我,00后,一个人维护着 6000 个数据库
2024/12/19 21:03:03

本文主要是介绍我,00后,一个人维护着 6000 个数据库,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
先抛出个问题:如果你不是专业的 DBA,能不能一个人管理六千多个数据库实例?
现在的基础架构是云计算和大规模分布式系统的天下,数据库作为业务系统的核心组件,其管理复杂性随着规模的增长而成倍增加。当你独自一人面临成千上万的数据库实例的管理任务时,第一反应可能是:这不可能!
但事实证明,这个 “不可能” 的任务,在 Sealos 平台上已经成为了现实。
接下来,我想和大家分享一个真实案例,讲述我们如何借助 Sealos 平台成功管理四个可用区、超过 6000 个数据库实例的实践经验。
管理大规模数据库的难点在哪?
传统上,管理如此庞大的数据库集群需要庞大的运维团队和复杂的自动化工具,稍有不慎还会引发性能瓶颈、数据丢失或服务中断等严重后果。资源分配、扩容备份、监控告警、权限管理等每一项任务都极为繁琐,更别提如何同时应对多租户、多数据库类型的需求。
在数据库规模从数十个扩展到数千个时,管理的复杂性会呈指数级增长。这种增长不仅体现在技术层面,也对运维团队的组织和工具提出了巨大的挑战。
规模化管理的难点在于:
- 数据库部署和维护的繁琐性 (比如版本管理、配置调整、扩容缩容等)。
- 异常处理的复杂性 (备份失败、主从同步延迟等)
- 高可用性和容灾难以保障 (数据库的高可用性依赖于复制、故障切换和数据备份的配合。然而,当实例数量达到数千时,任何一个组件出现问题,都可能影响全局)
- 运维复杂度成倍增加 (监控难度加大、手动操作不可行)
- 成本与效益的矛盾 (大规模数据库的运维,通常需要庞大的运维团队,人力资源成本又成为一大瓶颈)
面对这些挑战,传统的管理方式已经力不从心,必须通过新的技术手段和平台化工具来重新定义数据库管理流程。
Sealos 怎么做到的?
Sealos 数据库是一个强大且灵活的数据库管理平台,允许用户在 Sealos 上可视化地管理和使用各种数据库。并且提供了一整套高效的工具和机制,使数据库的管理、扩展、监控和故障恢复更加便捷和自动化,适合从开发到生产的各类场景。
Sealos 数据库具备以下功能:
- 支持丰富的数据库类型
- 高可用性与自动故障恢复
- 集成监控和告警系统
- 资源动态管理
- 灵活的数据备份与恢复机制
Sealos 数据库借助 KubeBlocks 作为底层,实现了自动化管理的核心特性。
KubeBlocks 的核心能力如下:
- 一键式部署:通过 CRD 和 Helm Chart 快速创建和配置数据库实例。
- 高可用架构:内置主从同步、自动故障切换支持。
- 备份与恢复:内置的备份策略和工具,支持 PITR (时间点恢复)。
Sealos 各个可用区数据库数量统计如下:
新加坡可用区

杭州可用区

广州可用区

北京可用区

国内自建机房可用区

Sealos 通过与各种工具的结合,使得数据库管理不再是繁重的工作,而是一种可以轻松驾驭的流程化操作。
细心的朋友可能已经发现,Sealos 所有可用区都是相互隔离的,每个可用区都有独立的域名,也不像其他云厂商那样拥有统一的控制台。想知道为什么,可以参考这篇文章:如何从架构层面降低公有云多可用区同时故障的概率
实现原理
看到这里,你可能会好奇 KubeBlocks 是如何在 Sealos 平台上提供稳定、高效的数据库服务的。接下来我们会深入探讨它的核心实现原理,包括其高可用架构设计以及完善的备份恢复机制。
KubeBlocks 架构设计
KubeBlocks 架构图如下所示:
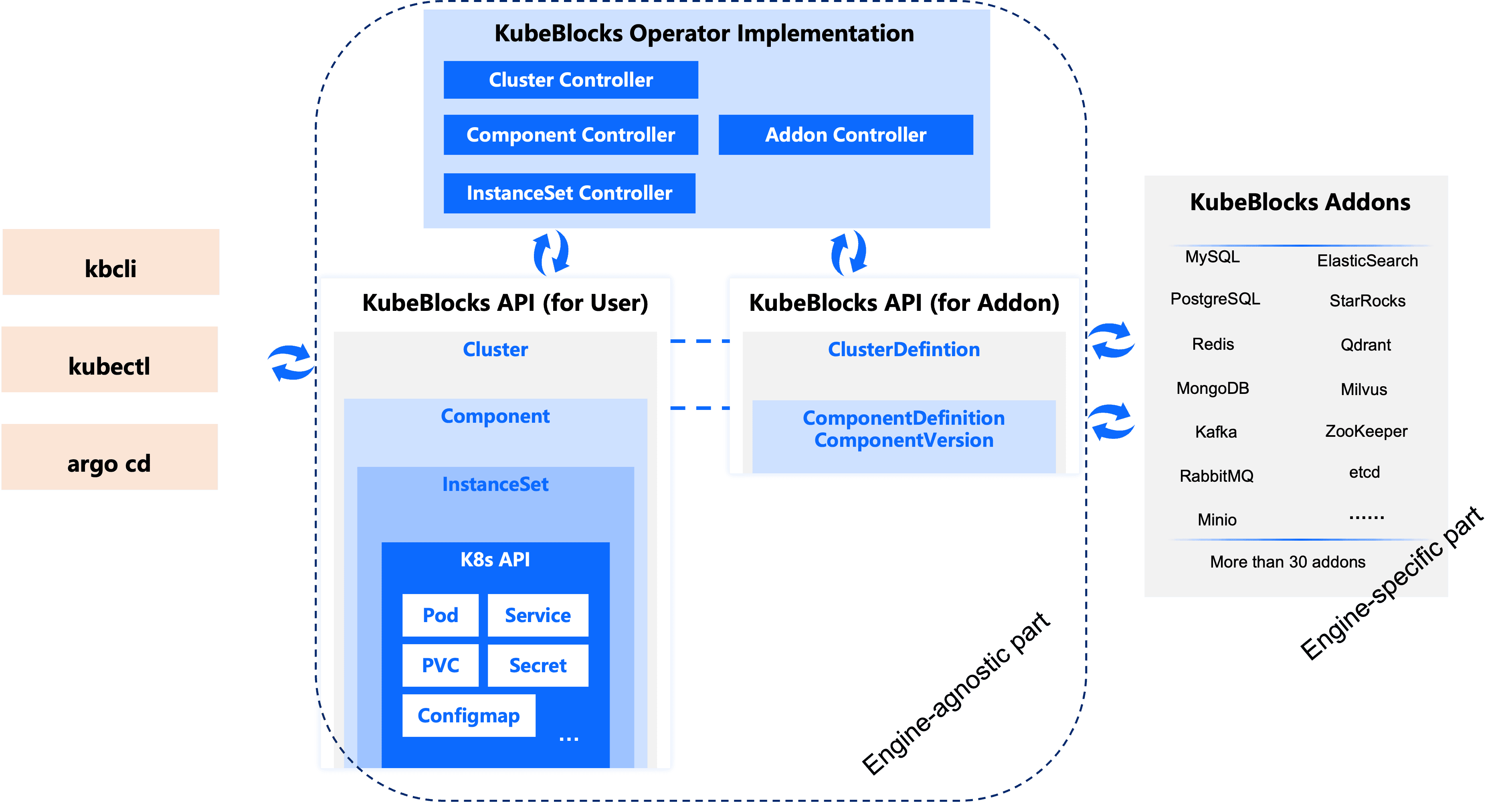
通过模块化的架构将复杂的操作简化。KubeBlocks提供用户友好的接口(kbcli、kubectl、Argo CD)与核心 API,支持超 30 种数据库和中间件插件。通过内置的控制器(如Cluster、Component、InstanceSet ),它让用户只需关注高层操作,而底层复杂逻辑则由 KubeBlocks 自动处理,极大地降低了技术门槛,非常适合想轻松管理数据库的小白用户。
高可用设计
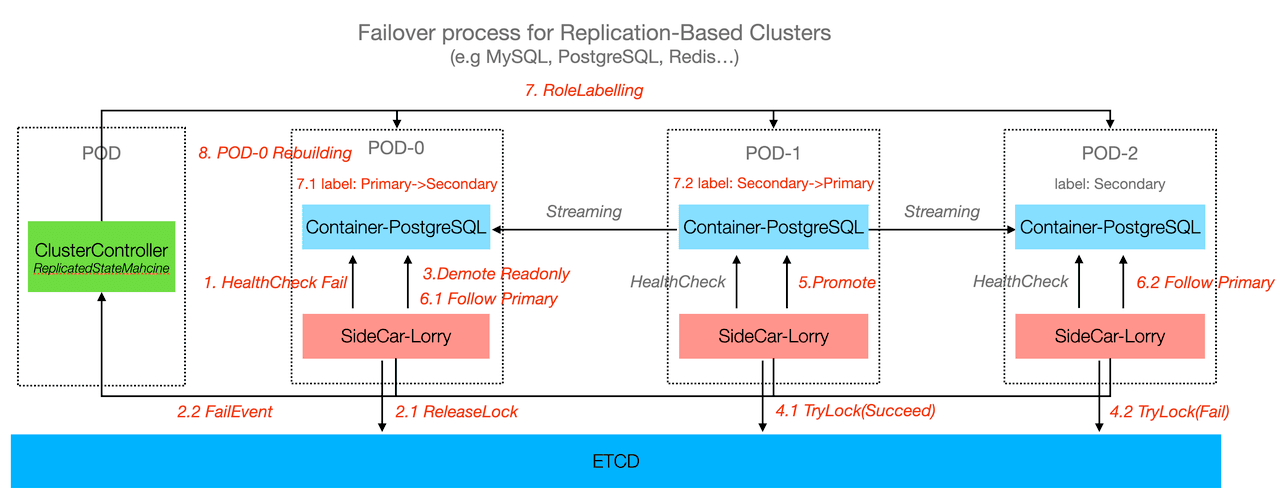
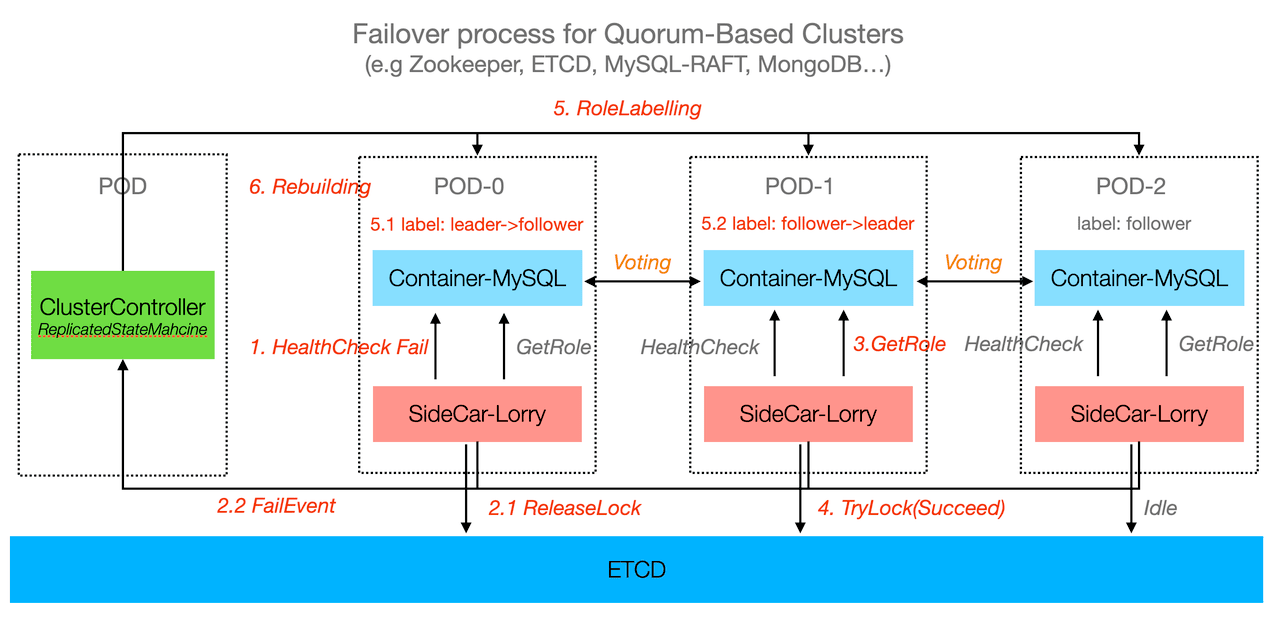
KubeBlocks 实现了两种高可用算法:quorum-based 和经典主备。
对于 quorum-based 类的数据库,KubeBlocks 提供了角色探测、角色校正和重建等功能,而数据库本身则负责更完整的探测、决策和切换等主体功能。
对于经典主备场景,如 MySQL 和 PostgreSQL 主备,KubeBlocks 负责执行完整的探测、决策、切换、重建和角色校正等任务。
KubeBlocks 高可用架构流程图如下所示:
此外,KubeBlocks 还采用通用的高可用架构,支持各种数据库类型,例如复制集群和分片集群,通过增加副本数量来提高可靠性和可用性,降低数据丢失的风险。例如:
- PostgreSQL:KubeBlocks 集成开源的 Patroni 方案实现高可用,并采用 Noop 作为切换策略。
- Redis:KubeBlocks 集成官方的 Redis Sentinel 方案,作为复制集群的高可用解决方案。在 KubeBlocks 提供的 RedisReplication Cluster 中,Sentinel 作为独立组件进行部署。
备份恢复设计
KubeBlocks 提供基于 BackupRepo 的备份和恢复功能,保障数据安全可靠。支持按需和计划两种备份方式,采用 物理备份 直接保存数据库物理文件(数据文件与日志文件)。
备份方式
- 按需备份:
- 备份工具:使用数据库自带工具(如 MySQL XtraBackup、PostgreSQL pg_basebackup)。
- 快照备份:依赖支持快照的云盘,速度更快。
- 计划备份:可定制保留时间、方法及执行时间,自动化执行备份任务。
物理备份特点
- 快速恢复:还原数据库至原始状态。
- 数据一致性:保障完整性。
- 存储高效:占用空间小,适合大规模数据库。
备份设计流程如下所示:
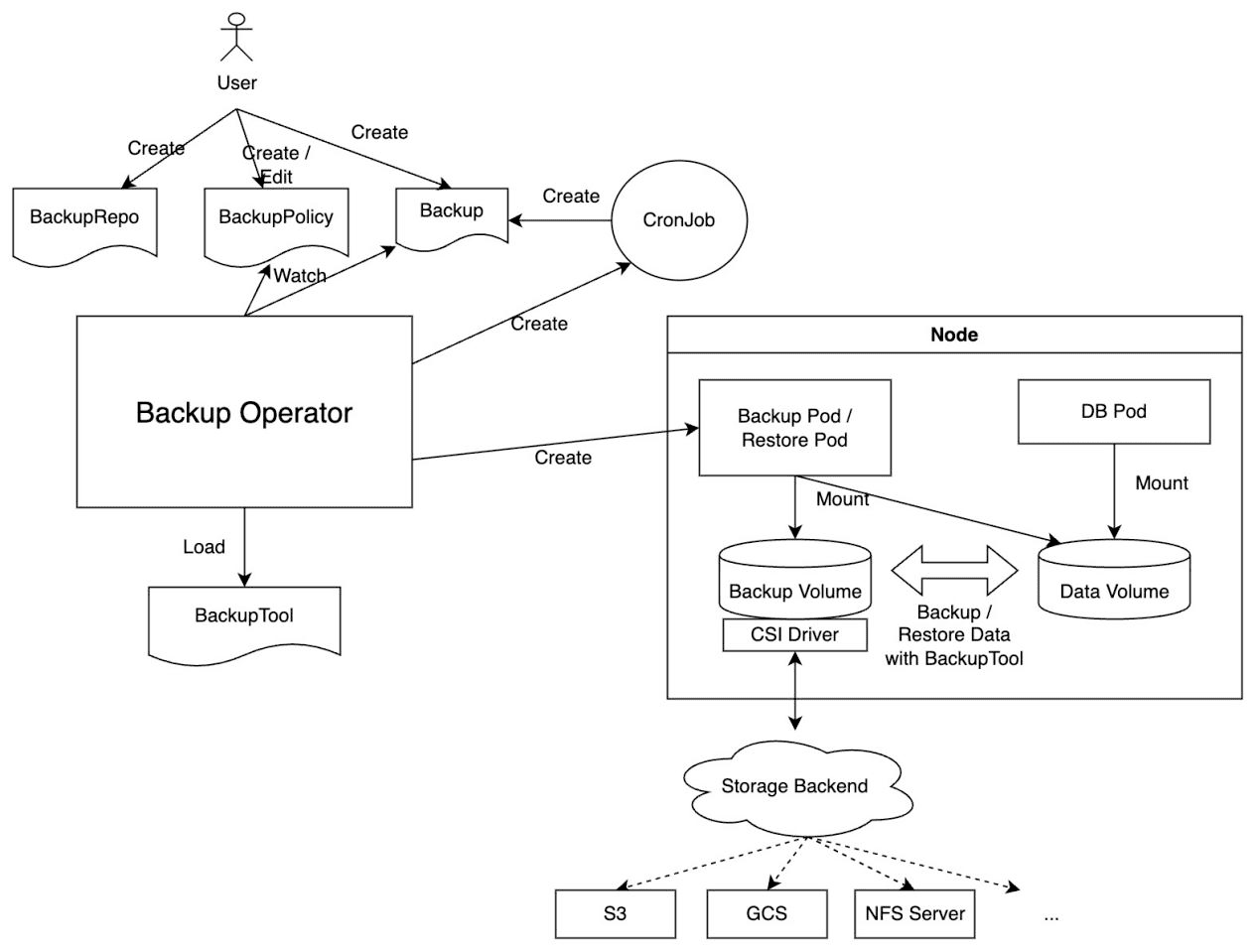
KubeBlocks 结合 Sealos 平台,提升了生产环境的数据保护能力,支持高效备份与恢复,适用于数据丢失、灾难恢复及数据迁移等需求。
迁移设计
Kubeblocks 使用开源工具 ape-dts 实现了数据库迁移流程。ape-dts 是一款通用的数据迁移工具,支持 任意数据库到任意数据库 的数据传输,同时支持 数据订阅 和 数据处理,适用于实时数据同步和离线迁移。
迁移流程图如下所示:
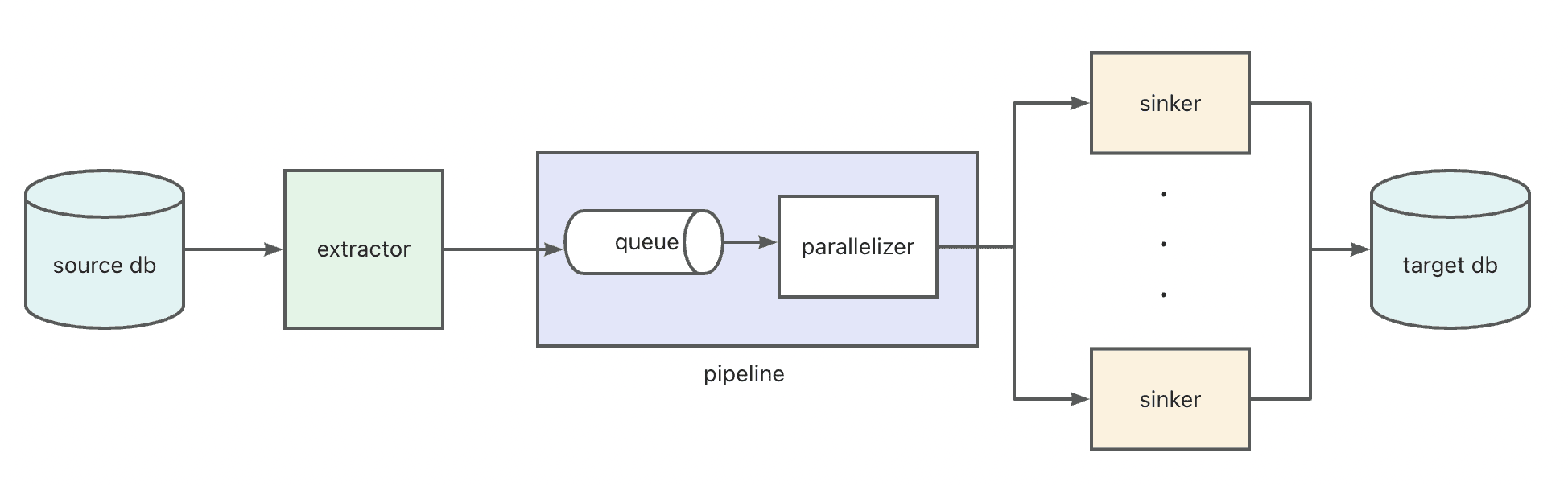
- 源数据库(Source DB):提供需要迁移的数据。
- 提取器(Extractor):从源数据库提取数据,包括全量数据和实时增量数据(CDC)。
- 数据传输管道(Pipeline):
- 队列(Queue):临时缓存提取数据,支持断点续传。
- 并行器(Parallelizer):并行处理数据任务,提高传输效率。
- 写入器(Sinker):将数据写入目标数据库。
- 目标数据库(Target DB):数据最终存储位置。
Sealos 数据库实践
创建数据库
首先打开浏览器,进入 Sealos Cloud,然后点击 “数据库”,进入数据库管理页面。
点击 “新建数据库”,在弹出的对话框中选择数据库类型、版本、cpu/内存/磁盘大小以及副本数。
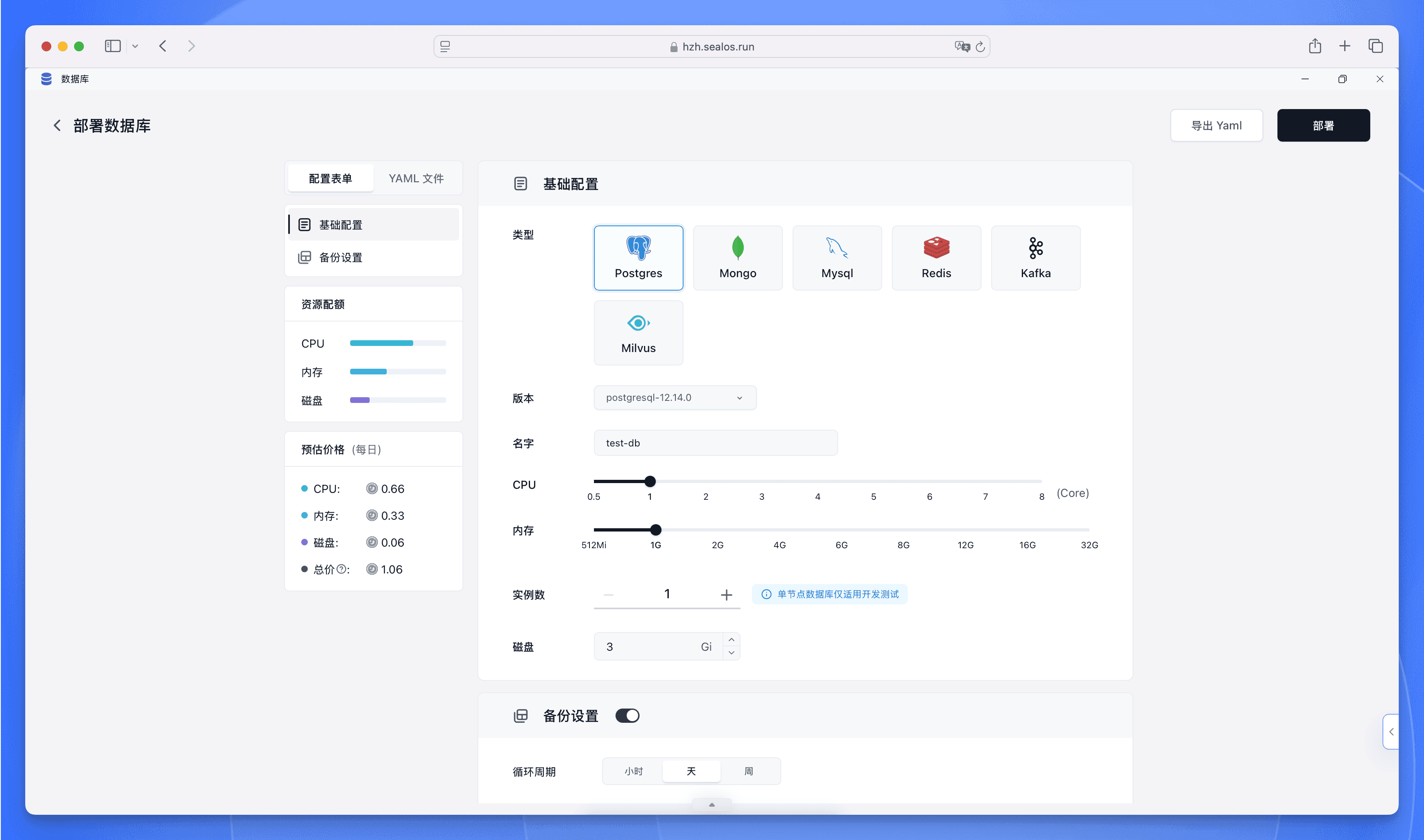
点击右上角的 “部署”,等待数据库实例创建完成。
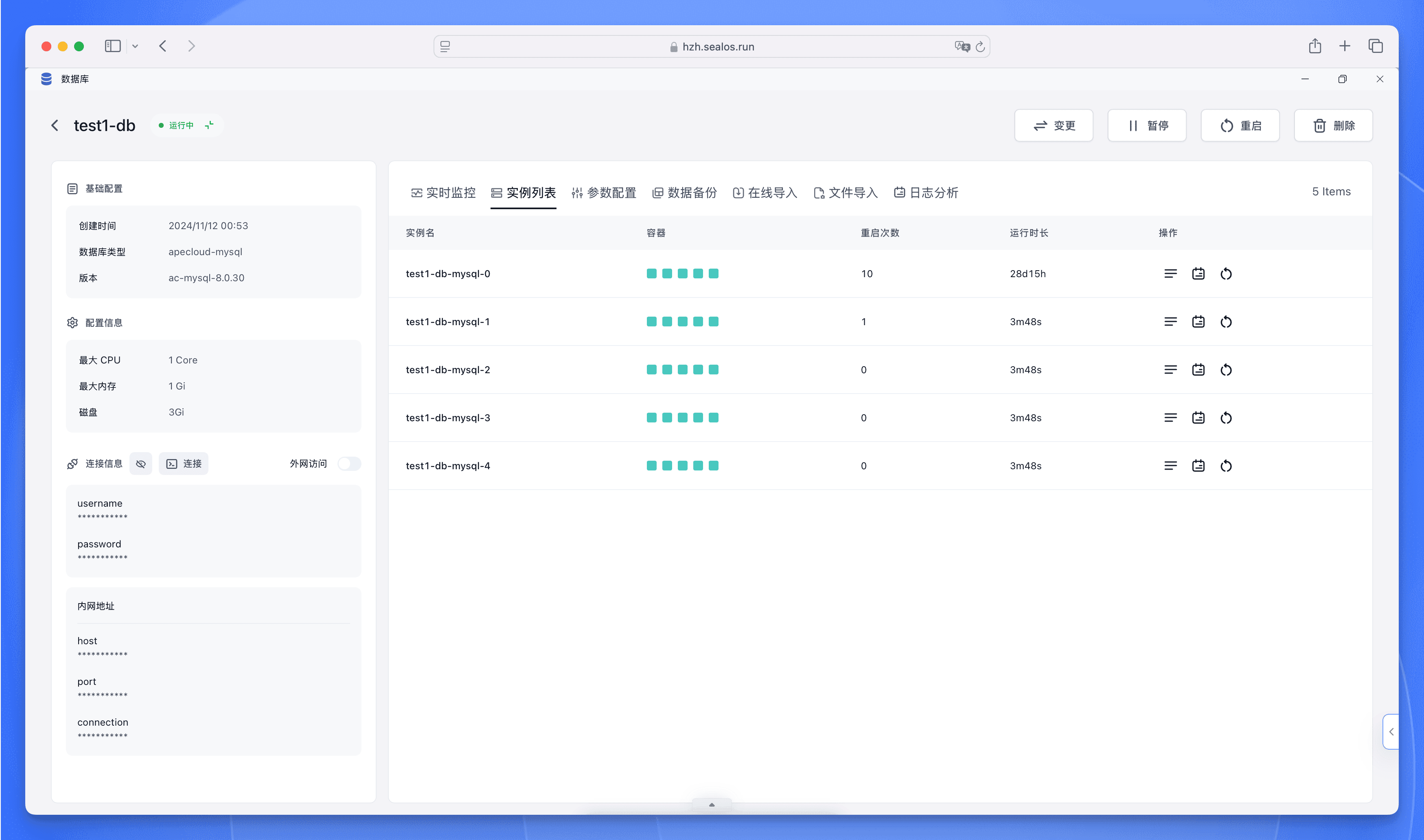
等到数据库状态变为 “运行中” 以后,点击 “详情”,进入数据库详情界面。
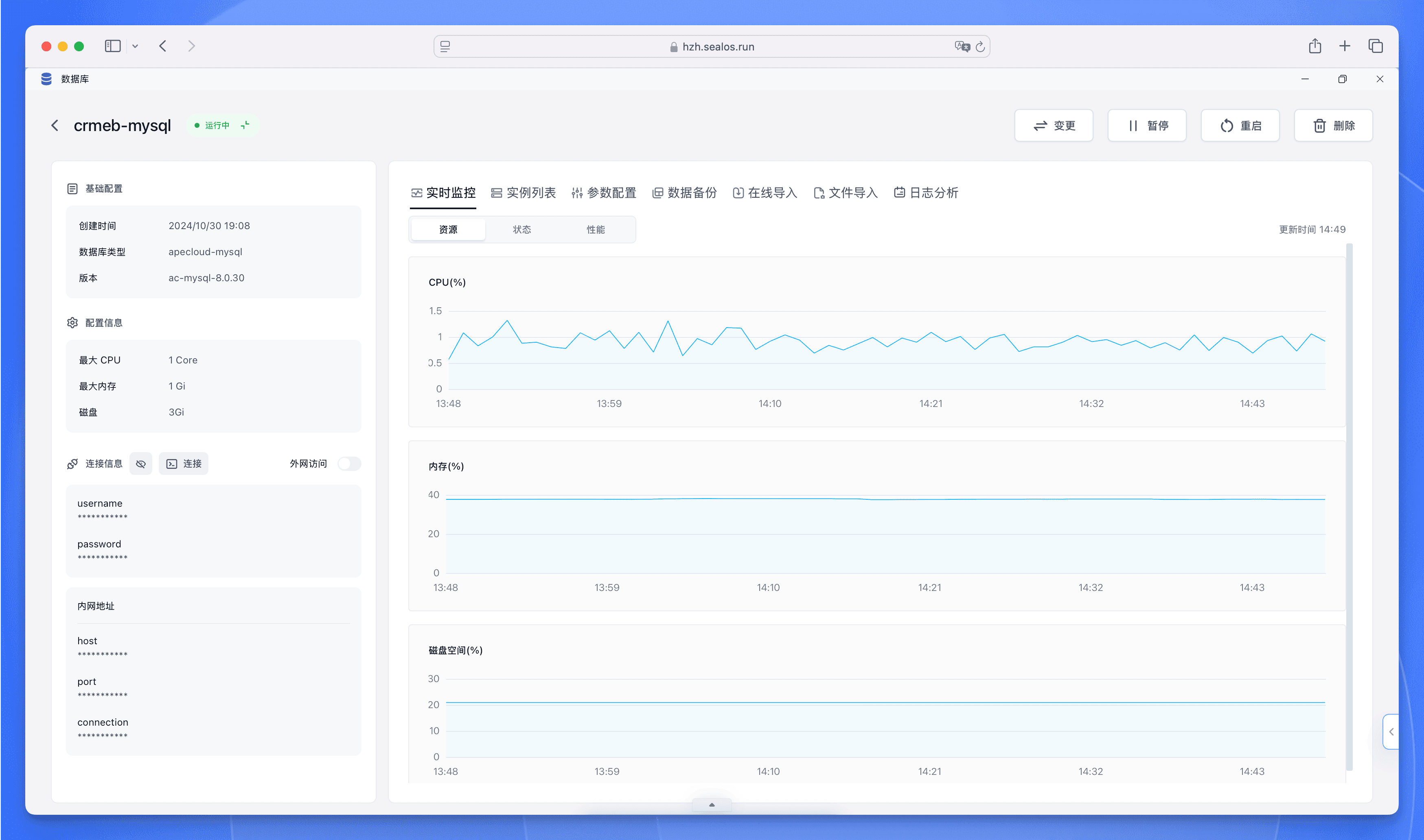
在数据库详情界面,可以查看数据库实时监控、日志信息、连接信息,并对数据库进行迁移和备份等高级操作。
连接数据库
有两种方法连接数据库:
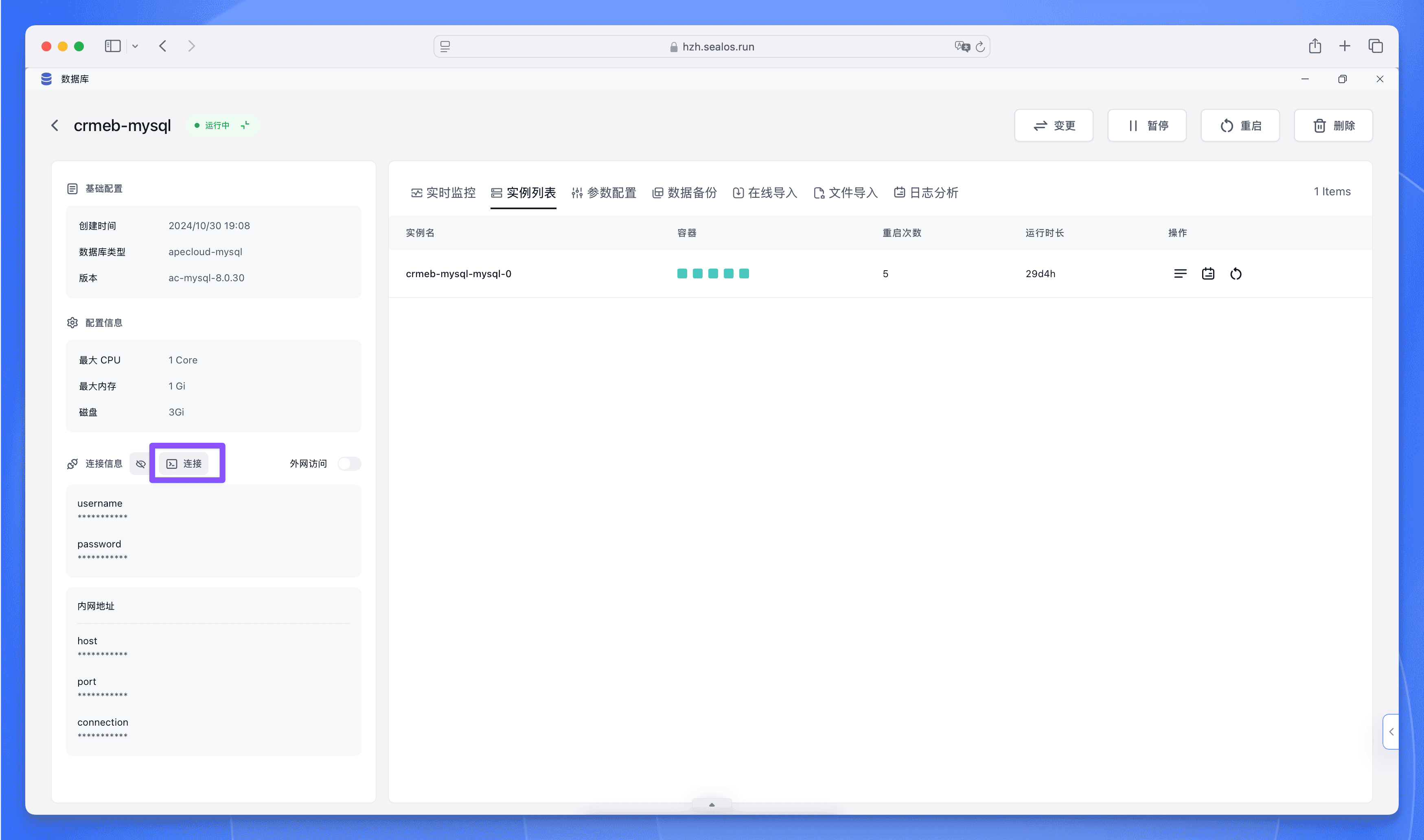
1. 内网直连
在数据库详情页面中,点击 “连接”:
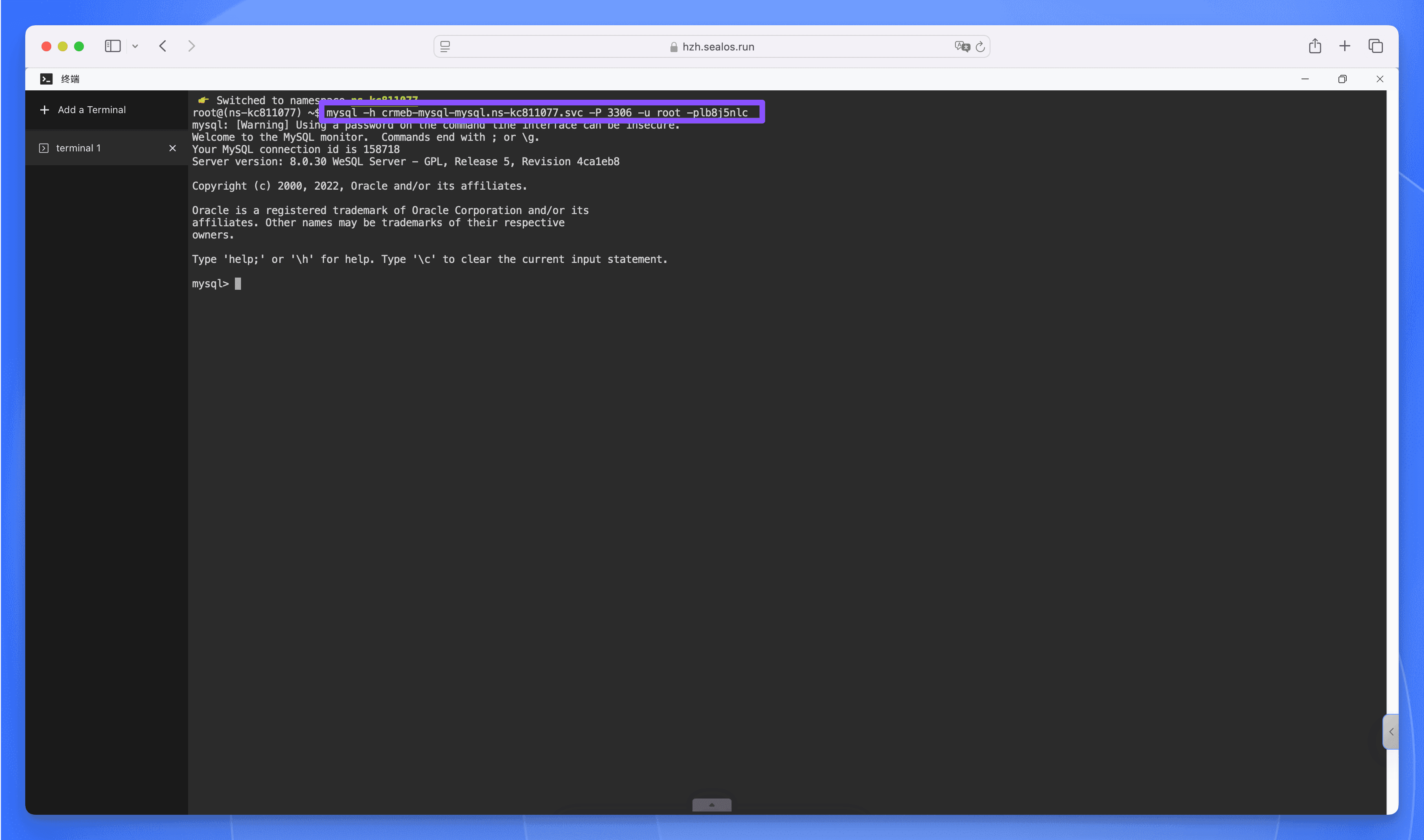
接下来会打开数据库服务所在容器的终端,并自动通过命令行工具进入数据库的终端。
当然,如果你是开发者,可以直接在 Devbox 开发环境中,通过内网直连的方式连接数据库。具体可参考这篇文章:Sealos Devbox 使用教程:使用 Cursor 一键搞定数据库开发环境
2. 公网访问
如果你想在 Sealos 云平台外部连接数据库,可以在数据库详情页面直接开启外网访问。
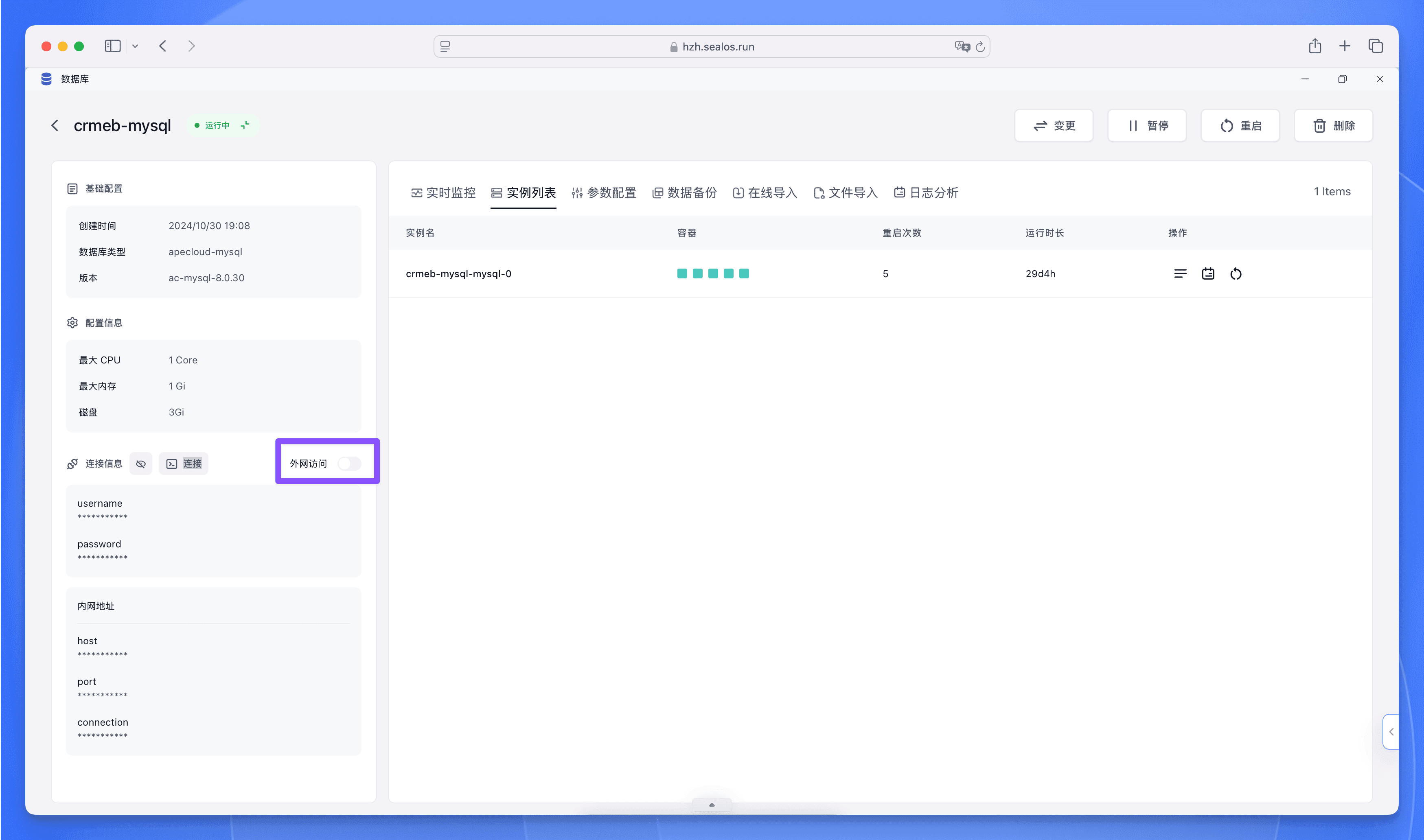
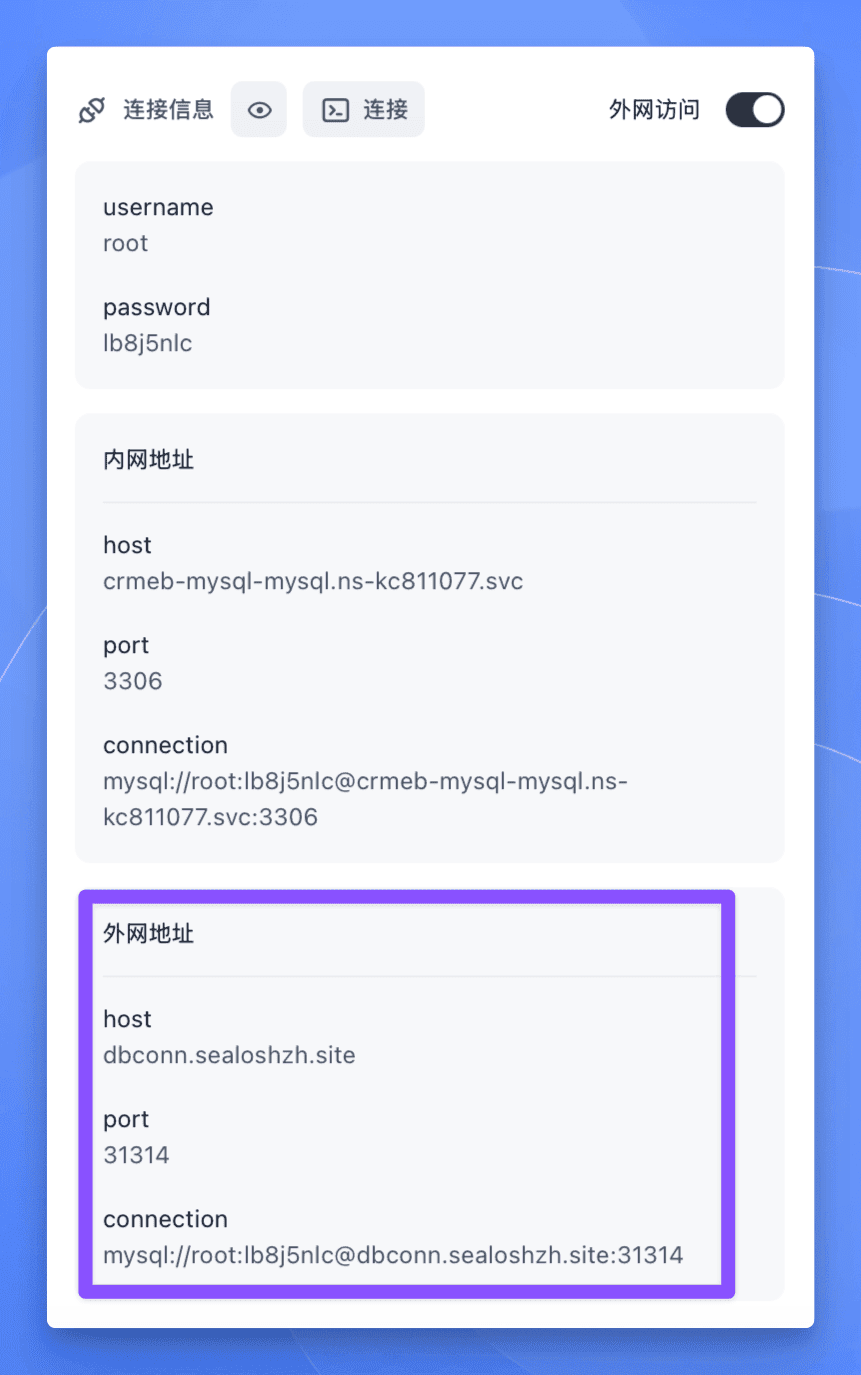
开启之后,连接信息中便会多出外网的连接信息。
除此之外,Sealos 数据库还支持备份、迁移、修改参数、扩缩容等各种操作,感兴趣的可以参考 Sealos 的官方文档。
总结
Sealos 让数据库管理变得更加简单高效,不仅节省了时间和成本,也显著降低了运维成本和复杂度。即使是大规模的数据库集群管理,也能做到轻松应对。无论你是开发者、数据工程师还是系统管理员,这个稳如老狗的数据库服务都能帮助你更高效地管理和运维你的数据。
这篇关于我,00后,一个人维护着 6000 个数据库的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-20DevOps与平台工程的区别和联系
- 2024-12-20从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南
- 2024-12-20手把手教你轻松部署网站
- 2024-12-20服务器购买课程:新手入门全攻略
- 2024-12-20动态路由表学习:新手必读指南
- 2024-12-20服务器购买学习:新手指南与实操教程
- 2024-12-20动态路由表教程:新手入门指南
- 2024-12-20服务器购买教程:新手必读指南
- 2024-12-20动态路由表实战入门教程
- 2024-12-20服务器购买实战:新手必读指南



