大数据在车联网行业的实践与应用
2022/5/6 8:12:44

本文主要是介绍大数据在车联网行业的实践与应用,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!

**导读:**联友科技是一家旨在提供在汽车行业全价值链解决方案的科技公司。公司以数字化、智能零部件以及智能网联为三大核心业务领域,涵盖研发/制造/营销等领域的信息化产品、系统运行维护服务、云服务、大数据分析服务、智能网联及数字化运营服务、车载智能部件及汽车设计等业务。本次分享会围绕以下四点展开:
- 车联网平台
- 数据存储
- 数据接入
- 数据应用
–
01 车联网平台
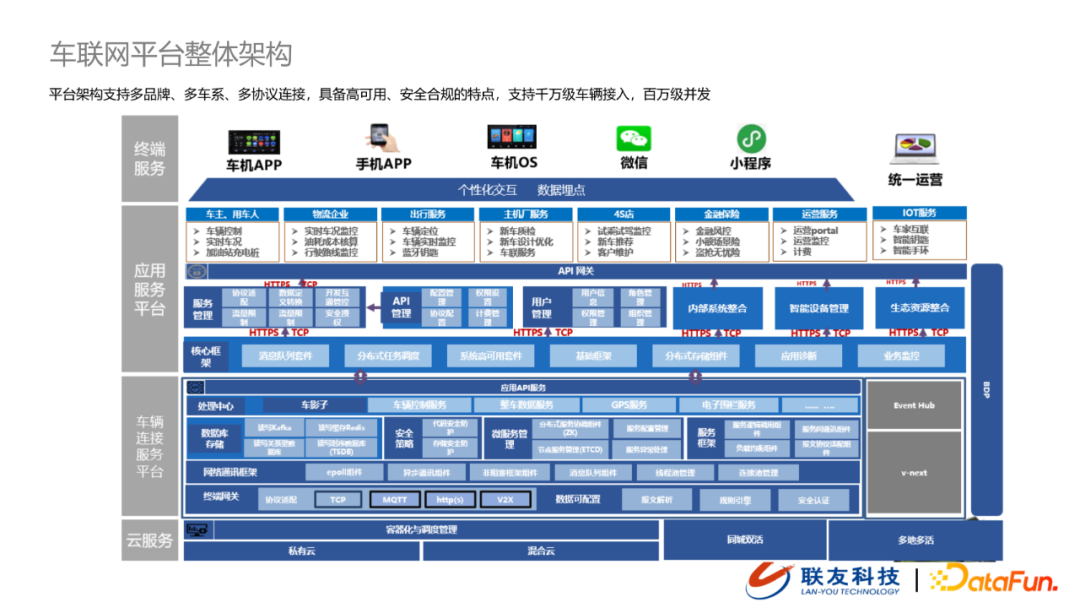
联友科技车联网整体架构由下往上分为四层,分别是云服务、车辆连接服务平台、应用服务平台以及终端服务。目前平台架构支持多品牌、多车系、多协议链接,具备高可用、安全合规,支持千万级车辆接入以及百万级并发。
-
云服务:支持私有云、混合云部署,支持同城双活和异地多活
-
车辆连接管理服务平台:负责车辆连接,包括终端网关(接入协议、数据源可配置)、网络通讯框架、数据存储以及处理中心
-
应用平台:提供统一的能力开放,包括核心框架能力、服务管理、API管理、用户管理等,在对外能力上包括内部系统能力整合、提供与车辆相关数据服务与业务服务
-
终端服务:提供个性化的服务以及数据埋点,支持到多终端、多协议应用设备的接入
在后续的部分我们主要针对车联网数据流在车联网平台架构中的实现展开介绍,承载这部分能力的模块叫做 BDP。
1. 车联网平台整体架构
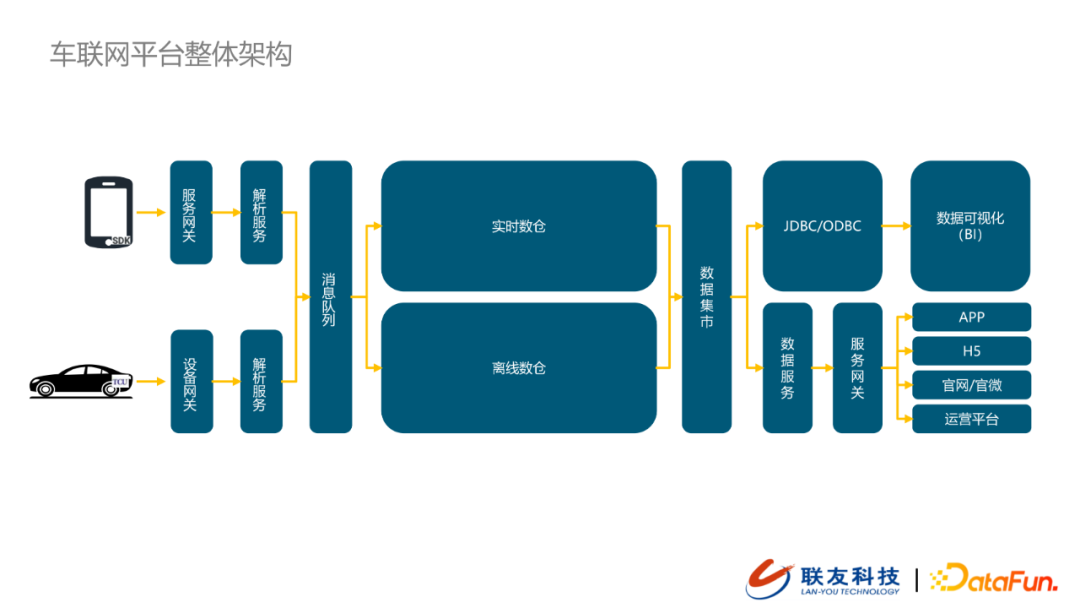
架构由左往右在大概可以分为三个阶段:数据接入、数据存储、数据开放。
由车机和智能设备采集到数据会经过数据接入模块归集到数据消息队列,并最终落入到数据存储层(实时数仓+离线数仓)。数据在数仓中经过清洗之后,会形成规范化的主题数据,这类数据我们会统一放到数据集市层。为了满足到下游的数据获取和传统的数据可视化的需求,我们提供了统一开放的数据消费方式(JDBC/ODBC),支持下游BI需求。同时,对于数据集市中的数据,我们提供数据服务将数据按照数据主题封装,并通过服务网关向外提供数据查询的能力,为APP、H5、官网/官微、运营平台等提供规范的数据。
–
02 数据接入
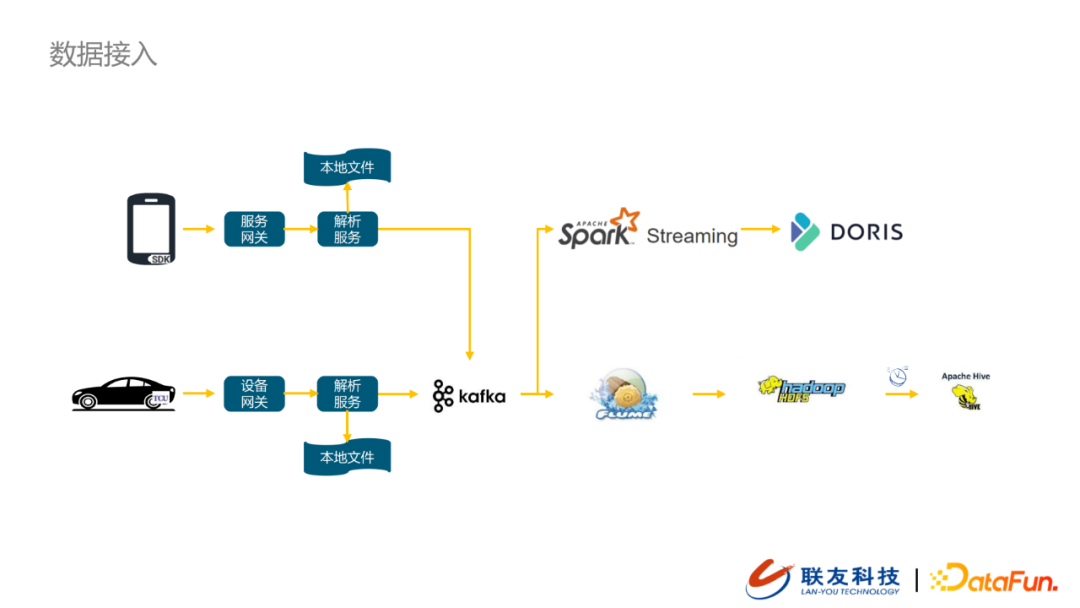
1. 数据源
-
车辆终端:通过TCU上报数据到设备网关,原始上报的数据经过数据解析服务完成数据的解码,然后将语义化的消息推送到数据接入层的消息队列中。
-
设备终端:通过数据采集SDK将智能终端产生的数据上报到服务网关,同样在数据解析服务模块完成数据解析,并注入到数据接入层的消息队列中。
当前数据平台接入的数据源具有多品牌、多渠道、多类型等特点,也正因为数据源的多样性,我们在数据接入上分渠道,在数据清洗时统一单位和精度,在数据存储上分库&分表,以便于向下游提供同一规范的数据。
2. 数据接入架构演进(配置化数据接入)
长期的业务过程证明,不同的“厂商”、不同的“车型”对数据采集项的要求是不一样的。以前的做法是采用统一的数据采集协议,这就引入了一个问题,不同的车型对于数据采集项是不一样的,例如我们采集字段的枚举有3000个,但是某一个车型的数据字段只有2000个,而“统一数据采集协议”要求所有回传的数据都具有同样的结构,这就要求上传车型需要冗余其中1000个不属于自己的字段,并且全部置空,这会导致数据传输过程中存在大量的冗余信息。但是我们希望车辆只回传自己需要回传的字段。那么如何解决这类问题呢?我们后续的演进方向是支持“配置化数据接入”,具体的示意图如下:
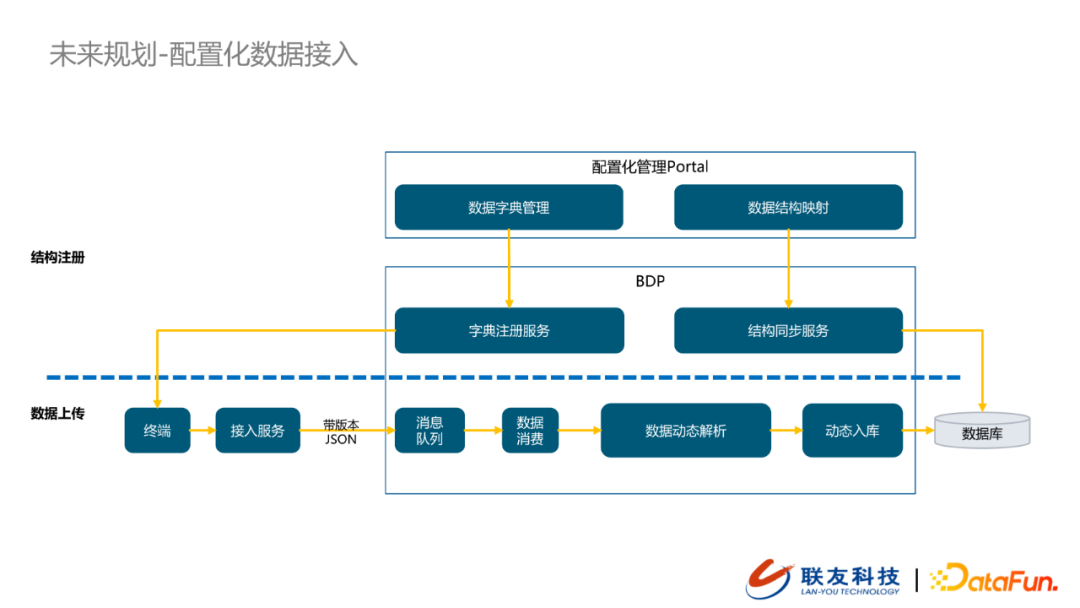
在“配置化数据接入”中会有一个配置化管理portal,在界面上用户可以配置数据字典,配置生效的数据采集协议会在字段注册服务中完成字段注册,并将数据采集协议下发到终端TCU。同时会将已经配置好的数据采集协议映射成后台数据库的数据结构,并走“结构同步服务”将最新的数据采集协议同步到数据库中。当终端接收到新的数据协议之后,就会按照新的数据协议上报带协议版本的数据到数据接入服务,并推送到云端的kafka中。云端数据解析服务会从kafka中消费消息,然后根据“数据字典”中注册的数据协议完成数据的动态解析,再根据数据结构执行数据动态入库(表格schema已经被“结构同步服务”变更)。
–
03 数据存储
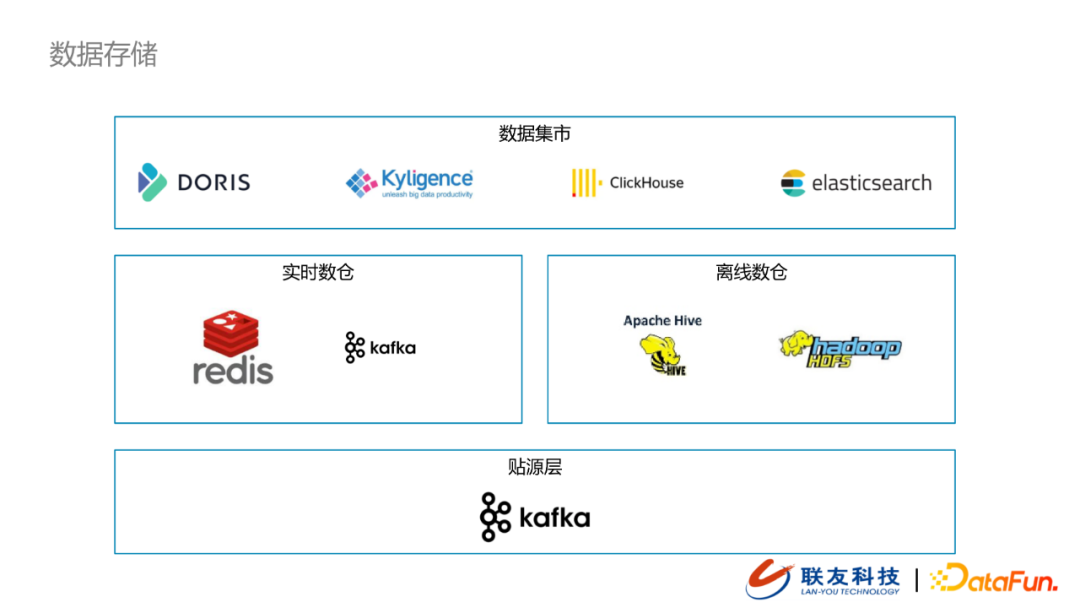
当前所有接入的数据在经过数据接入流程之后,会统一写到贴源层的kafka集群。当前我们的数仓层分为两块:实时数仓、离线数仓。
-
实时数仓我们采用的是kafka+redis的组合
-
离线数仓我们采用的还是传统的Hive+HDFS的方案
经过数仓清洗之后的数据会分主题推送到数据集市中。我们面向不同的应用场景选用了不同的解决方案:
-
Doris:基于埋点数据分析用户的运营活动,例如流程分析,漏斗分析等
-
Kyligence:支持数据的多维分析(MOLAP),面向固定报表分析
-
Clickhouse:支持数据自定义分析,体现数据分析的灵活性
-
Elasticsearch:分数据视图,支持数据检索
1. 实时数仓
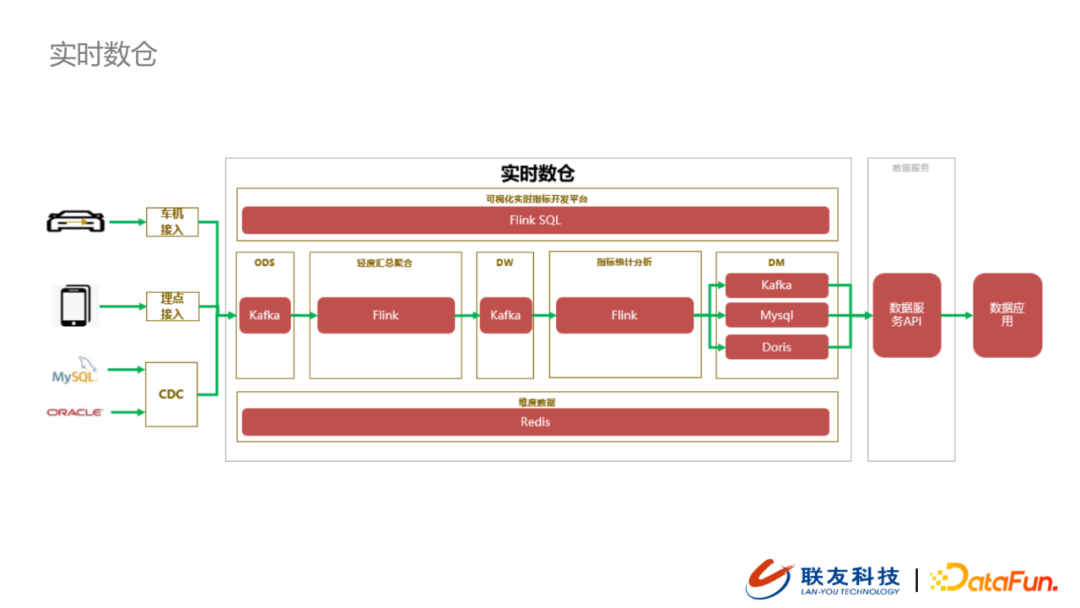
除了之前提到的车机数据接入以及埋点数据接入以外,我们数仓的数据源还包括车企内部系统的数据,针对这类数据,我们采用了CDC的方式从数据源(MySQL或者Oracle)中捕获数据,并写入到贴源层的kafka中。Kafka中的数据会被下游的Flink Job消费,并做数据的轻度汇总,然后写入到DW(kafka)中。下游支持实时指标计算的 Flink job 会从数据DW中拉取数据完成指标计算,并按照下游需求,将计算结果推送DM层。在实时数仓的最上层是基于Flink SQL构建的可视化实时指标开发平台,用户可以通过写SQL的方式,完成实时指标开发。所有DM层的指标数据会通过数据服务API的方式供下游的数据应用查询。
2. 离线数仓
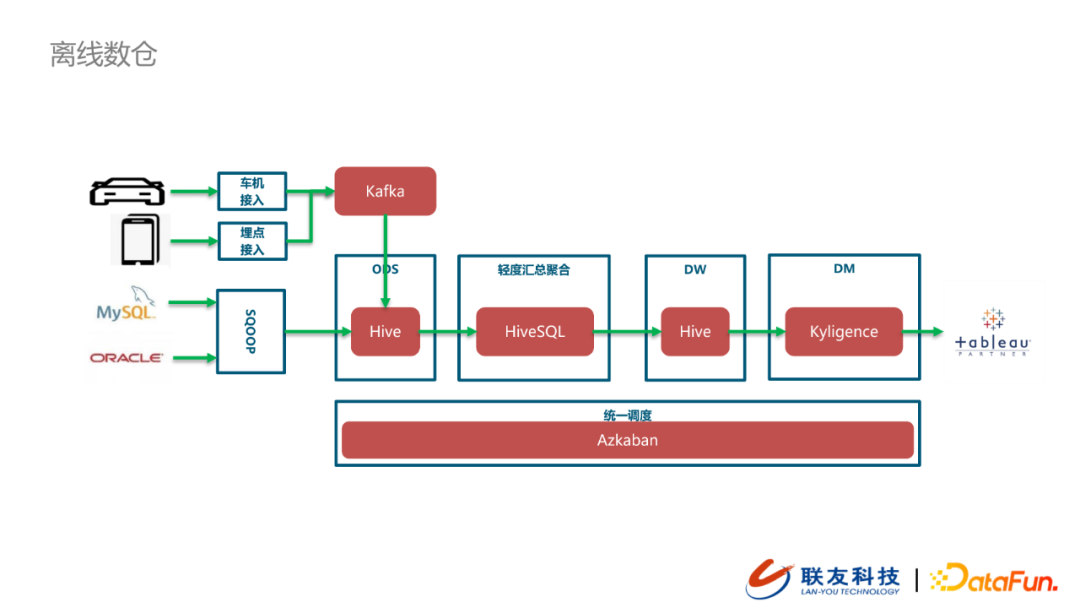
可以看到,离线数仓与实时数仓的数据源是相同的,都包括车机数据埋点、设备接入埋点以及外部系统数据。埋点数据统一接入kafka,然后写入ODS(Hive),而在外部系统数据同步上存在差异。离线数仓在同步外部系统数据时采用的是sqoop。数据统一入仓之后会做轻度的数据汇总,并写入到DW层(Hive)。下游的DM层会对数据按照主题做分块(cube)与分片(slice),应对稳定的BI需求(Kyligence)。在数据可视化层,采用的是Tableau,支持到MOLAP场景的需求。内部的各种数据ETL任务会统一在底层的调度层(Azkaban)来做编排与调度。
在数据集市层,我们主要面临两类需求:固定报表分析与实时多维报表分析。
- 固定报表分析 – Kyligence
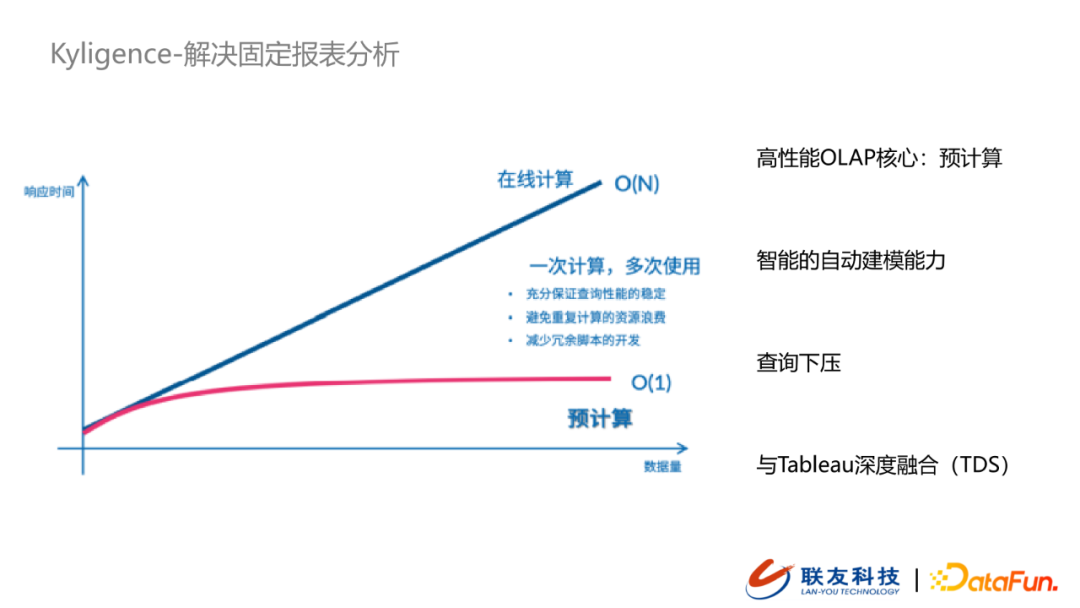
应对MOLAP场景时,Kyligence使用的是典型的空间换时间的方式支持到高性能的OLAP计算(预计算),除此之外,还能够做到自动建模与查询下压。其中我们选择Kyligence的一个很大的原因是由于其提供了与Tableau深度融合的能力,目前我们的客户在数据可视化方案上采用的是Tableau,Kyligence提供的TDS很好地支持到我们将数据集市中的数据对接到Tableau,而不需要再走定时数据同步,提升了数据性能。
- 实时报表分析 – Doris
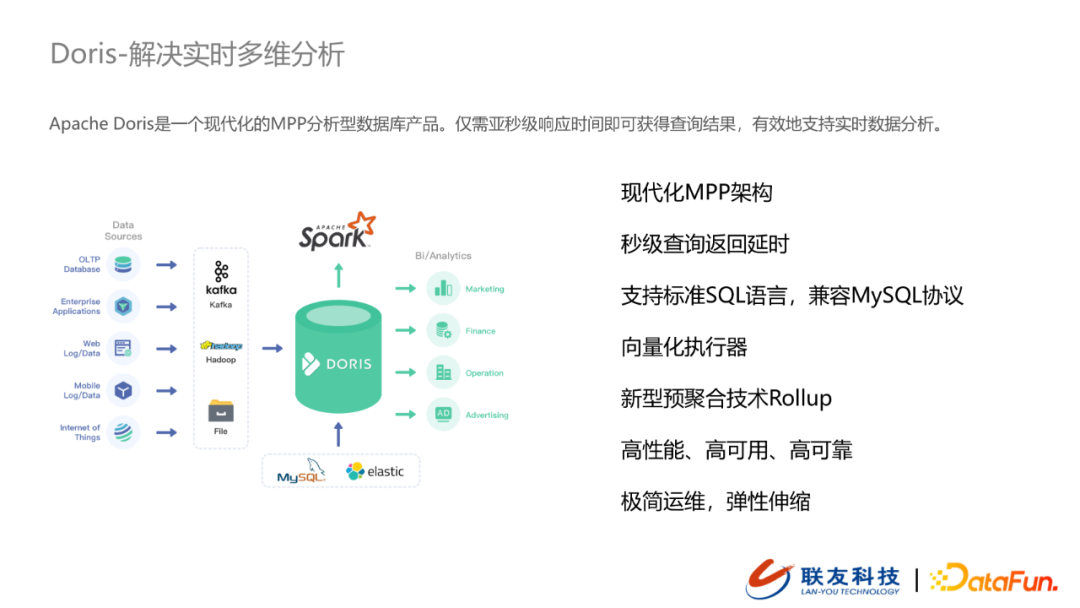
当前我们的埋点数据主要是用户行为数据,这类数据会统一在用户运营平台完成用户行为的分析(热点事件,漏斗分析),这个过程会涉及到轻量级的join分析,Doris就非常适合这类场景。
–
04 数据应用
1. 用户运营 – 离线
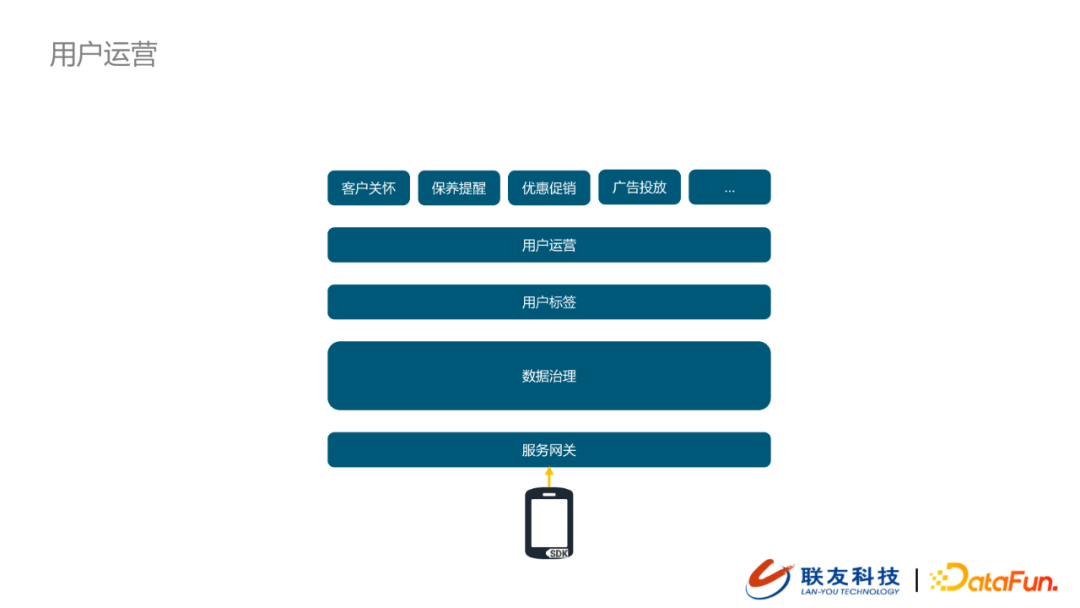
我们APP、车机、官网/官微的数据会通过服务网关的方式采集到大数据平台,经过数据轻度汇聚之后,将用户特征与我们标签体系中的标签特征做匹配,并打上相应的标签。用户运营人员会做大量的用户群体分类筛选,这些信息会支持我们对特定的用户做客户关怀、保养提醒、优惠促销、广告投放等服务。
2. 智能推荐 – 实时
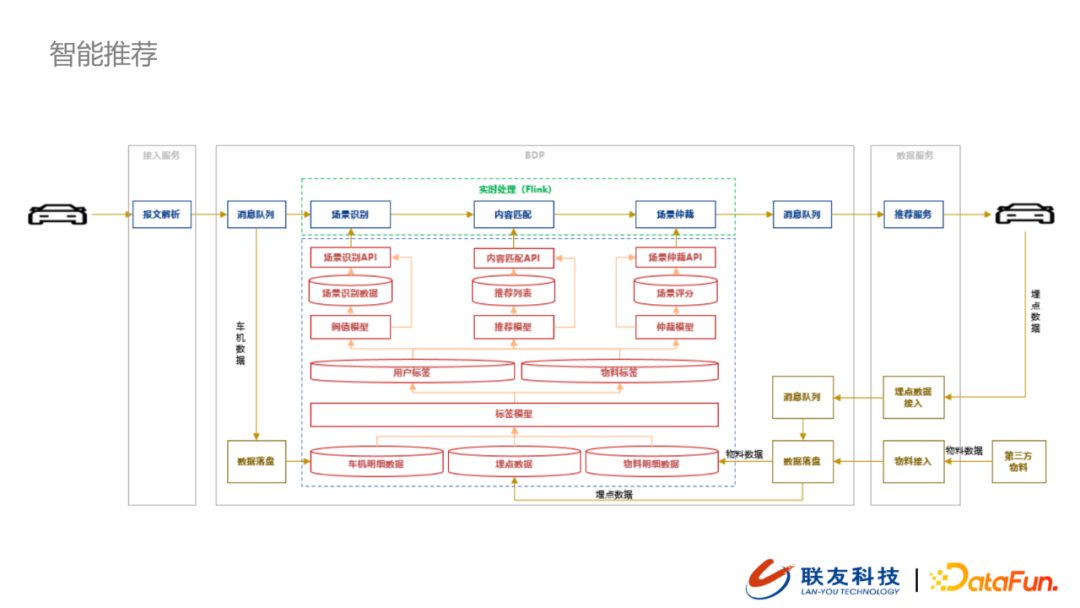
根据上图所示,智能推荐核心业务过程包括场景识别、内容匹配、场景仲裁。我们在支持智能推荐应用上主要有如下几个数据流程:
-
车机数据上报:车机上报的状态数据经过报文解析为格式化的数据之后,会推送到BDP的数据接入层。这类数据在消息队列之后会做数据的分流:一条链路是数据落盘归档,作为最稳定的原始数据,支撑上游的分析与业务应用;另外一条链路会支持到实时业务场景应用。
-
埋点数据回传:用户终端在接收到这类推送之后会有自己的反馈,这类数据会以埋点数据的形式再回传到大数据平台
-
第三方数据:我们会与第三方厂商做一些合作,拉取物料数据到我们的大数据平台,丰富我们的数据基础。
基于以上三类数据源,在打上初步的标签(物料标签或者用户标签)之后会支持我们构建如下三个核心能力:
- 场景库
将海量的用户基础数据与标签数据经过阈值模型对用户以及用户行为进行分类后的结果丰富场景数据库,下游的场景识别API可以基于场景库与阈值模型做出场景识别,例如我们可以基于用户真实加油习惯做加油时机的推荐。
- 内容库
内容库与场景库建设类似,进入系统的用户标签数据与物料标签数据输入到推荐模型之后,会生成推荐列表,再通过内容匹配API开放给实时业务流程的内容匹配模块。
- 场景仲裁
在数据流经仲裁模块之后,场景仲裁模型会根据用户配置的场景优先级进行场景评分。评分之后的场景会也通过场景仲裁API开放给实时业务模块。
由以上业务过程与数据流程可知,我们的数据流程是在不断运转迭代的,智能推荐业务在上线之后,会产生源源不断的用户反馈数据,这些反馈数据会回流到我们的数据系统中,帮助我们提升推荐的准确度。例如基于提取到的车辆位置信息,我们能了解到车辆轨迹信息在空间上的分布,这类信息可以支撑我们做一些加油站与充电桩的选址与建设。再例如我们可以基于收集到的用户驾驶行为数据(急加速,急转弯等)对用户进行分类,并基于类别信息作合适的维保推荐。在智能推荐中还有一个比较成功的场景是我们基于用户的驾驶行为数据构建了用户画像与驾驶行为知识图谱,基于知识图谱搭建了一个智能客服,当前用户90%的问题够可以通过我们的智能客服来解决,很大程度上节约了我们的人力成本。
–
05 数据应用
问:刚才老师有提到我们有采集车辆的位置数据,那我们的数据合规与数据安全问题是怎么解决的呢?
答:数据安全与数据合规是我们在做数据采集时必须要考虑的。首先,用户在购买搭载我们车联网方案的车之后,在开始使用我们提供的服务之前,我们会让用户浏览我们的数据采集协议,在征得用户同意之后,我们才会做协议范围内的用户信息采集。其次,我们采集到的用户隐私数据(例如位置信息)只会在我们的数据中心存储七天,七天之前的数据我们会做清理与销毁。最后,我们基于用户位置信息加工产生的隐私数据(例如公司地点、居住地点等)在满足数据合规要求的前提下进行持久化,这类数据我们目前持有的时间周期是30天,超出数据持有周期的数据我们同样会做清理与销毁。
这篇关于大数据在车联网行业的实践与应用的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-22揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)
- 2024-12-20DevOps与平台工程的区别和联系
- 2024-12-20从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南
- 2024-12-20手把手教你轻松部署网站
- 2024-12-20服务器购买课程:新手入门全攻略
- 2024-12-20动态路由表学习:新手必读指南
- 2024-12-20服务器购买学习:新手指南与实操教程
- 2024-12-20动态路由表教程:新手入门指南
- 2024-12-20服务器购买教程:新手必读指南
- 2024-12-20动态路由表实战入门教程



