入门学Python一定要知道的requests模块安装及使用
2021/8/24 8:05:39

本文主要是介绍入门学Python一定要知道的requests模块安装及使用,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
主要学习requests这个http模块,该模块主要用于发送请求获取响应,该模块有很多的替代模块,比如说urllib模块,但是在工作中用的最多的还是requests模块,requests的代码简洁易懂,相对于臃肿的urllib模块,使用requests编写的爬虫代码将会更少,而且实现某一功能将会简单。因此建议大家掌握该模块的使用。
requests模块
我们来学习如何在代码中实现我们的爬虫
1. requests模块介绍
requests文档http://docs.python-requests.org/zh_CN/latest/index.html
** 1.1 requests模块的作用:**
发送http请求,获取响应数据
1.2 requests模块是一个第三方模块,需要在你的python(虚拟)环境中额外安装
pip/pip3 install requests
1.3 requests模块发送get请求
需求:通过requests向百度首页发送请求,获取该页面的源码 运行下面的代码,观察打印输出的结果
1.2.1-简单的代码实现
import requests
目标url
url = 'www.baidu.com'
向目标url发送get请求
response = requests.get(url)
打印响应内容
print(response.text)
知识点:掌握 requests模块发送get请求 2\. response响应对象 ----------------
观察上边代码运行结果发现,有好多乱码;这是因为编解码使用的字符集不同早造成的;我们尝试使用下边的办法来解决中文乱码问题
# 1.2.2-response.content import requests # 目标url url = 'https://www.baidu.com' # 向目标url发送get请求 response = requests.get(url) # 打印响应内容 # print(response.text) print(response.content.decode()) # 注意这里!
1.response.text是requests模块按照chardet模块推测出的编码字符集进行解码的结果
2.网络传输的字符串都是bytes类型的,所以response.text = response.content.decode('推测出的编码字符集')
3.我们可以在网页源码中搜索charset,尝试参考该编码字符集,注意存在不准确的情况
**2.1 response.text 和response.content的区别:**
response.text
类型:str 解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
response.content
类型:bytes 解码类型: 没有指定
**2.2 通过对response.content进行decode,来解决中文乱码**
response.content.decode() 默认utf-8
response.content.decode("GBK")
常见的编码字符集
* utf-8 * gbk * gb2312 * ascii (读音:阿斯克码) * iso-8859-1 **2.3 response响应对象的其它常用属性或方法** > response = requests.get(url)中response是发送请求获取的响应对象;response响应对象中除了text、content获取响应内容以外还有其它常用的属性或方法:
response.url响应的url;有时候响应的url和请求的url并不一致
response.status_code 响应状态码
response.request.headers 响应对应的请求头
response.headers 响应头
response.request._cookies 响应对应请求的cookie;返回cookieJar类型
response.cookies 响应的cookie(经过了set-cookie动作;返回cookieJar类型
response.json()自动将json字符串类型的响应内容转换为python对象(dict or list)
# 1.2.3-response其它常用属性 import requests # 目标url url = 'https://www.baidu.com' # 向目标url发送get请求 response = requests.get(url) # 打印响应内容 # print(response.text) # print(response.content.decode()) # 注意这里! print(response.url) # 打印响应的url print(response.status_code) # 打印响应的状态码 print(response.request.headers) # 打印响应对象的请求头 print(response.headers) # 打印响应头 print(response.request._cookies) # 打印请求携带的cookies print(response.cookies) # 打印响应中携带的cookies ``` 3\. requests模块发送请求 ------------------ **3.1 发送带header的请求** ``` 我们先写一个获取百度首页的代码
import requests
url = 'www.baidu.com'
response = requests.get(url)
print(response.content.decode())
打印响应对应请求的请求头信息
print(response.request.headers)
**3.1.1 思考**
对比浏览器上百度首页的网页源码和代码中的百度首页的源码,有什么不同?
查看网页源码的方法: 右键-查看网页源代码 或 右键-检查
对比对应url的响应内容和代码中的百度首页的源码,有什么不同?
查看对应url的响应内容的方法: 右键-检查 点击 Net work 勾选 Preserve log 刷新页面 查看Name一栏下和浏览器地址栏相同的url的Response
代码中的百度首页的源码非常少,为什么?
需要我们带上请求头信息 回顾爬虫的概念,模拟浏览器,欺骗服务器,获取和浏览器一致的内容 请求头中有很多字段,其中User-Agent字段必不可少,表示客户端的操作系统以及浏览器的信息
**3.1.2 携带请求头发送请求的方法** requests.get(url, headers=headers)
headers参数接收字典形式的请求头
请求头字段名作为key,字段对应的值作为value
**3.1.3 完成代码实现**
从浏览器中复制User-Agent,构造headers字典;完成下面的代码后,运行代码查看结果
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
print(response.content)
# 打印请求头信息
print(response.request.headers)
```
**3.2 发送带参数的请求**
```
我们在使用百度搜索的时候经常发现url地址中会有一个 ?,那么该问号后边的就是请求参数,又叫做查询字符串
```
3.2.1 在url携带参数
直接对含有参数的url发起请求
```
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=python'
response = requests.get(url, headers=headers)
```
**3.2.2 通过params携带参数字典**
1.构建请求参数字典
2.向接口发送请求的时候带上参数字典,参数字典设置给params
```
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 这是目标url
# url = 'https://www.baidu.com/s?wd=python'
# 最后有没有问号结果都一样
url = 'https://www.baidu.com/s?'
# 请求参数是一个字典 即wd=python
kw = {'wd': 'python'}
# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)
print(response.content)
```
**3.3 在headers参数中携带cookie**
```
网站经常利用请求头中的Cookie字段来做用户访问状态的保持,那么我们可以在headers参数中添加Cookie,模拟普通用户的请求。我们以github登陆为例:
```
**3.3.1 github登陆抓包分析**
```
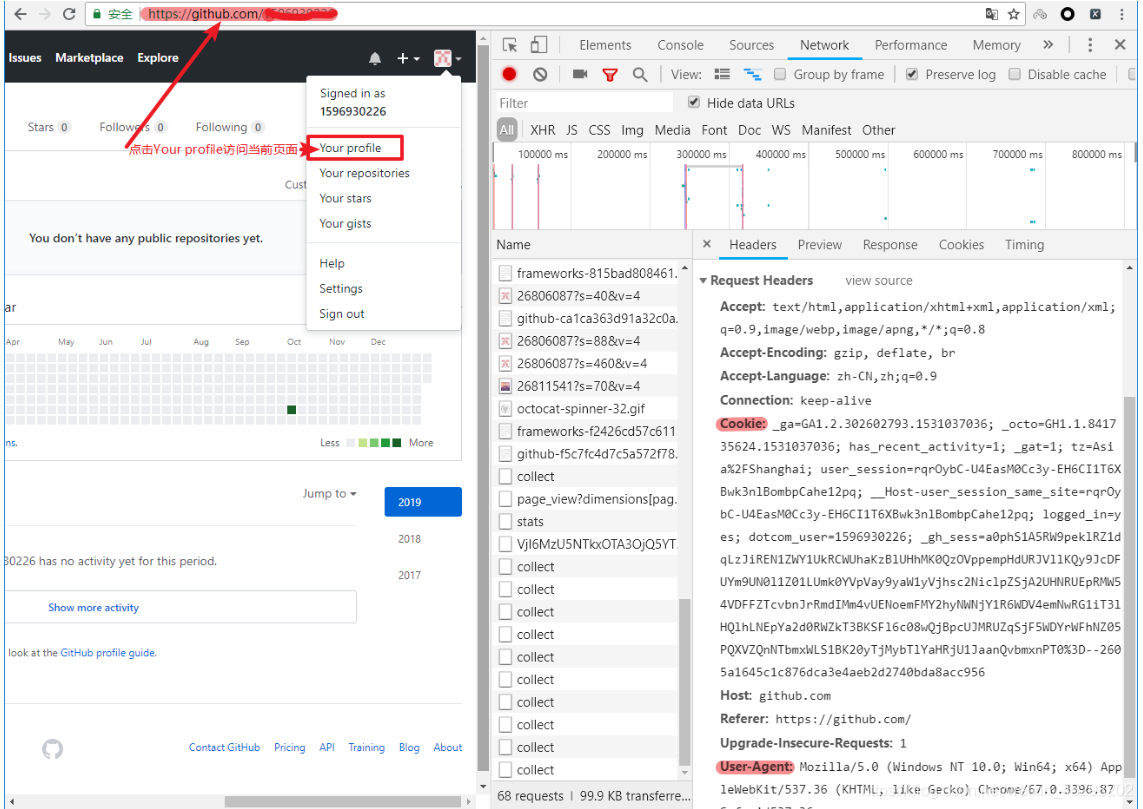
打开浏览器,右键-检查,点击Net work,勾选Preserve log
访问github登陆的url地址 https://github.com/login
输入账号密码点击登陆后,访问一个需要登陆后才能获取正确内容的url,比如点击右上角的Your profile访问https://github.com/USER_NAME
确定url之后,再确定发送该请求所需要的请求头信息中的User-Agent和Cookie
```
**3.3.2 完成代码**
```
从浏览器中复制User-Agent和Cookie
浏览器中的请求头字段和值与headers参数中必须一致
headers请求参数字典中的Cookie键对应的值是字符串import requests
url = 'github.com/USER_NAME'
构造请求头字典
headers = { # 从浏览器中复制过来的User-Agent 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36', # 从浏览器中复制过来的Cookie 'Cookie': 'xxx这里是复制过来的cookie字符串' }
请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers)
print(resp.text)
**3.3.3 运行代码验证结果**
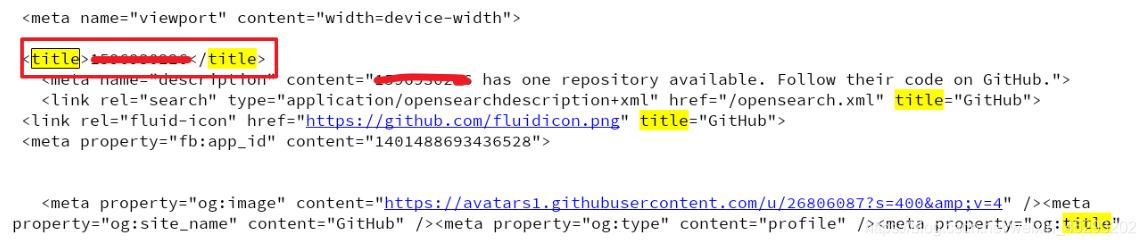
在打印的输出结果中搜索title,html中的标题文本内容如果是你的github账号,则成功利用headers参数携带cookie,获取登陆后才能访问的页面
 知识点:掌握 headers中携带cookie **3.4 cookies参数的使用**
上一小节我们在headers参数中携带cookie,也可以使用专门的cookies参数
cookies参数的形式:字典
cookies = {"cookie的name":"cookie的value"}
该字典对应请求头中Cookie字符串,以分号、空格分割每一对字典键值对 等号左边的是一个cookie的name,对应cookies字典的key 等号右边对应cookies字典的value
cookies参数的使用方法
response = requests.get(url, cookies)
将cookie字符串转换为cookies参数所需的字典:
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
注意:cookie一般是有过期时间的,一旦过期需要重新获取
import requests
url = 'https://github.com/USER_NAME'
# 构造请求头字典
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'
}
# 构造cookies字典
cookies_str = '从浏览器中copy过来的cookies字符串'
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers, cookies=cookies_dict)
print(resp.text)
```
知识点:掌握 cookies参数的使用
**3.5 cookieJar对象转换为cookies字典的方法**
```
使用requests获取的resposne对象,具有cookies属性。该属性值是一个cookieJar类型,包含了对方服务器设置在本地的cookie。我们如何将其转换为cookies字典呢?
转换方法
cookies_dict = requests.utils.dict_from_cookiejar(response.cookies)
其中response.cookies返回的就是cookieJar类型的对象
requests.utils.dict_from_cookiejar函数返回cookies字典
作者:白又白i
链接:https://juejin.cn/post/6999135569322180621
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这篇关于入门学Python一定要知道的requests模块安装及使用的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-28Python编程基础教程
- 2024-12-27Python编程入门指南
- 2024-12-27Python编程基础
- 2024-12-27Python编程基础教程
- 2024-12-27Python编程基础指南
- 2024-12-24Python编程入门指南
- 2024-12-24Python编程基础入门
- 2024-12-24Python编程基础:变量与数据类型
- 2024-12-23使用python部署一个usdt合约,部署自己的usdt稳定币
- 2024-12-20Python编程入门指南



