哪个主播颜值最高?利用Python采集主播照片,检测颜值后制作排行榜,一目了然!
2021/9/1 14:06:22

本文主要是介绍哪个主播颜值最高?利用Python采集主播照片,检测颜值后制作排行榜,一目了然!,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
目录
前言
开始
分析(x0)
分析(x1)
采集的Python代码
采集的效果
颜值检测函数构造
facerg.py
排序源码
结果演示
完整的所有源码
视频教程地址
我有话说
前言
大家好,我叫善念。这是连续更新Python爬虫实战案例的第七天,感觉很多的东西不怎么好写,也不知道该写什么案例了。
大家可以反馈给我一下想要采集哪个网站,或者需要post哪些网站的功能,或脚本、或一些基础知识的讲解。
好好写文章,拒绝各种表情包二改别人文章,每一篇都现写的原创干货,没那么多时间去耍嘴皮子逗你们开心。
开始
目标网站:某鱼的颜值主播
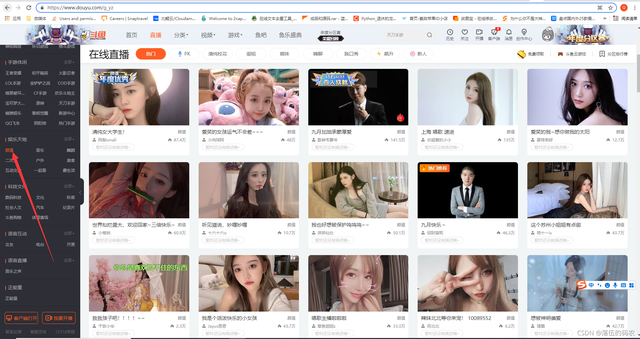
好吧,万万没想到还有几个男同胞......
咱们需要的东西就很简单了,采集封面图然后进行颜值检测 ,对检测出来的分数进行排名即可。
分析(x0)
简单地查看了一下网页的元素,可以看到咱们需要的图片在li标签的img标签的src属性中。而每一个li标签都包含了一个主播的信息。
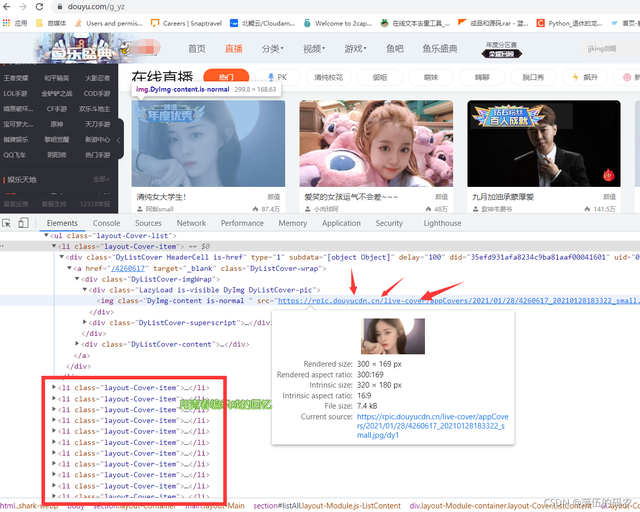
我多次讲过像这种图片的加载,极有可能是动态加载,就是当咱们拉动下滑条的时候图片会自动刷新出来,就跟上期的【Python】完美采集某宝数据,到底A和B哪个是YYDS?(附完整源代码和视频教程)是一样的。
那么如何看出来它是否是动态加载的呢?
1.教大家一个可以肉眼可查的方法,那就是直接手动快速拉动浏览器的下滑条,你会发现很多的图片加载需要时间,刚出现的时候是一个白板,然后才加载出图像!
2.那就是直接查看网页元素,如果是动态加载,而咱们的浏览器目前还没有往下面滑,就说明下面的图片肯定是没加载出来的。
那么咱们直接看看后面的li标签中是否有咱们的图片数据:
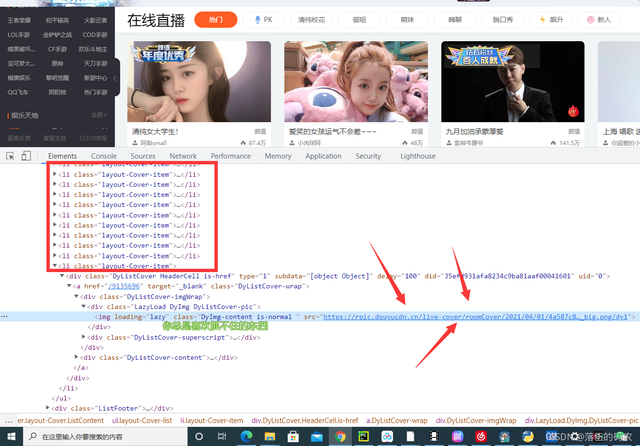
明显这个图的格式都不一样,是打不开的,也就是个白板图。
好吧那就说明这个又是个动态加载的网站,那么咱们就开始抓包。
分析(x1)
刷新一下网页就抓到包了,可以看到这个东西呢它有rs1和rs6两个图,rs1是大图另外一个是小图,想采集哪个都行。我这里采集大图。
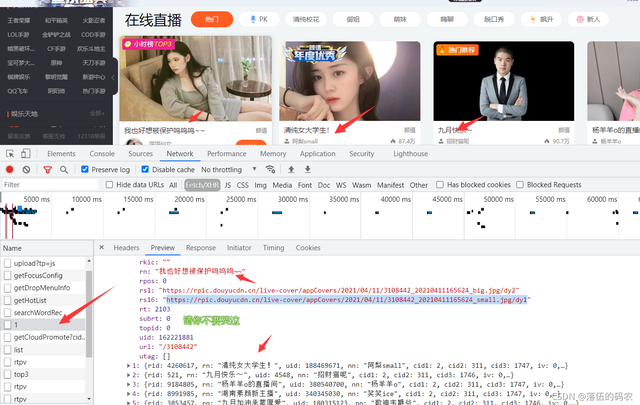
分析一下这个请求,是个get请求,说实话我都没想到是get,那么就有点特殊的了,我们前面只分析了网页元素,按道理咱们需要的数据在网页源代码中应该同样有......不过也没关系,自己去看看就好了,也不建议从源代码中去获取数据。
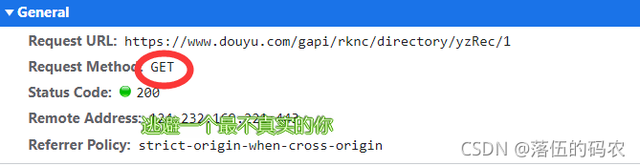
理由就是:可以看到第二页与第一页的网页url是没发生变化的发现没?如果说你从网页源码中去获取,那么你可以获取到第二页的数据,第一页该如何获取呢?所以说千万别从网页源代码中去提取数据。咱们没办法去构造url。

而你如果是包就很容易分析出,只需要把url后面的1改成2就是第二页了,这点敏锐大家还是具备的吧?不相信抓下包就可以了。
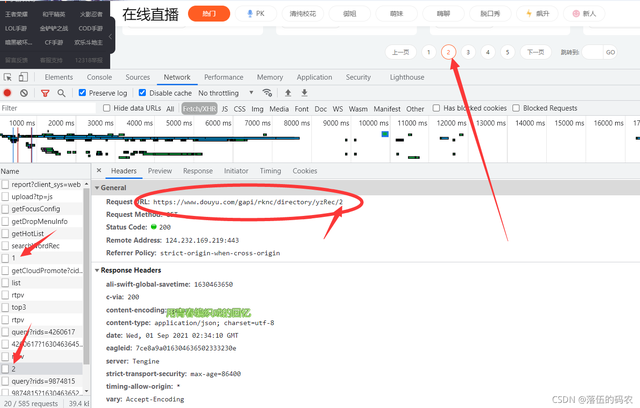
是的吧,多页采集的话构造下url即可 。
采集的Python代码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
if not os.path.exists('./pic'):
os.mkdir('./pic')
for i in range(1, 100000):
try:
url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
r = requests.get(url, headers=headers)
names = jsonpath.jsonpath(r.json(), '$..nn')
pngs = jsonpath.jsonpath(r.json(), '$..rs1')
for name, png in zip(names, pngs):
urlretrieve(png, './pic' + '/' + name + '.png')
print(names)
print(pngs)
except:
exit()
采集的效果
颜值检测函数构造
注册百度智能云:地址
按图去选择咱们需要的服务:
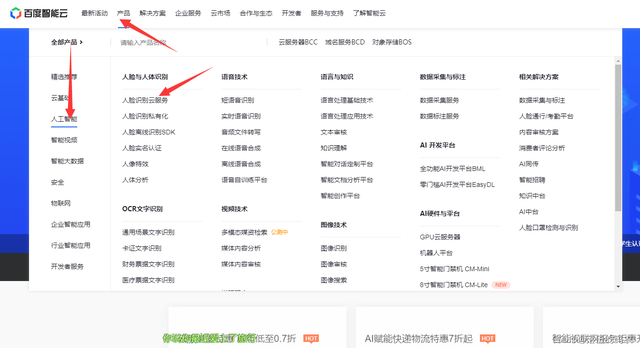
自己看下技术文档:
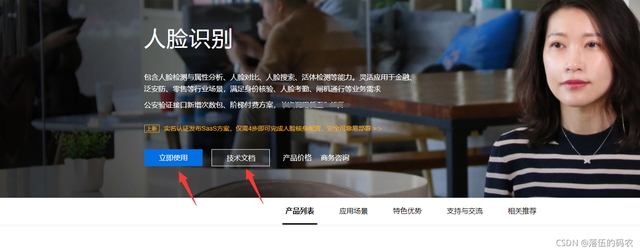
点击立即使用——创建应用:
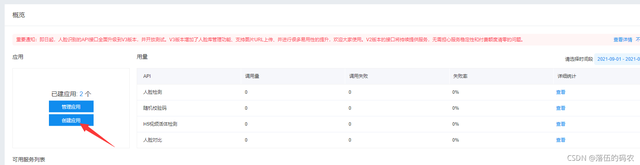
正常填写就好
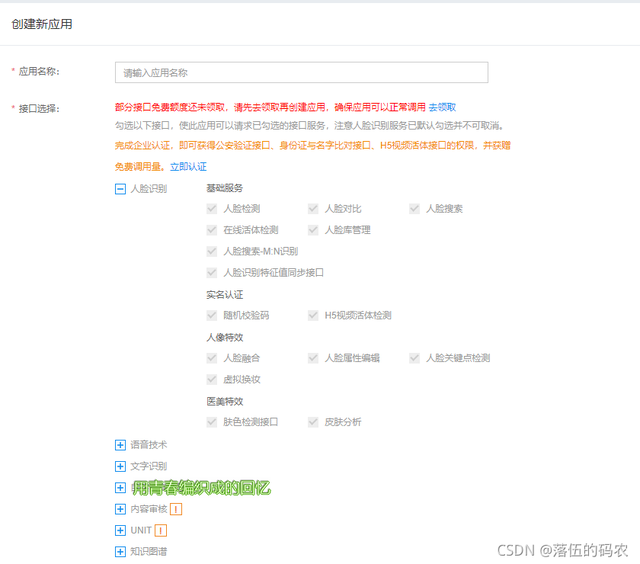
创建好后点击——管理应用
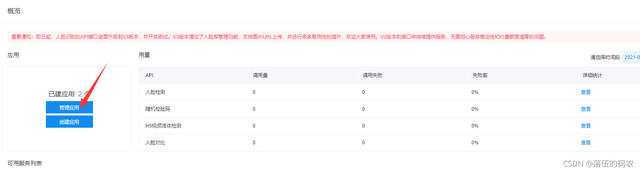

拿到API Key与Secret Key

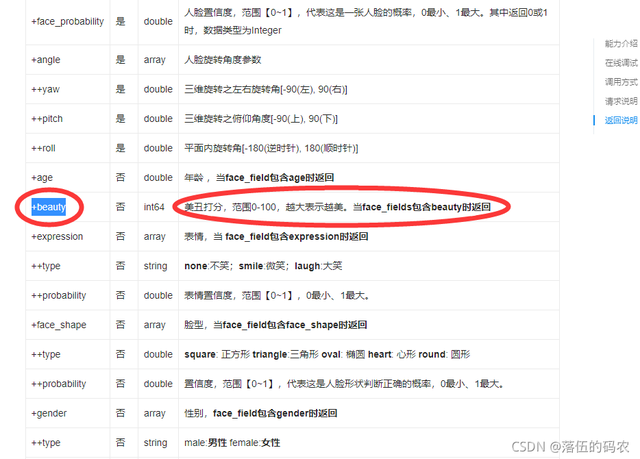
看下技术文档,开始构建咱们的函数,不做过多讲解
提示:模块的安装
pip install baidu-aip
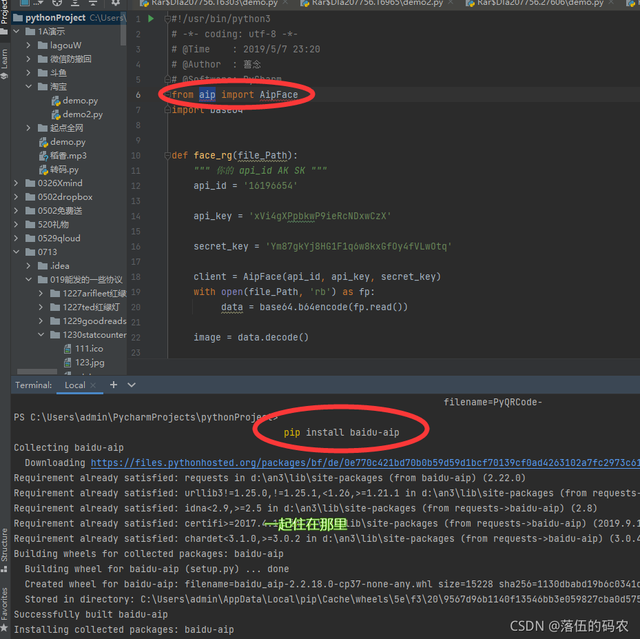
facerg.py
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019/5/7 23:20
# @Author : 善念
# @Software: PyCharm
from aip import AipFace
import base64
def face_rg(file_Path):
""" 你的 api_id AK SK """
api_id = '你的id'
api_key = 'ni de aipkey'
secret_key = '你自己的key'
client = AipFace(api_id, api_key, secret_key)
with open(file_Path, 'rb') as fp:
data = base64.b64encode(fp.read())
image = data.decode()
imageType = "BASE64"
options = {}
options["face_field"] = 'beauty'
""" 调用人脸检测 """
res = client.detect(image, imageType, options)
score = res['result']['face_list'][0]['beauty']
return score
排序源码
from facerg import face_rg
path = r'图片文件夹路径'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
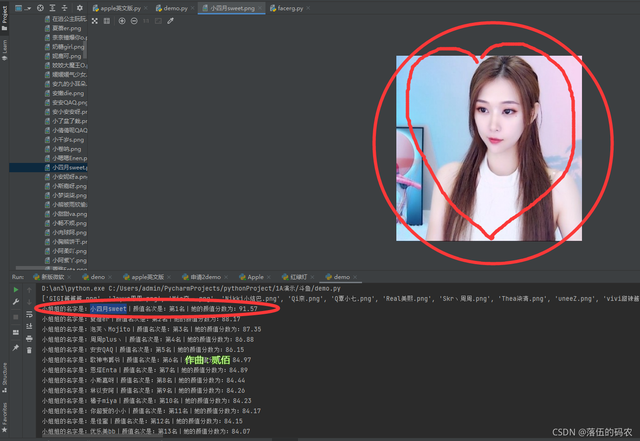
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
结果演示
完整的所有源码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
# headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
#
# if not os.path.exists('./pic'):
# os.mkdir('./pic')
# for i in range(1, 100000):
# try:
# url = f'https://www.douyu.com/gapi/rknc/directory/yzRec/{i}'
# r = requests.get(url, headers=headers)
# names = jsonpath.jsonpath(r.json(), '$..nn')
# pngs = jsonpath.jsonpath(r.json(), '$..rs1')
# for name, png in zip(names, pngs):
# urlretrieve(png, './pic' + '/' + name + '.png')
# print(names)
# print(pngs)
# except:
# exit()
from facerg import face_rg
path = r'C:\Users\admin\PycharmProjects\pythonProject\1A演示\斗鱼\pic'
images = os.listdir(path)
print(images)
yz = []
yz_dict = {}
for image in images:
try:
name = image[0:-4]
score = face_rg(path + '\\' + image)
yz_dict[score] = name
yz.append(score)
except:
pass
yz.sort(reverse=True)
for a, b in enumerate(yz):
print('小姐姐的名字是:{}丨颜值名次是:第{}名丨她的颜值分数为:{}'.format(yz_dict[b], a+1, b))
把facerg.py当成一个自写的模块调用就好了。
我有话说
——当你毫无保留地信任一个人,最终只会有两种结果。不是生命中的那个人,就是生命中的一堂课。
文章的话是现写的,每篇文章我都会说得很细致,所以花费的时间比较久,一般都是两个小时以上。每一个赞与评论收藏都是我每天更新的动力。
原创不易,再次谢谢大家的支持。
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢? 学习Python中有不明白推荐加入交流Q群号:928946953 群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF! 还有大牛解答!

这篇关于哪个主播颜值最高?利用Python采集主播照片,检测颜值后制作排行榜,一目了然!的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-27Python编程基础教程
- 2024-12-27Python编程基础指南
- 2024-12-24Python编程入门指南
- 2024-12-24Python编程基础入门
- 2024-12-24Python编程基础:变量与数据类型
- 2024-12-23使用python部署一个usdt合约,部署自己的usdt稳定币
- 2024-12-20Python编程入门指南
- 2024-12-20Python编程基础与进阶
- 2024-12-19Python基础编程教程
- 2024-12-19python 文件的后缀名是什么 怎么运行一个python文件?-icode9专业技术文章分享



