揭秘:Fluss 与数据湖Paimon深度解析(一)
2025/1/2 21:03:14

本文主要是介绍揭秘:Fluss 与数据湖Paimon深度解析(一),对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
前段时间,我写过一篇关于 Fluss、Kafka 和 Paimon 数据湖的区别与联系 的文章。当时提到了一些 Fluss 和 Paimon 数据湖结合的内容,不过有些地方还不够深入。所以今天,我们专门来聊一聊 Fluss 和 Paimon 数据湖的深度结合。
先简单回顾一下 Fluss 的基本操作。如果你在 Flink 里创建一个 Fluss 表,并加上 'table.datalake.enabled' = 'true' 这个配置,就可以实现数据湖模式。例如,创建表时的配置如下图所示:
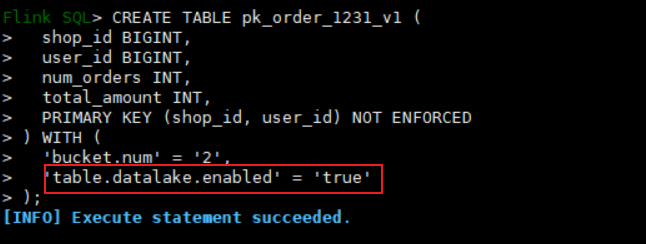
接下来,你需要用命令 ./bin/lakehouse.sh -D flink.rest.address=localhost -D flink.rest.port=8081 启动 Fluss 的 compact service 服务。有了这个服务支持,当你往 Fluss 表中写入数据时,这些数据会自动同步到你配置的 Paimon 数据湖。
这个流程听起来很简单,但当我第一次自己动手搭建 Fluss 数据入湖流程时,遇到了一些疑问:
-
如何查询 Paimon 数据湖中的数据?
-
如何查询 Fluss 和 Paimon 数据的“联合视图”?
-
如何只查询 Fluss 中的数据?
今天这篇文章就从这三个问题出发,带大家深入了解 Fluss 与 Paimon 数据湖的结合。此外,我还会聊聊 Fluss 提出的流批一体设计理念。在我看来,这个设计是未来实时数据分析领域的重要亮点。
接下来,让我们一步步拆解这些问题!
如何查询 Paimon 数据湖中的数据
这个 Fluss 官网写的有,如下图:
-- read from paimon SELECT COUNT(*) FROM orders$lake; -- we can also query the system tables SELECT * FROM orders$lake$snapshots;
大概的意思就是,如果 ordersKaTeX parse error: Expected 'EOF', got '这' at position 6: lake 这̲样查询,查询的就是基础文件,应…lake$snapshots 这个就是查询该表的全部数据(最全的数据)。同时上面这两种查询都完全继承 Paimon 表的所有功能,就像其他查询工具查询 Paimon 表一样的。
如何查询 Fluss 和 Paimon 数据的“联合视图
如果要利用 Fluss 和 Paimom 来读取全部的数据,按照下面的 sql 执行:
-- query will union data of Fluss and Paimon SELECT SUM(order_count) as total_orders FROM ads_nation_purchase_power;
此类查询可能比仅查询 Paimon 数据的速度稍慢,但它提供了更高的数据新鲜度。由于数据持续写入表中,每次运行查询时可能会得到不同的结果。
通过上述方法,您可以根据需求选择从 Paimon 或 Fluss+Paimon 中读取数据,以平衡数据新鲜度和分析性能。
其实看到这里我心里是有一个疑问的:*** 利用 Fluss 和 Paimom 来读取全部的数据***,这样查询出来的数据不会重复吗?具体看下面这样例子。
具体数据例子
1. 假设的场景
-
你有一张订单表
orders,在创建表时加了配置'table.datalake.enabled' = 'true'。- Fluss 会存储实时日志数据。
- Paimon 会存储经过合并后的稳定数据。
-
你往这张表中写入了以下三条数据:
- 数据 1:订单 ID = 001,金额 = 100,状态 = Pending。
- 数据 2:订单 ID = 002,金额 = 200,状态 = Confirmed。
- 数据 3:订单 ID = 003,金额 = 300,状态 = Shipped。
-
数据写入过程:
-
Fluss 日志存储:
Offset 1: 订单 ID = 001,金额 = 100,状态 = Pending Offset 2: 订单 ID = 002,金额 = 200,状态 = Confirmed Offset 3: 订单 ID = 003,金额 = 300,状态 = Shipped
-
Paimon 数据湖:
-
Fluss 的 Compact Service 将这些数据同步到 Paimon,Paimon 生成了一个快照:
快照 ID = 1: 订单 ID = 001,金额 = 100,状态 = Pending 订单 ID = 002,金额 = 200,状态 = Confirmed 订单 ID = 003,金额 = 300,状态 = Shipped
-
-
2. 查询数据的情况
查询类型:联合读取(Fluss + Paimon)
你运行以下查询,试图读取 Fluss 和 Paimon 的全部数据:
sqlSELECT * FROM orders;
理论上期望的结果:
订单 ID = 001,金额 = 100,状态 = Pending 订单 ID = 002,金额 = 200,状态 = Confirmed 订单 ID = 003,金额 = 300,状态 = Shipped
可能的问题:重复数据 由于 Fluss 和 Paimon 都存储了一份数据,联合读取时可能会出现重复:
订单 ID = 001,金额 = 100,状态 = Pending (Fluss) 订单 ID = 001,金额 = 100,状态 = Pending (Paimon) 订单 ID = 002,金额 = 200,状态 = Confirmed (Fluss) 订单 ID = 002,金额 = 200,状态 = Confirmed (Paimon) 订单 ID = 003,金额 = 300,状态 = Shipped (Fluss) 订单 ID = 003,金额 = 300,状态 = Shipped (Paimon)
但是经过实操查询出来的数据和期望的结果是一样的,如下图:
订单 ID = 001,金额 = 100,状态 = Pending
订单 ID = 002,金额 = 200,状态 = Confirmed
订单 ID = 003,金额 = 300,状态 = Shipped
去重的逻辑
为了避免联合读取 Fluss 和 Paimon 数据时出现重复,Fluss 设计了一套机制确保 数据一致性 和 去重。以下将通过详细的机制分析和具体的数据例子来说明 为什么需要记录 Offset,以及如何在读取时处理增量数据和主键去重。
1. 基于 Offset 的切换点
机制说明
- 为什么记录 Offset
- 当 Fluss 将数据同步到 Paimon 时,Paimon 会生成一个快照(Snapshot)。
- 每个快照对应 Fluss 的某个日志偏移量(Offset),这个 Offset 代表了 Fluss 日志被写入到 Paimon 的位置。
- 目的是为了区分哪些数据已经被写入 Paimon,哪些数据还仅存在于 Fluss 中。
- 如何使用 Offset
- 在联合读取时,Fluss 会先读取 Paimon 的快照数据,然后从 Fluss 日志中读取 Offset 大于快照记录的剩余增量数据。
举例说明
-
假设的数据写入情况:
-
Fluss 日志(实时流数据):
Offset 1: 订单 ID = 001,金额 = 100,状态 = Pending Offset 2: 订单 ID = 002,金额 = 200,状态 = Confirmed Offset 3: 订单 ID = 003,金额 = 300,状态 = Shipped
-
Paimon 快照数据(已合并数据):
快照 ID = 1: 订单 ID = 001,金额 = 100,状态 = Pending 订单 ID = 002,金额 = 200,状态 = Confirmed 订单 ID = 003,金额 = 300,状态 = Shipped
-
快照与 Offset 的映射:
快照 ID = 1 对应 Fluss Offset = 3
-
-
增量写入新数据:
-
新数据写入 Fluss 日志:
Offset 4: 订单 ID = 003,金额 = 300,状态 = Delivered Offset 5: 订单 ID = 004,金额 = 400,状态 = Pending
-
-
联合读取过程:
-
Fluss 读取 Paimon 数据(快照 ID = 1):
订单 ID = 001,金额 = 100,状态 = Pending 订单 ID = 002,金额 = 200,状态 = Confirmed 订单 ID = 003,金额 = 300,状态 = Shipped
-
Fluss 从日志读取增量数据(Offset > 3):
Offset 4: 订单 ID = 003,金额 = 300,状态 = Delivered Offset 5: 订单 ID = 004,金额 = 400,状态 = Pending
-
2. 主键去重
机制说明
- 为什么需要主键去重:
- 在联合读取中,同一条数据可能同时存在于 Paimon 和 Fluss 中(例如同一个订单 ID)。
- 主键去重的作用是确保每个主键只保留一条最新的记录,避免重复。
- 如何去重:
- Fluss 会以 Paimon 数据为基础,在读取 Fluss 日志时,基于主键去重:
- 如果 Fluss 的日志中存在 Offset > 3 的记录,它会覆盖 Paimon 中相同主键的记录。
- 最终结果是 主键唯一且数据最新。
- Fluss 会以 Paimon 数据为基础,在读取 Fluss 日志时,基于主键去重:
举例说明
-
主键冲突的场景:
-
Paimon 数据:
订单 ID = 001,金额 = 100,状态 = Pending 订单 ID = 002,金额 = 200,状态 = Confirmed 订单 ID = 003,金额 = 300,状态 = Shipped
-
Fluss 增量日志(Offset > 3):
Offset 4: 订单 ID = 003,金额 = 300,状态 = Delivered Offset 5: 订单 ID = 004,金额 = 400,状态 = Pending
-
-
去重后的结果:
-
Fluss 检测到
订单 ID = 003在 Paimon 和 Fluss 中都存在。 -
根据主键去重规则,使用 Fluss 中最新的记录覆盖 Paimon 中的记录:
最终结果: 订单 ID = 001,金额 = 100,状态 = Pending (Paimon) 订单 ID = 002,金额 = 200,状态 = Confirmed (Paimon) 订单 ID = 003,金额 = 300,状态 = Delivered (Fluss) 订单 ID = 004,金额 = 400,状态 = Pending (Fluss)
-
3. 为什么记录 Offset 是关键
通过记录 Offset,Fluss 能够实现以下功能:
区分已写入 Paimon 的数据和 Fluss 中的增量数据
- 避免重复读取相同的数据。
准确定位增量读取的起始位置
- 确保从 Fluss 日志读取的数据都是 Paimon 快照未覆盖的部分。
提高读取性能
- Paimon 的快照读取性能更高,Offset 切换点减少了对 Fluss 日志的依赖。
总结
Offset 切换点:
- Paimon 快照与 Fluss Offset 的映射是避免重复读取的核心。
- 在联合读取时,Paimon 提供稳定数据,Fluss 提供实时更新,二者结合提升实时性和一致性。
主键去重:
- 主键去重确保每个主键只保留最新的数据。
- 通过覆盖相同主键记录,保证数据的最终一致性。
最终结果: 联合读取的结果既包含 Paimon 的历史数据,也包含 Fluss 的实时更新,同时保证数据无重复、状态最新。
写在最后
写到这里,我又有了一个疑问,它这个查询最终查询了 Paimon 和 Fluss 两个系统,那怎么保证事务的呢?这个我们放在下一篇文章来说。还有这篇文章的第三个问题,也会放在下一篇文章继续说清楚的。欢迎大家一起来讨论大数据技术,关注 大圣数据星球 微信公众号带你搞定数据开发不迷路。
这篇关于揭秘:Fluss 与数据湖Paimon深度解析(一)的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2025-01-04如何利用AI看板工具提升团队协作效率?10大深度评测与实用技巧
- 2025-01-03带有自反功能的自适应检索增强生成系统
- 2025-01-03FAISS向量数据库在生产LLM应用中的使用指南
- 2025-01-03掌握RAG:深入探讨文本分割技巧
- 2025-01-03深入探究结构化输出的应用技巧
- 2025-01-03因果推断的基本问题:现代视角下的统计挑战
- 2025-01-03预测的艺术:预AI时代的滤波技术讲解
- 2025-01-03OpenAI 新模型“草莓”来袭,o1-preview版本抢先看!
- 2025-01-03利用知识图谱和大模型提升元数据管理的思考与实践(上篇)
- 2025-01-03llama 3.1 — 技术规格和代码解析



