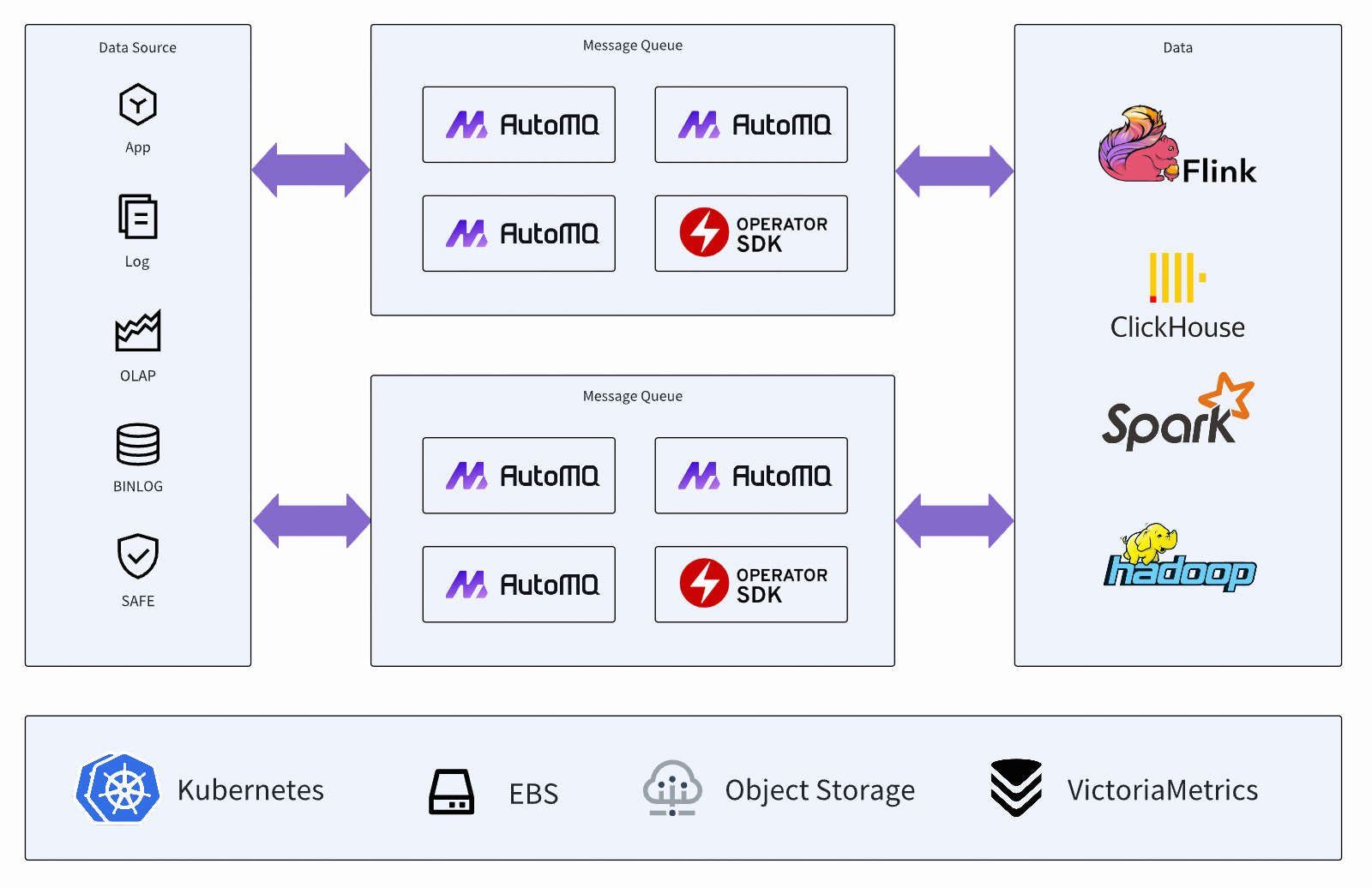
AutoMQ 在知乎大规模落地后,获得了如下的效果:
-
成本降低 80%:得益于 AutoMQ 的弹性架构,并充分撬动对象存储的成本优势,在已落地的业务场景,AutoMQ 相比较原 Apache Kafka 的集群成本降低了 80%。
-
无需维护独立的存储和计算资源池:借助于 AutoMQ 节点无状态特性可以分钟级切换 AutoMQ 集群的资源池,不需要再维护独立的静态存储机器资源池,进一步降低了资源的浪费。
-
更高的冷读带宽&消除了冷读读写入产生的副作用[2]:对象存储可以提供相比原来基于磁盘部署的 Kafka 集群更高的读取带宽,同时冷读不影响集群实时的写入流量。进一步提高了服务的稳定性。
-
无状态架构大幅度降低了运维成本:做好日常监控的情况下无额外运维成本,基于知乎自研的 K8s 的控制面配合 AutoMQ 的自动负载均衡能力无需人力过多参与运维。
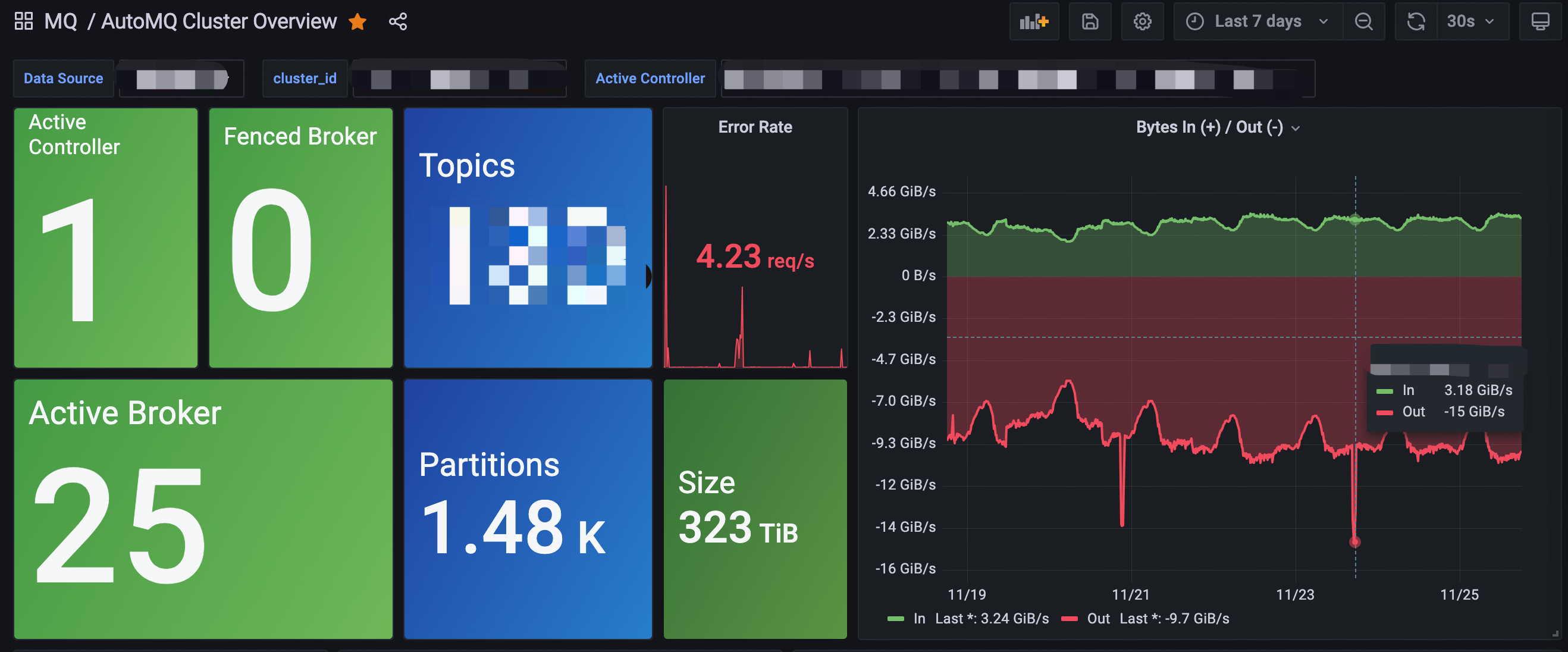
目前,知乎在基于裸金属自建的 K8s 集群上大规模部署了 AutoMQ ,集群承担的流量峰值近 20 GiB/s,如下图所示。
引用
[1] AutoMQ 基于 S3 的共享流存储库:https://docs.automq.com/zh/automq/architecture/s3stream-shared-streaming-storage/overview
[2] AutoMQ 冷热隔离架构& 5 倍冷读效率提升:https://docs.automq.com/zh/automq/architecture/technical-advantage/5x-catch-up-read-efficiency
这篇关于知乎启用AutoMQ替换Kafka,开辟成本优化与运维提效新纪元的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-21MQ-2烟雾传感器详解
- 2024-12-09Kafka消息丢失资料:新手入门指南
- 2024-12-07Kafka消息队列入门:轻松掌握Kafka消息队列
- 2024-12-07Kafka消息队列入门:轻松掌握消息队列基础知识
- 2024-12-07Kafka重复消费入门:轻松掌握Kafka消费的注意事项与实践
- 2024-12-07Kafka重复消费入门教程
- 2024-12-07RabbitMQ入门详解:新手必看的简单教程
- 2024-12-07RabbitMQ入门:新手必读教程
- 2024-12-06Kafka解耦学习入门教程
- 2024-12-06Kafka入门教程:快速上手指南



