【九月打卡】第3天 数据分析体系课学习笔记 part-3 初学Py爬虫
2022/9/8 3:23:02

本文主要是介绍【九月打卡】第3天 数据分析体系课学习笔记 part-3 初学Py爬虫,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
课程名称:数据分析体系课
课程章节:Python实现网络爬虫
课程讲师: DeltaF
课程内容:
什么是爬虫
Requests库入门
认识HTML网页结构
BeautifulSoup库入门
抓取页面信息
获取目标信息
连续获取多个页面信息
整合爬虫功能函数
数据存储与代码优
利用API获取信息
通过API接口获取数据
主要知识点: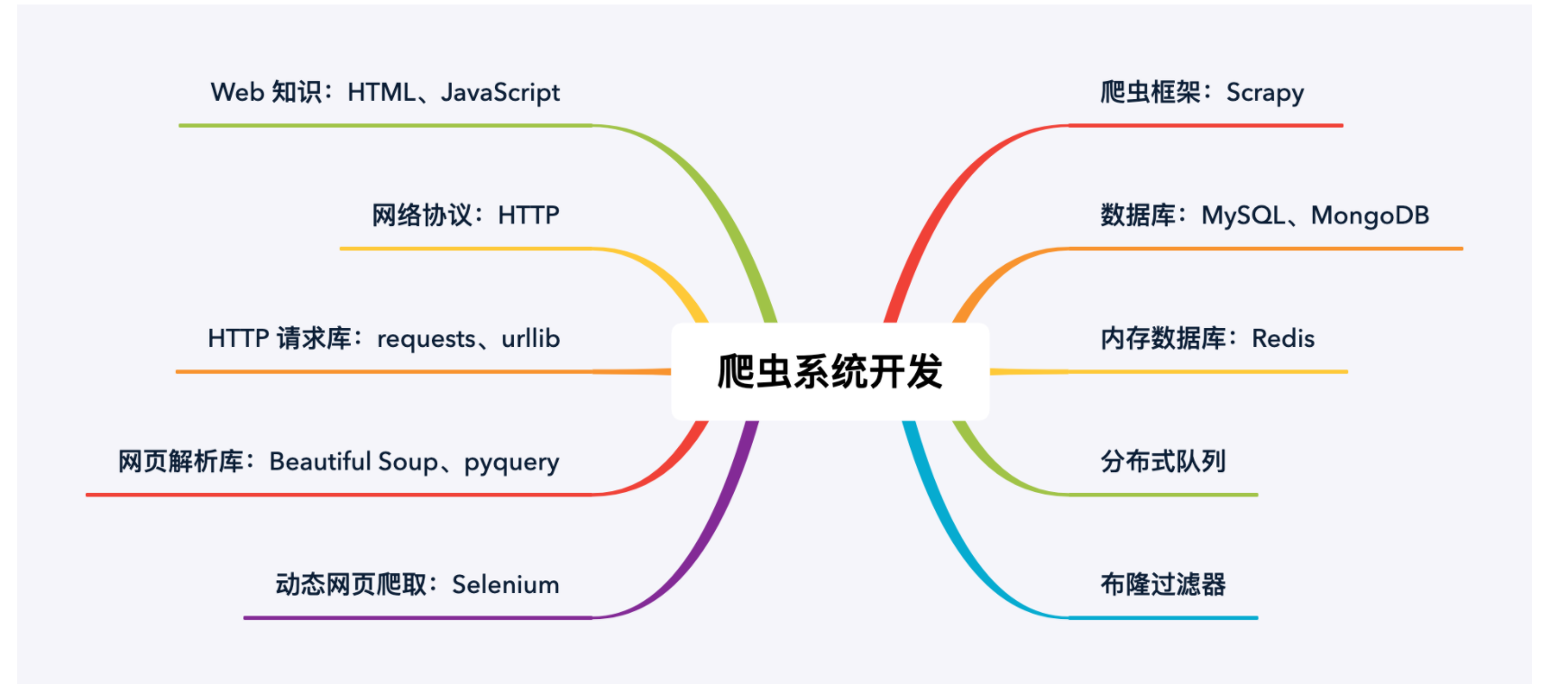
1.了解爬虫的基本原理及过程
大部分爬虫都是按“发送请求——获得页面——解析页面——抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面,通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。
在这部分你可以简单了解 HTTP 协议及网页基础知识,比如 POST\GET、HTML、CSS、JS,简单了解即可,不需要系统学习。
2.学习 Python 包并实现基本的爬虫过程
Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,建议你从requests+Xpath 开始,requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。
如果你用过 BeautifulSoup,会发现 Xpath 要省事不少,一层一层检查元素代码的工作,全都省略了。掌握之后,你会发现爬虫的基本套路都差不多,一般的静态网站根本不在话下,小猪、豆瓣、糗事百科、腾讯新闻等基本上都可以上手了。
来看一个爬取豆瓣短评的例子:


选中第一条短评,右键-“检查”,即可查看源代码

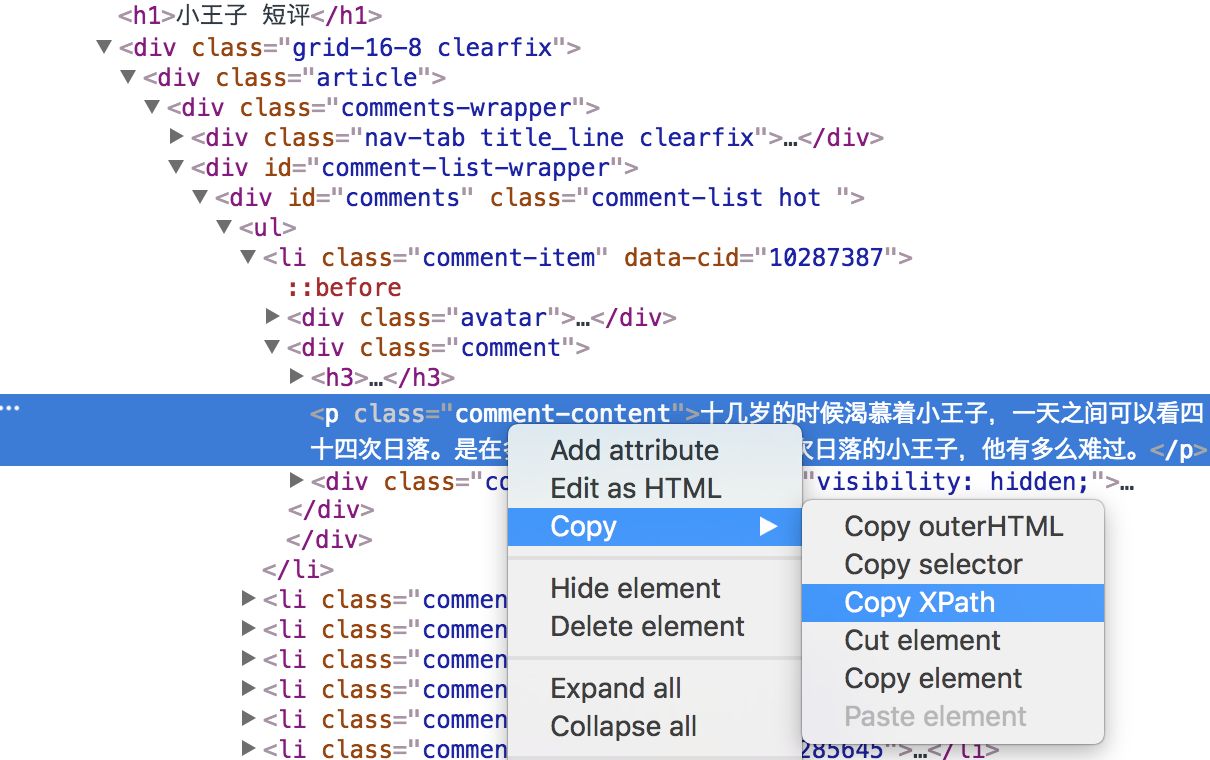
把短评信息的XPath信息复制下来
我们通过定位,得到了第一条短评的XPath信息:
//*[@id="comments"]/ul/li[1]/div[2]/p
但是通常我们会想爬取很多条短评,那么我们会想获取很多这样的XPath信息:
//*[@id="comments"]/ul/li[1]/div[2]/p //*[@id="comments"]/ul/li[2]/div[2]/p //*[@id="comments"]/ul/li[3]/div[2]/p ………………………………
观察1、2、2条短评的XPath信息,你会发现规律,只有
后面的序号不一样,恰好与短评的序号相对应。那如果我们想爬取这个页面所有的短评信息,那么不要这个序号就好了呀。通过XPath信息,我们就可以用简单的代码将其爬取下来了:
import requests
from lxml import etree
#我们邀抓取的页面链接
url='https://book.douban.com/subject/1084336/comments/'
#用requests库的get方法下载网页
r=requests.get(url).text
#解析网页并且定位短评
s=etree.HTML(r)
file=s.xpath('//*[@id="comments"]/ul/li/div[2]/p/text()')
#打印抓取的信息
print(file)


爬取的该页面所有的短评信息
当然如果你需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium来实现自动化,这样,知乎、时光网、猫途鹰这些动态的网站也基本没问题了。
这个过程中你还需要了解一些Python的基础知识:
文件读写操作:用来读取参数、保存爬下来的内容
list(列表)、dict(字典):用来序列化爬取的数据
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for ……while):用来循环爬虫步骤
3.了解非结构化数据的存储
爬回来的数据可以直接用文档形式存在本地,也可以存入数据库中。
开始数据量不大的时候,你可以直接通过 Python 的语法或 pandas 的方法将数据存为text、csv这样的文件。还是延续上面的例子:
用Python的基础语言实现存储:
with open('pinglun.text','w',encoding='utf-8') as f:
for i in file:
print(i)
f.write(i)
用pandas的语言来存储:
#import pandas as pd
#df = pd.DataFrame(file)
#df.to_excel('pinglun.xlsx')
这两段代码都可将爬下来的短评信息存储起来,把代码贴在爬取代码后面即可。


存储的该页的短评数据
当然你可能发现爬回来的数据并不是干净的,可能会有缺失、错误等等,你还需要对数据进行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。以下知识点掌握就好:
- 缺失值处理:对缺失数据行进行删除或填充
- 重复值处理:重复值的判断与删除
- 空格和异常值处理:清楚不必要的空格和极端、异常数据
- 分组:数据划分、分别执行函数、数据重组
完成后对数据进行分析
课程截图
这篇关于【九月打卡】第3天 数据分析体系课学习笔记 part-3 初学Py爬虫的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-11-26Mybatis官方生成器资料详解与应用教程
- 2024-11-26Mybatis一级缓存资料详解与实战教程
- 2024-11-26Mybatis一级缓存资料详解:新手快速入门
- 2024-11-26SpringBoot3+JDK17搭建后端资料详尽教程
- 2024-11-26Springboot单体架构搭建资料:新手入门教程
- 2024-11-26Springboot单体架构搭建资料详解与实战教程
- 2024-11-26Springboot框架资料:新手入门教程
- 2024-11-26Springboot企业级开发资料入门教程
- 2024-11-26SpringBoot企业级开发资料详解与实战教程
- 2024-11-26Springboot微服务资料:新手入门全攻略



