揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)
2024/12/22 21:03:10

本文主要是介绍揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一),对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
最近 Flink Forward Asia 2024 上海 开始之后,大数据圈子里面就特别热闹,流式湖仓、流批一体、Data + AI 各个名词被不断提起。这些概念几年前就有了,不是一个新的概念。但是大会里面提出了 Fluss:面向实时分析设计的下一代流存储
,这个设计理念让人有种眼前一亮,但是又听的云里雾里。
今天我们就对 Fluss 进行探讨一下,揭开这个组件的神秘面纱。
Fluss 解决的问题
基本概念
网上关于 Fluss 的资料很少,我去找 Fluss 的官方网站找了好一会才找到,在这里给大家分享一下 Fluss 官方网站地址:https://alibaba.github.io/fluss-docs/
在Flink Forward Asia 2024 分享会中 Apache Flink PMC 也解释了 Fluss 组件主要解决了哪些问题:
1.主要解决Kafka 在实时分析场景遇到的问题
2.为 Paimon 提供实时数据层
部署实战
根据官网提供的建议 Flink 1.18 版本、JDK11 以上,从官方网站提供的部署来看非常简单,为了快速上手体验一下 Fluss 的功能,我们先采用官方的 Deploying Local Cluster 部署。
Fluss 下载源码部署
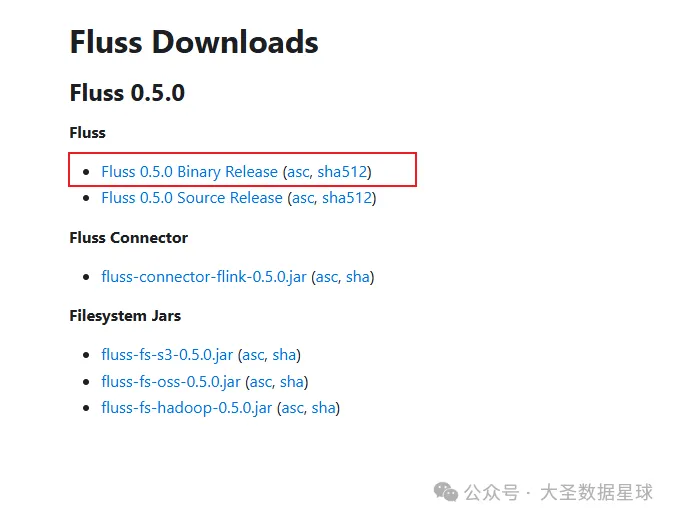
然后官方提供的部署步骤如下:
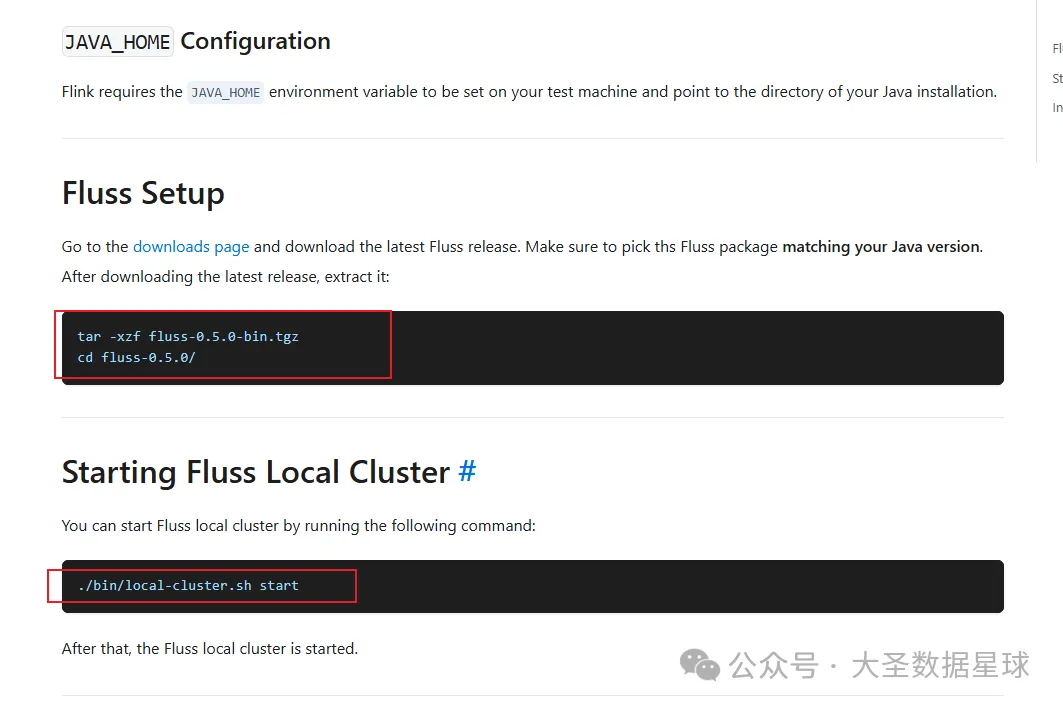
从这上面看超级简单,不愧是 Flink 家族出来的东西,写的部署文档和 Flink 部署文档一样简单明了。
当部署成功之后,会看到3个进程:
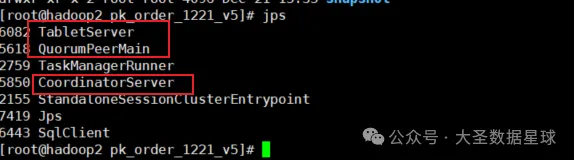
CoordinatorServer 是服务进程(主节点),TabletServer 是真正干活的节点,QuorumPeerMain 协调服务
Flink 端部署
Flink 端部署在这里就不说了,但是要把下面这个 jar 放到 flink lib 目录下面启动 Flink 集群即可。

实操
创建 CATALOG:
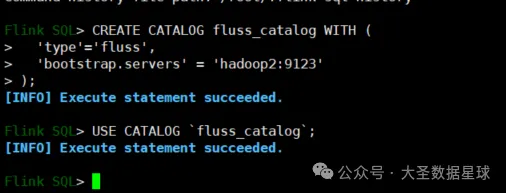
这里注意如果你的 Flinksql 和 Fluss 服务不在同一台机器的时候,需要把 Fluss conf 目录下的 server.yaml 配置文件里面三个配置改成你 Fluss 服务所在的主机名,如下图:
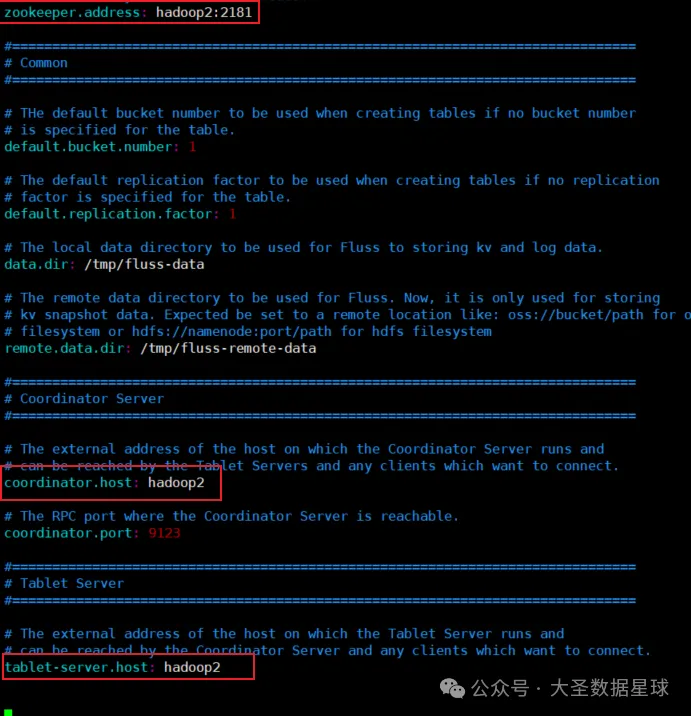
否则当你创建 CATALOG 的时候会报下面类似的错误:

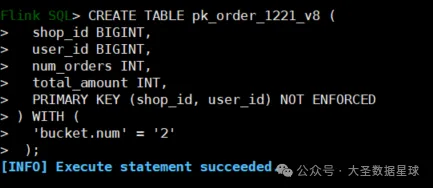
创建表:
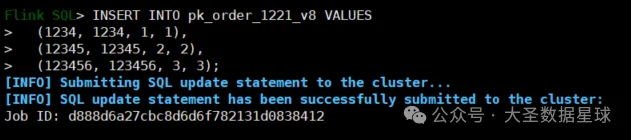
插入数据:
查询刚才插入的数据:

在这里可以看到查询刚才插入的数据表报错:Fluss only support queries on table with datalake enabled or point queries on primary key when it’s in batch execution mode.
这个的意思是,如果你的创建的表是数据湖表,是可以这样查询的。如果是普通表,就只能根据主键查询,我们上面创建表用的是 shop_id, user_id 联合主键,所以我们只能根据主键进行查询。
调整一下查询sql 语句如下:
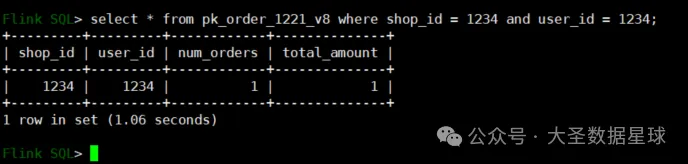
结果就查询出来了,体验到这里,直观感受这个 Fluss 就是给 Flink 做的一个数据库,用来数据读写和查询的。那为什么 Doris 这种 MPP 数据库不能做呢?
猜测可能是像现在 Doris 为代表的数据库是用来做数据分析的,一般能承受的并发都不高。
大家都知道 Kafka 得益于它的底层分区、索引、攒批、零拷贝技术,所以它非常适合高并发的场景,看来 Fluss 需要往这方面努力。
下篇文章会给大家带来实操 Flink 向 Fluss 写数据同时入数据湖的操作,这里面也有一些坑在里面。最后欢迎大家来讨论,一起探讨大数据技术。
这篇关于揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-20DevOps与平台工程的区别和联系
- 2024-12-20从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南
- 2024-12-20手把手教你轻松部署网站
- 2024-12-20服务器购买课程:新手入门全攻略
- 2024-12-20动态路由表学习:新手必读指南
- 2024-12-20服务器购买学习:新手指南与实操教程
- 2024-12-20动态路由表教程:新手入门指南
- 2024-12-20服务器购买教程:新手必读指南
- 2024-12-20动态路由表实战入门教程
- 2024-12-20服务器购买实战:新手必读指南



