基于Netty的自研流系统缓存实现挑战: 内存碎片与OOM困境
2024/7/15 21:02:53

本文主要是介绍基于Netty的自研流系统缓存实现挑战: 内存碎片与OOM困境,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
01
前言
Kafka 作为流处理平台,在实时流计算和在线业务场景,追尾读追求端到端低延迟。在离线批处理和削峰填谷场景,数据冷读追求高吞吐。两个场景都需要很好的数据缓存设计来支撑,Apache Kafka 的数据存储在本地文件,通过 mmap 将文件映射到内存中访问,天然就可以依托操作系统来完成文件的缓冲持久化、缓存加载和缓存驱逐。AutoMQ 采用存算分离的架构,将存储分离至对象存储,本地没有数据文件,因此无法像 Apache Kafka 一样直接使用数据文件 mmap 来进行数据缓存。这时候通常缓存对象存储的数据有两种做法:
-
第一种是将对象存储文件下载到本地文件,然后再通过 mmap 读取本地文件。这种做法在实现上比较简单,但是需要一块额外的磁盘来缓存数据,然后根据缓存所需的大小和速率,还需要购买磁盘空间和 IOPS,该做法不够经济;
-
第二种是根据流处理的数据消费特征,直接基于内存来进行数据缓存。这种做法实现起来会复杂一些,相当于需要实现一个类似操作系统的内存管理。但是就像万事万物都有两面性一样,自己实现内存缓存管理,就可以根据业务场景取得最佳的缓存效率和经济性。
为了降低运维的复杂性和持有成本,提高缓存的效率,AutoMQ 最终选择的是第二种做法:“直接基于内存来进行数据缓存”。
02
AutoMQ 缓存设计
直接基于内存来进行数据缓存,AutoMQ 针对追尾读和冷读两个场景,根据两者的数据访问特点,设计了两套缓存机制:LogCache 和 BlockCache。
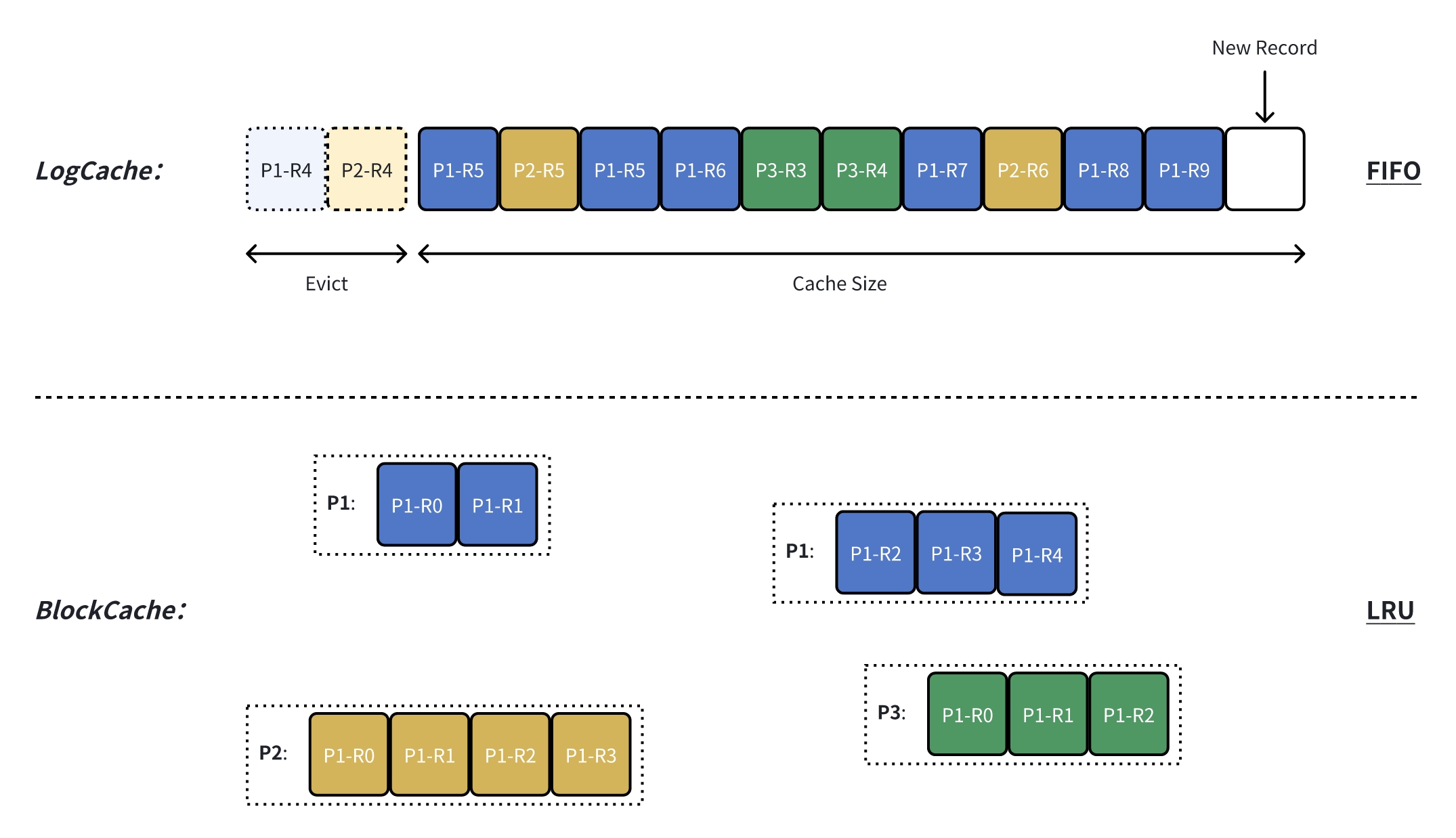
LogCache 针对于追尾读场景设计,数据上传到对象存储的同时,也会以单个 RecordBatch 的形式在 LogCache 中缓存一份,这样热数据就可以从直接缓存中获取,提供极低的端到端延迟。相比操作系统通用的缓存设计,LogCache 还具备以下两个特质:
-
FIFO:针对追尾读持续访问新数据的特点,LogCache 采用先入先出的缓存驱逐策略,优先保证新数据缓存的可用性;
-
低延迟:LogCache 有独占的缓存空间,只负责热数据的缓存,避免了冷数据读取影响热数据消费的问题。
BlockCache 针对冷读场景设计,当无法在 LogCache 中访问到需要的数据时,则从 BlockCache 中读取。BlockCache 相比 LogCache 具备以下两个不同点:
-
LRU:BlockCache 使用 Least Recently Used 策略来进行缓存驱逐,在多倍 Fanout 的冷读场景可以获得更佳的缓存利用率;
-
高吞吐:冷读关注的是吞吐量,因此 BlockCache 会大块(~4MB)的从对象存储读取 & 缓存数据,并且通过预读策略来提前加载后续可能读取的数据;
Java 程序中在内存中缓存数据可以选择堆内内存或堆外内存。为了减轻 JVM GC 的负担,AutoMQ 使用堆外内存 Direct Memory 来缓存数据,并且为了提高 Direct Memory 的申请效率,采用业界成熟的 Netty PooledByteBufAllocator 从池化内存中进行内存的申请和释放。
03
“惨案”发生
期望是使用 Netty 的 PooledByteBufAllocator 后,AutoMQ 既可以通过池化来获得高效的内存分配速度,又有久经打磨的内存分配策略来最小化内存分配的 Overhead,就可以高枕无忧无忧了,然而在 AutoMQ 1.0.0 RC 压测过程中被现实给了当头一棒。AutoMQ 生产机型为 2C16G,设置堆外内存使用上限 6GiB -XX:MaxDirectMemorySize=6G,内存分配为 2GiB LogCache + 1GiB BlockCache + 1GiB 其他小项 ~= 4GiB < 6GiB。理论计算下,堆外内存还绰绰有余,然而在实际 AutoMQ 1.0.0 RC 版在各种不同负载下长时间运行后发现,分配内存有 OOM OutOfMemoryError 异常抛出。
本着优先怀疑自己而不是怀疑成熟的类库和操作系统的原则。观测到异常后,首先怀疑的是代码中哪里有遗漏调用 ByteBuf#release。于是调整 Netty 的泄漏检测等级 -Dio.netty.leakDetection.level=PARANOID,检测每个的 ByteBuf 是否有存在被 GC 但是还没有被释放的问题。跑了一段时间未发现有 Leak 日志,于是乎排除漏释放的可能。
接着怀疑点转移到是否代码中有哪块内存分配量超出了预期值。Netty 的 ByteBufAllocatorMetric只提供全局的内存占用统计,传统的内存分配火焰图也只能提供特定时间的内存申请量,而我们需要的是某个时刻各种类型的内存使用量。因此 AutoMQ 将 ByteBuf 的申请收口到自己实现的 ByteBufAlloc工厂类中,通过WrappedByteBuf 跟踪各种类型内存的申请和释放,以此来记录当前时刻各个类型的内存使用量。并且将 Netty 的实际内存使用量也记录下来,这样就知道 AutoMQ 总体内存和分类内存的使用量。
Buffer usage:
ByteBufAllocMetric{allocatorMetric=PooledByteBufAllocatorMetric(usedDirectMemory: 2294284288; ...), // Physical Memory Size Allocated by Netty
allocatedMemory=1870424720, // Total Memory Size Requested By AutoMQ
1/write_record=1841299456, 11/block_cache=0, ..., // Detail Memory Size Requested By AutoMQ
pooled=true, direct=true} (com.automq.stream.s3.ByteBufAlloc)
加上分类内存统计后,发现各种类型的内存使用量都在预期范围内。不过异常的是,AutoMQ 申请的内存量和 Netty 实际申请的内存量有较大的差距,并且随着运行两者之间的差值越来越大,甚至有时候 Netty 实际升级的内存是 AutoMQ 申请的内存量的两倍,这个差值为内存分配的内存碎片。
最终 OOM 的诱发原因定位为 Netty PooledByteBufAllocator 的内存碎片。初步定位了问题的原因,那么问题转换为 Netty 为什么会有内存碎片和 AutoMQ 如何规避内存碎片问题。
04
Netty 内存碎片
首先我们来探索一下 Netty 内存碎片的原因。Netty 的内存碎片分为内部碎片和外部碎片:
-
内部碎片:由于 size 规约化对齐引起的碎片,例如期望分配 1byte,但是底层实际占用了 16byte,那么内部碎片就浪费了 15byte;
-
外部碎片:简单的来说,所有除了内部碎片以外引起的碎片都算外部碎片,通常是由于分配算法导致的内存布局碎片导致的;
内部碎片和外部碎片,在不同的 Netty 版本有不同的表现,下面将以 Netty 4.1.52 版本为分割线简要介绍一下 Buddy 分配算法和 PageRun/PoolSubPage 分配算法的工作机制和内存碎片成因。
4.1 Buddy 分配算法 Netty < 4.1.52
Netty < 4.1.52 采用 Buddy 分配算法,算法源自 jemalloc3。Netty 为了提升内存申请的效率,会一次性从操作系统申请一段连续内存(PoolChunk),在上层申请 ByteBuf 时,按需将这一段内存逻辑拆分返回给上层。默认 PoolChunk 的大小为 16MB,PoolChunk 逻辑上被划分为 2048 个 8KB 大小的 Page,通过一个完全二叉树来表示内存的使用情况。
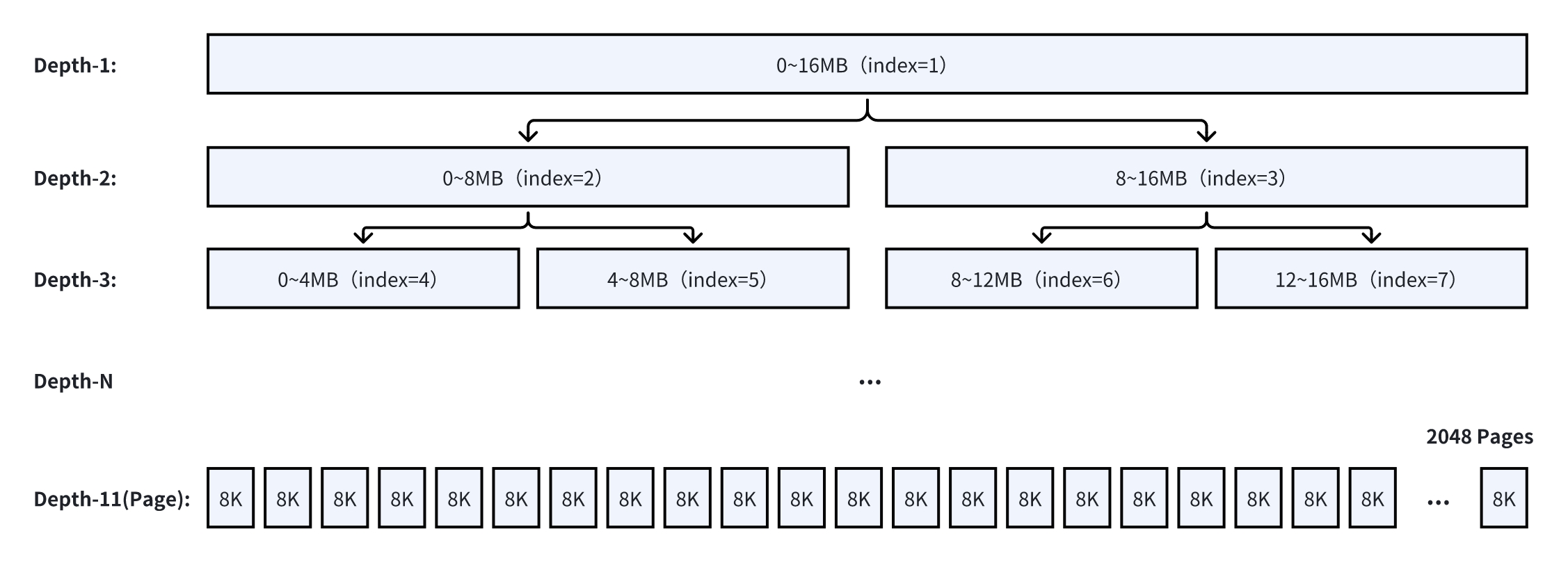
完全二叉树的每个节点用一个 byte 来表示节点的状态(memoryMap):
-
初始值为层数,状态值 == 层数代表该节点完全空闲;
-
当层数 < 状态值 < 12 时,代表该节点被使用了一部分,但仍旧有剩余空间;
-
当状态值 == 12 时,代表该节点已经被完全分配;
内存分配分为 Tiny [0, 512byte] 、 Small (512byte, 8KB) 、 Normal [8KB, 16M] 和 Huge (16M, Max) 四种类型,其中 Tiny 和 Small 由 PoolSubpage 负责,Normal 由 PoolChunk 负责,Huge 直接分配。
先来看看小内存块的分配效率,Tiny [0, 512byte] 和 Small (512byte, 8KB) 将一个 Page 通过 PoolSubpage 切分成等长的逻辑块,由一个 bitmap 来标记块的使用情况:
-
Tiny 内存分配的基础单位为 16 byte,意味着如果请求大小为 50 byte,实际分配的是 64 byte,内部碎片率为 28%;
-
Small 内存分配的基础单位是 1KB,意味着请求大小为 1.5KB,实际分配的是 2KB,内部碎片率为 25%;
再来看看中等的内存块 Normal [8KB, 16M],假设从一个完全空闲的 PoolChunk 申请 2MB + 1KB = 2049KB 内存:
-
2049KB 以 2 为底向上规格化后变为 4MB,于是查找目标为 Depth-3 的空闲节点;
-
检查 index=1 节点,发现节点有空闲,则检查左子树;
-
检查 index=2 节点,发现节点有空闲,则继续检查左子树;
-
检查 index=4 节点,发现节点未被分配,则将 index=4 的状态标记为 12,并且将父节点的状态更新为两个子节点中最小的那个,也就是将 index=2 的状态变为 3,同理依次更新父节点状态;
-
分配完成;
从分配结果可以看出,申请 2049KB 内存,实际标记占用 4MB 内存,意味着内部碎片率为 49.9%。
假设再申请一个 9MB 的内存,虽然刚才的 PoolChunk 仍有 12MB 的剩余空间,但是由于 Buddy 内存分配算法的原理,index=1 已经被占用了部分,此时只能新开一个 PoolChunk 来分配 9MB 的内存。分配后的外部碎片率为 1 - (4MB + 9MB) / 32MB = 59.3%。最终所需内存 / 底层实际占用内存 = 有效内存利用率 = 仅为 34.3%。
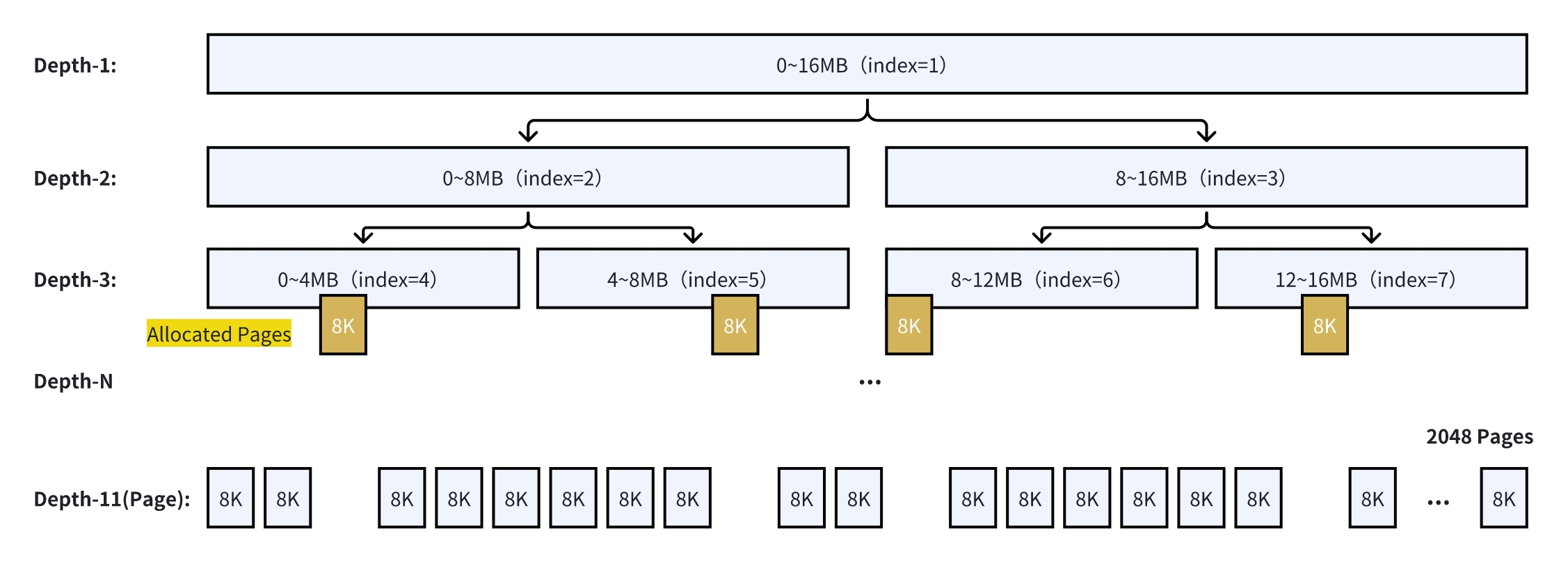
更进一步,在各种不同大小的内存块持续的分配释放场景,即使 PoolChunk 实际分配出去的空间不大,也有可能被零散的内存块逻辑分割,进一步增加更多的外部内存碎片。以下图为例,虽然上层应用最终只保留了 4 * 8KB,但是已经无法再从这个 PoolChunk 申请 4MB 的内存了。
4.2 PageRun/PoolSubpage 分配算法 Netty >= 4.1.52
Netty >= 4.1.52 参考 jemalloc4 将内存分配升级到 PageRun/PoolSubPage 分配策略。相比原来的 Buddy 分配算法无论在小内存的分配还是在大内存的分配都有低的内部 & 外部内存碎片率。PageRun/PoolSubpage 分配算法相比原来 Buddy 分配算法:
-
Chunk 默认大小从 16MB 变为 4MB;
-
保留了 Chunk 和 Page,增加了 Run 的概念,一串连续的 Pages 组成一个 Run,通过 Run 来分配 Normal (28KB, 4MB) 中等内存;
-
将 Tiny 和 Small 级别的内存块替换成可跨多个 Page & [16byte … 28KB] 共 38 级基础分配大小的 PoolSubpage;

首先仍旧是先看看小内存块的分配效率,以申请 1025 byte 为例:
- 首先 1025 会根据 PoolSubpage 级别规约到 1280 这个基础分配大小;
sizeIdx2sizeTab=[16, 32, 48, 64, 80, 96, 112, 128, 160, 192, 224, 256, 320, 384, 448, 512, 640, 768, 896, 1024, 1280, 1536, 1792, 2048, 2560, 3072, 3584, 4096, 5120, 6144, 7168, 8192, 10240, 12288, 14336, 16384, 20480, 24576, 28672, ...]
-
然后 PoolChunk 会对 1280 byte 和 Page Size 8K 取最小公倍数 40KB 来决定该 PoolSubPage 包含 5 个 Pages;
-
从 PoolChunk 中分配 5 个连续的 Pages,并通过 bitmapIdx 记录已分配出去的 element;4. 至此分配完成,内部碎片率为 1 - 1025 / 1280 = 19.9%得益于 PoolSubpage 相比原来分级更加精细,从原来的 2 级变成 38 级,小内存块的分配效率大大提高。
然后再来看看中等的内存块 Normal (28KB, 4M] 的内存分配效率。假设从一个完全空闲的 PoolChunk 申请 2MB + 1KB = 2049KB 内存: -
2049KB 按照 8KB 向上规整后,发现需要 257 个 Pages;
-
PoolChunk 中找到满足大小的 Run Run{offset=0, size=512};
-
PoolChunk 将 Run 拆分成 Run{offset=0, size=257} 和 Run{offset=257, size=255},第一个 Run 返回给请求方,第二个 Run 加入到空闲 Run 列表(runsAvail)中;
-
至此分配完成,内部碎片率为 1 - 2049KB / (257 * 8K) = 0.3%;
通过 PageRun 机制,Netty 可以控制大于 28KB 的内存块分配的内存浪费不超过 8KB,内部碎片率小于 22.2%。
假设再申请一个 1MB 的内存,这时候 PoolChunk 仍旧运行相同的逻辑将 Run{offset=257, size=255} 拆分成 Run{offset=257, size=128} 和 Run{offset=385, size=127},前者返回给上层,后者加入到空闲 Run 列表。此时外部碎片率为 25%。如果按照老的 Buddy 算法,在 PoolChunk 的大小为 4MB 的场景下,就需要新开一个 PoolChunk 了,外部碎片率为 62.5%。
虽然 PageRun/PoolSubpage 分配算法在大小内存上相比原有的 Buddy 分配算法有更低的内部内存碎片率和外部内存碎片率,但是毕竟不像 JVM 内通过 GC 来 Compact 零散的内存,仍旧会出现在各种不同大小的内存块持续的分配释放场景,将 PoolChunk 中的可用 Run 切分很零碎,内存碎片率逐渐提升最终导致 OOM。
05
AutoMQ 应对之道
前面介绍完 Netty 内存分配的机制和内存碎片产生的场景,那 AutoMQ 能怎么解决内存碎片问题的呢?
LogCache 针对追尾读持续访问新数据的特点,采用先入先出的缓存驱逐策略,换个角度思考就是在相邻时间分配内存的会在相邻时间释放。AutoMQ 采用的策略是抽象一个 ByteBufSeqAlloc:
-
ByteBufSeqAlloc 每次向 Netty 申请 ChunkSize 大小的 ByteBuf,避免产生外部内存碎片,做到零外部内存碎片;
-
ByteBufSeqAlloc分配内存时,通过底层 ByteBuf#retainSlice 紧挨着连续从底层大的内存拆分出小的内存,避免 size 规约化产生内部内存碎片,做到零内部内存碎片;
-
释放的时候是相邻的一起释放,有可能一块里面大部分都释放了,但其中少部分还在有效期内,这时候整个大块都无法释放,但这个大块的浪费有且仅会存在一个,并且也只会浪费一个 ChunkSize 的大小;
BlockCache 的特点是追求冷读高吞吐,会从对象存储中大块读取数据段。AutoMQ 采用的策略是大块缓存对象存储中的原始数据:
-
按需解码:等需要查询时,再解码成具体的 RecordBatch,通过降低常驻内存块的数量来降低内存碎片;
-
规整化拆分:未来可以将大块缓存规整化拆分成规整的 1MB 内存块,来避免各种不同大小的内存块持续的分配释放导致的内存碎片率逐渐提升;
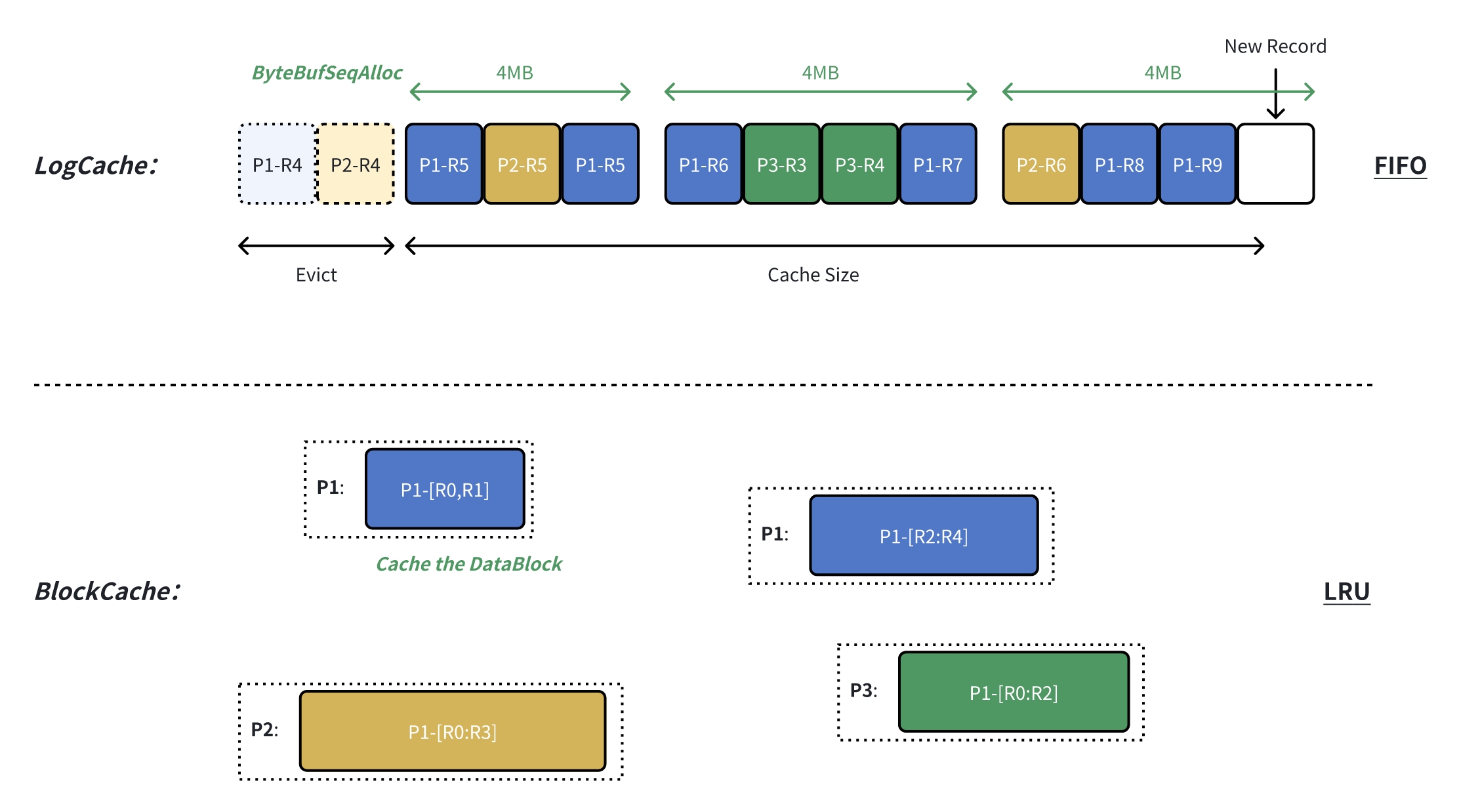
可以看到 LogCache 和 BlockCache 优化的本质都是根据自身缓存的特点通过大块 & 规整的内存分配来规避 Netty 内存分配策略带来的内存碎片问题。通过该方式,AutoMQ 在追尾读、冷读和大小消息等各种场景长期运行,也能将堆外内存的内存碎片率控制在 35% 以下,再也没有出现过堆外内存 OOM。
06
总结
Netty 的 PooledByteBufAllocator 不是银弹,使用的时候需要考虑内存碎片带来的实际内存占用的空间放大,规划预留出合理的 JVM 内存大小。如果只是使用 Netty 作为网络层框架,由 PooledByteBufAllocator 分配的内存生命周期会比较短,因此内存碎片引起的内存放大实际并不会很明显,不过仍旧建议使用 Netty 的系统都将版本升级到 4.1.52 之上,以获得更好的内存分配效率。如果使用 Netty 的 PooledByteBufAllocator 来做缓存,建议根据缓存的特征,使用大块内存分配然后再自行连续拆分,来规避 Netty 的内存碎片。
参考文档
-
https://netty.io/wiki/reference-counted-objects.html
-
https://netty.io/news/2020/09/08/4-1-52-Final.html
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
这篇关于基于Netty的自研流系统缓存实现挑战: 内存碎片与OOM困境的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
- 2024-12-23Fluss 写入数据湖实战
- 2024-12-22揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)
- 2024-12-20DevOps与平台工程的区别和联系
- 2024-12-20从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南
- 2024-12-20手把手教你轻松部署网站
- 2024-12-20服务器购买课程:新手入门全攻略
- 2024-12-20动态路由表学习:新手必读指南
- 2024-12-20服务器购买学习:新手指南与实操教程
- 2024-12-20动态路由表教程:新手入门指南
- 2024-12-20服务器购买教程:新手必读指南



